Clear Sky Science · ru
Очень энергоэффективная многопроцессорная нейроморфная архитектура для обучения глубоких спайковых нейронных сетей
Более умное обучение для устройств на периферии
Наши телефоны, камеры и мелкие датчики становятся умнее, но обучать их новым навыкам обычно приходится в энергоёмких дата‑центрах. В этой статье представлен новый тип чипа, вдохновлённого мозгом, который может обучаться прямо на небольших устройствах, потребляя значительно меньше энергии, чем современные графические процессоры. Цель — обеспечить гибкое, защищающее приватность обучение для автомобилей, дронов и других гаджетов, которые должны быстро реагировать без постоянной помощи облака.
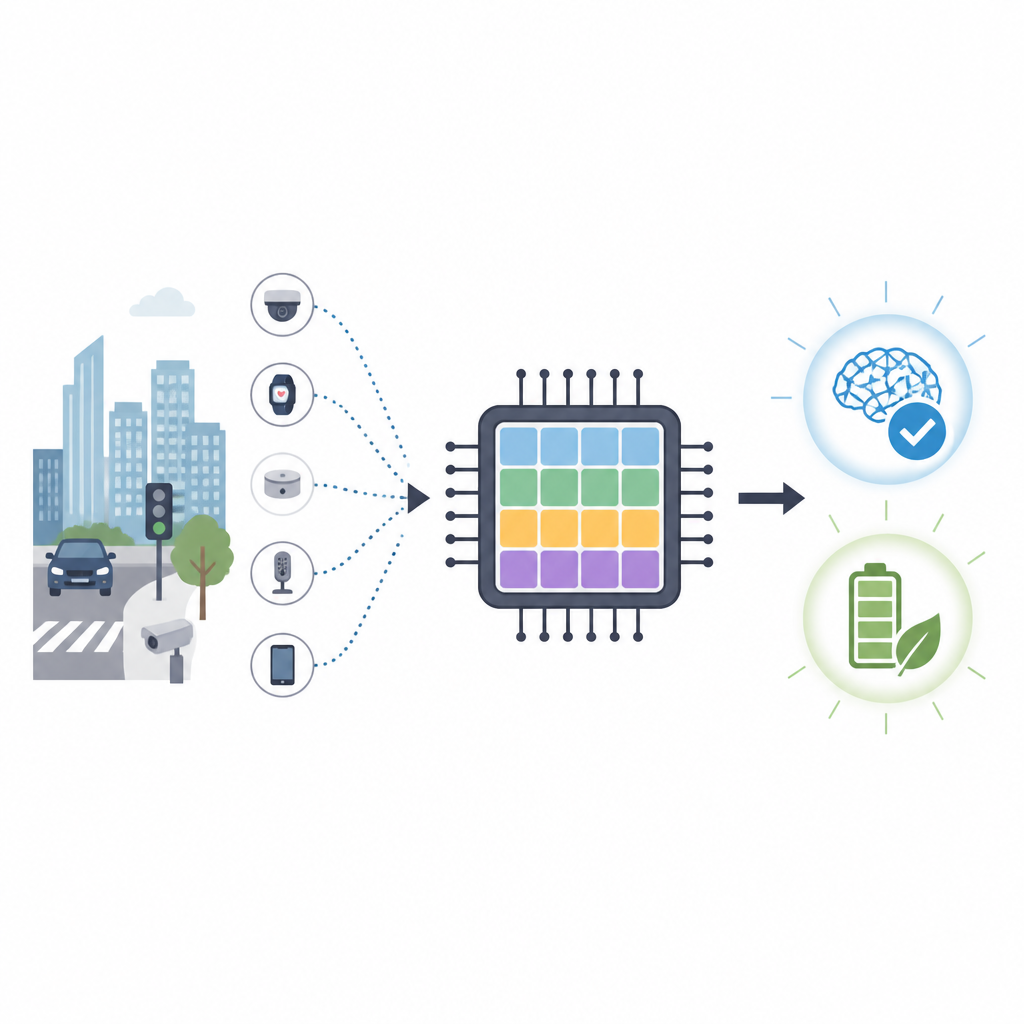
Почему важны чипы, подобные мозгу
Обычные чипы, такие как GPU, отлично справляются с вычислениями, но потребляют много энергии и зависят от быстрых связей с удалёнными серверами. Для задач вроде мониторинга дорожного движения или навигации дрона отправка сырых данных в облако занимает время и может раскрыть приватную информацию. Нейроморфные вычисления предлагают иной подход, имитируя обмен короткими электрическими импульсами в сетях нейронов. Спайковые нейронные сети обещают высокую точность при гораздо меньшем числе операций, что делает их привлекательными для энергоэффективных устройств на периферии сети.
Что недостаёт в спайковом оборудовании
Многие исследовательские чипы уже эффективно выполняют спайковые сети, но почти все они имеют важное ограничение: они хорошо работают с фиксированной обученной моделью, но не умеют эффективно обучать крупные глубокие спайковые сети. Большинство используют простые локальные правила обучения или передаёт тяжёлый итеративный процесс обучения на GPU. Это означает, что разработчики не могут полностью реализовать потенциальную экономию энергии во время обучения, и небольшим устройствам сложнее адаптироваться на ходу при изменяющихся условиях, например появлении новых дорожных знаков или изменении освещения.
Новый многопроцессорный дизайн для обучения на чипе
Авторы предлагают многопроцессорную нейроморфную архитектуру, в которой каждый процессор содержит три взаимодействующих блока: один обрабатывает сигналы, движущиеся вперёд по сети, второй передаёт информацию об ошибке назад, а третий обновляет веса связей. Эти ядра связаны в двумерную сетку, поэтому разные слои глубокой спайковой сети могут размещаться на разных ядрах и работать параллельно. Специально разработанная коммуникационная сеть передаёт как быстрые одноразрядные спайки, так и медленнее меняющиеся точные значения между ядрами в такт спайкам, а архитектура «память рядом с вычислением» хранит большую часть данных в самом чипе и сокращает дорогостоящие обращения к внешней памяти.
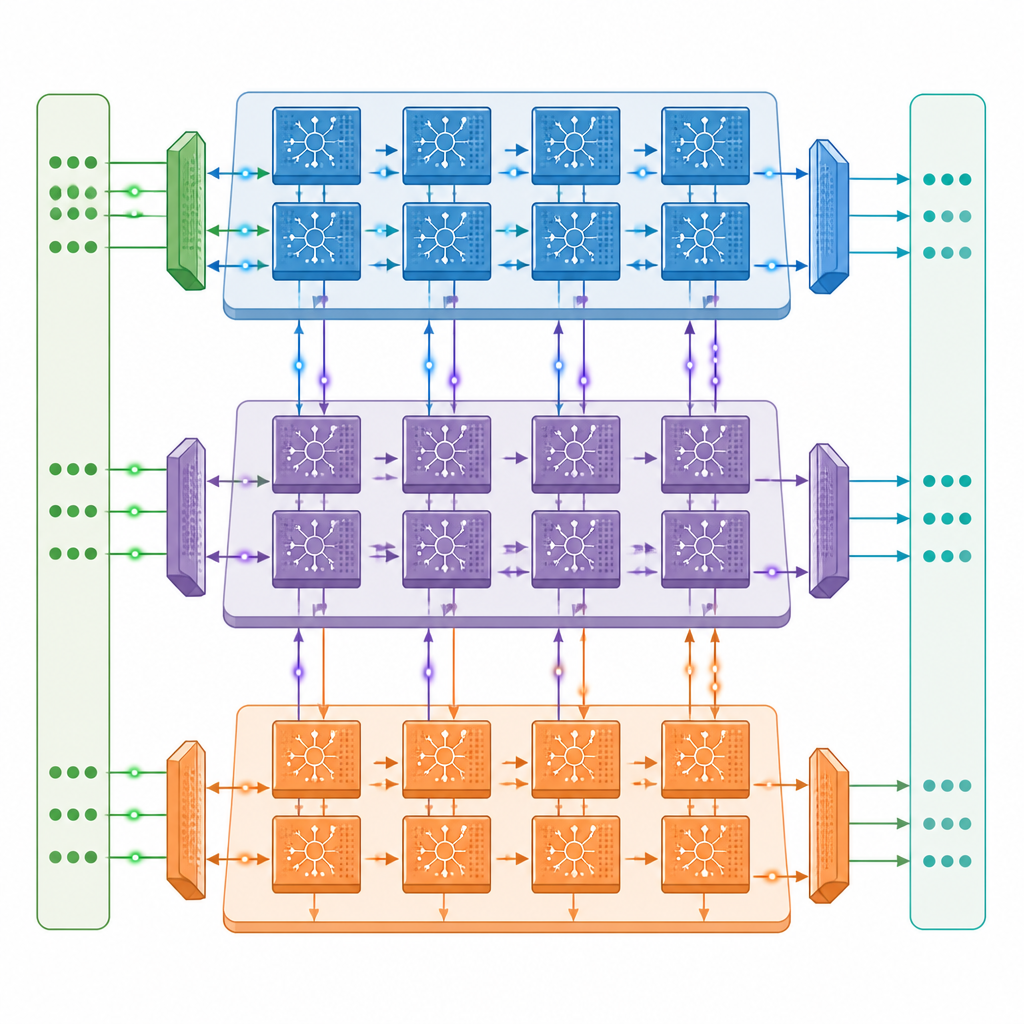
Больше возможностей при меньшем перемещении данных
Внутри каждого блока оборудование настроено на прерывистый характер спайковой активности. Схемы обнаруживают моменты, когда группы нейронов молчат, и пропускают ненужные вычисления и чтения памяти — стратегия, которая сокращает энергопотребление примерно вдвое при обучении на стандартных задачах распознавания изображений. Дизайн также повторно использует сохранённые данные и хранит спайки в виде одиночных битов, что значительно уменьшает потребность во внешней памяти. В тестах с популярными глубокими спайковыми версиями сетей ResNet и VGG прототип достигает примерно третьей части скорости обучения мощного дата‑центрового GPU A100, несмотря на то, что его сырая вычислительная мощность составляет только около одной двадцатой, и заметно превосходит периферийную систему Jetson Orin.
От лабораторного прототипа к реальному обучению на периферии
Чтобы показать работоспособность идеи за пределами симуляций, команда реализовала уменьшенную версию архитектуры на нескольких платах FPGA и обучала спайковые сети на стандартных наборах изображений и событий для жестов. Система справлялась с непрерывным обучением, когда модели обновляются по мере появления новых образцов, и с федеративным обучением, когда несколько устройств обучаются локально и обмениваются только компактными обновлениями. В обоих сценариях распределённая спайковая система улучшала точность, не централизуя сырые данные, что указывает на возможные приложения в умных городах и робототехнике, где множество устройств учатся совместно, сдерживая потребление энергии и пропускную способность.
Что это значит для повседневных технологий
Проще говоря, работа показывает, как построить тренировочный движок, похожий на мозг, который вписывается в строгие энергетические рамки периферийных устройств. Комбинируя множество небольших обучающих ядер, умную маршрутизацию данных и агрессивное пропускание ненужной работы, архитектура эффективно обучает глубокие спайковые сети без опоры на гигантские дата‑центры. Если такой дизайн воплотят в чипах, он может помочь камерам, автомобилям и бытовым устройствам учиться в реальном времени, сохраняя приватность и экономя энергию.
Цитирование: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
Ключевые слова: нейроморфные вычисления, спайковые нейронные сети, периферийный ИИ, низкопотребляющее оборудование, обучение на чипе