Clear Sky Science · he
ארכיטקטורה נוירומורפית רב-ליבתית יעילה אנרגטית לאימון רשתות נוירונים מתזמנות עמוקות
למידה חכמה יותר למכשירים בקצה
טלפונים, מצלמות וחיישנים קטנים נעשים חכמים יותר, אך ללמד אותם יכולות חדשות לרוב דורש מרכזי נתונים שצורכים הרבה חשמל. המאמר מציג סוג חדש של שבב בהשראת המוח שיכול ללמוד ישירות על מכשירים קטנים תוך שימוש באנרגיה נמוכה בהרבה ממעבדי גרפיקה עכשוויים. המטרה היא להביא למידה גמישה ושמירה על פרטיות לרכבים, רחפנים ומכשירים אחרים שצריכים להגיב במהירות ללא תלות רציפה בענן.
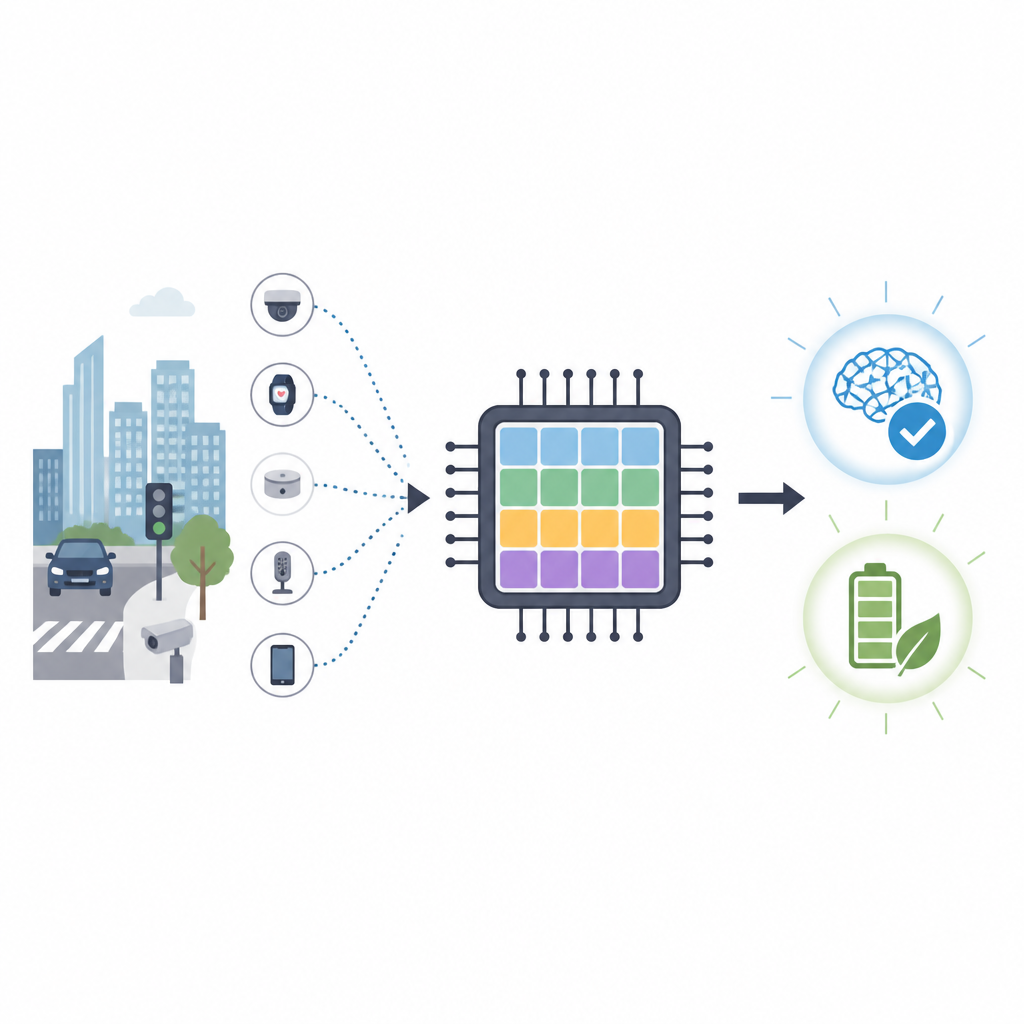
מדוע שבבים דמויי־מוח חשובים
שבבים קונבנציונליים כגון GPUs מצטיינים בחישובים כבדים, אך צורכים הרבה אנרגיה ותלויים בקישורים מהירים לשרתים מרוחקים. במשימות כמו ניטור תנועה או ניווט רחפנים, שליחה של נתונים גולמיים לענן איטית ועלולה לחשוף מידע פרטי. חישוב נוירומורפי נוקט בגישה שונה ומחקה את הדרך שבה רשתות של תאי מוח מחליפות דפיקות חשמליות קצרות. רשתות נוירונים מתזמנות מבטיחות דיוק גבוה עם הרבה פחות פעולות, מה שהופך אותן למושכות למכשירים בעלי צריכת־אנרגיה נמוכה הממוקמים בקצה הרשת.
החסרון ברכיבי חומרה מתזמניים
רבים משבבי המחקר כבר מפעילים רשתות מתזמנות ביעילות, אך כמעט כולם חולקים מגבלה מרכזית: הם טובים בהרצה של מודל מאומן קבוע, אך לא באימון רשתות מתזמנות עמוקות גדולות בעצמם. רובם מסתמכים על כללי למידה מקומיים פשוטים או מורידים את המשימה הכבדה של האימון חזרה וקדימה ל־GPUs. משמעות הדבר היא שמעבדים לא יכולים לנצל במלואן את חיסכון האנרגיה האפשרי בזמן למידה, וקשה יותר למכשירים קטנים להסתגל במהירות כאשר התנאים משתנים, למשל סימני תנועה חדשים או תנאי תאורה.
עיצוב רב־ליבתי חדש ללמידה על השבב
המחברים מציגים ארכיטקטורה נוירומורפית רב־ליבתית שבכל ליבה יש שלושה מנועים משתפי פעולה: מנוע שמטפל באותות זורמים קדימה ברשת, מנוע ששולח מידע שגיאה אחורה, ומנוע שעדכן את חוזק הקשרים. הליבות מחוברות ברשת דו־ממדית, כך ששכבות שונות של רשת מתזמנת עמוקה יכולות לשבת על ליבות שונות ולעבוד במקביל. רשת תקשורת מעוצבת בקפידה מעבירה גם דקיקות מהירות של ביט אחד וגם ערכים מדויקים ואיטיים יותר בין הליבות בהתאם לתזמון הדקירות, בעוד עיצוב זיכרון קרוב שומר את רוב הנתונים על השבב ומפחית גישות יקרות לזיכרון חיצוני.
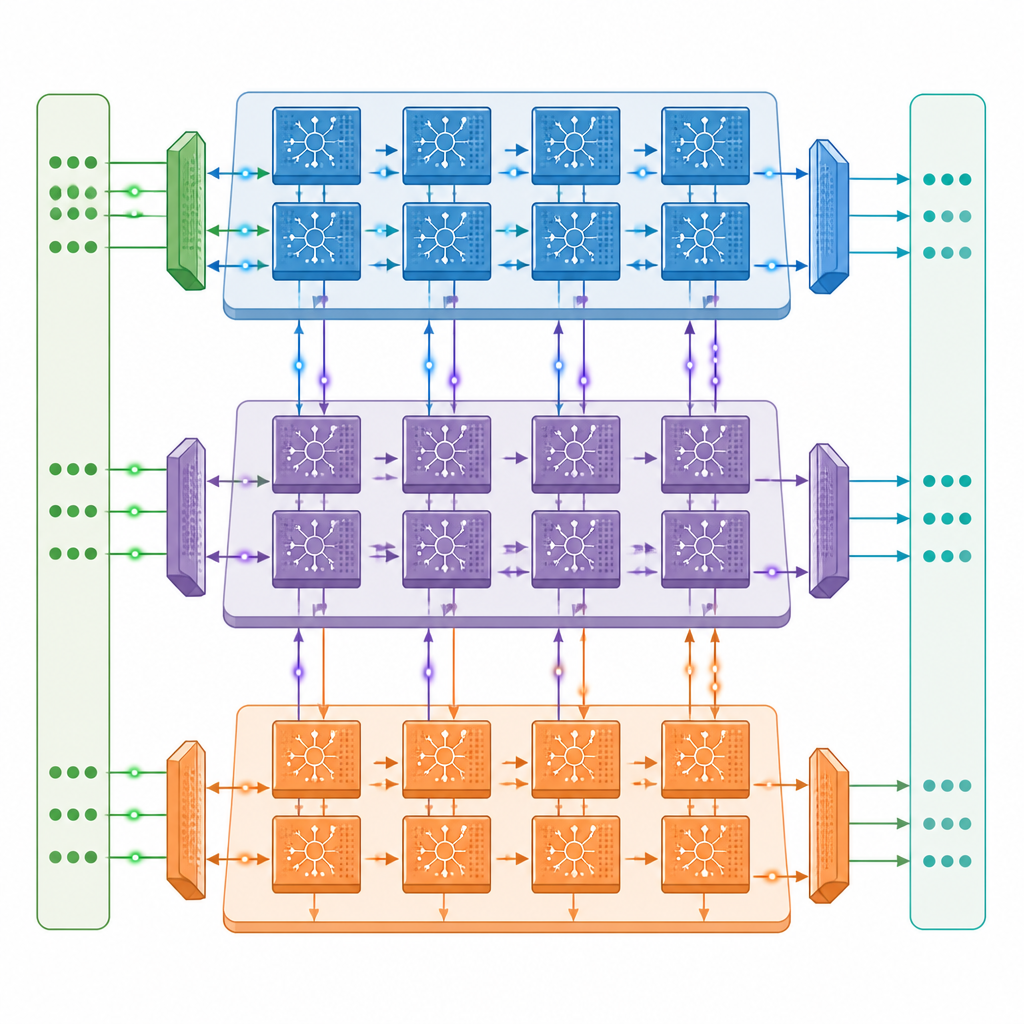
לעשות יותר עם פחות תזוזת נתונים
בתוך כל מנוע, החומרה מכוונת לאופי ה״עצור־התחל״ של פעילות הדקירות. מעגלים מזהים מתי קבוצות נוירונים שותקות ומדלגים על חישובים וקריאות זיכרון מיותרות, אסטרטגיה שמחציתה בערך את צריכת האנרגיה במהלך אימון על דגמי זיהוי תמונה סטנדרטיים. העיצוב גם משתמש מחדש בנתונים מאוחסנים היכן שאפשר ושומר דקירות כביטים בודדים, מה שמקטין משמעותית את הצורך בזיכרון חיצוני. במבחנים עם גרסאות מתזמנות עמוקות פופולריות של ResNet ו־VGG, האב־טיפוס מגיע למהירות אימון של עד כרבע־עד־שליש מזו של GPU מרכזי חזק מסוג A100, למרות שיש לו רק כחצי עד עשירית מהקיבולת הגולמית — והוא גם מפגין ביצועים טובים יותר ממערכת Edge כמו Jetson Orin.
מפרוטוטיפ במעבדה ללמידה בקצה אמיתית
כדי להראות שהרעיון עובד מעבר לסימולציות, הצוות מיפוי גרסה קטנה יותר של הארכיטקטורה על מספר לוחות FPGA ואימן רשתות מתזמנות על מערכי תמונה ותנועת מחוות סטנדרטיים. המערכת טיפלה בלמידה מתמשכת, שבה המודלים מתעדכנים כשהופיעו דוגמאות מסוגים חדשים, ובלמידה פדרטיבית, שבה מספר מכשירים מאמנים באופן מקומי ומשתפים רק עדכונים קומפקטיים. בשני המקרים, המערכת המתזמנת המבוזרת שיפרה את הדיוק מבלי לרכז נתונים גולמיים, מה שמעיד על יישומים עתידיים בעיר חכמה ורובוטיקה שבהם הרבה מכשירים לומדים ביחד תוך שמירה על צריכת אנרגיה ורוחב פס נמוכים.
מה משמעות הדבר לטכנולוגיה היומיומית
באופן פשוט, העבודה מראה כיצד לבנות מנוע אימון דמוי־מוח שמתאים למגבלות האנרגיה הקפדניות של מכשירי קצה. על ידי שילוב של ליבות למידה קטנות מרובות, ניתוב נתונים חכם ודילוג אגרסיבי על עבודה מיותרת, הארכיטקטורה מאמנת רשתות מתזמנות עמוקות ביעילות מבלי להישען על מרכזי נתונים ענקיים. אם יתורגמו לעיצובים שבביים, רעיונות כאלה יכולים לעזור למצלמות, רכבים ומכשירי בית ללמוד מהסביבה בזמן אמת תוך שמירה על פרטיות וחיסכון באנרגיה.
ציטוט: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
מילות מפתח: חישוב נוירומורפי, רשתות נוירונים מתזמנות, בינה קצה, חומרה צריכת־אנרגיה נמוכה, למידה על השבב