Clear Sky Science · en
A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks
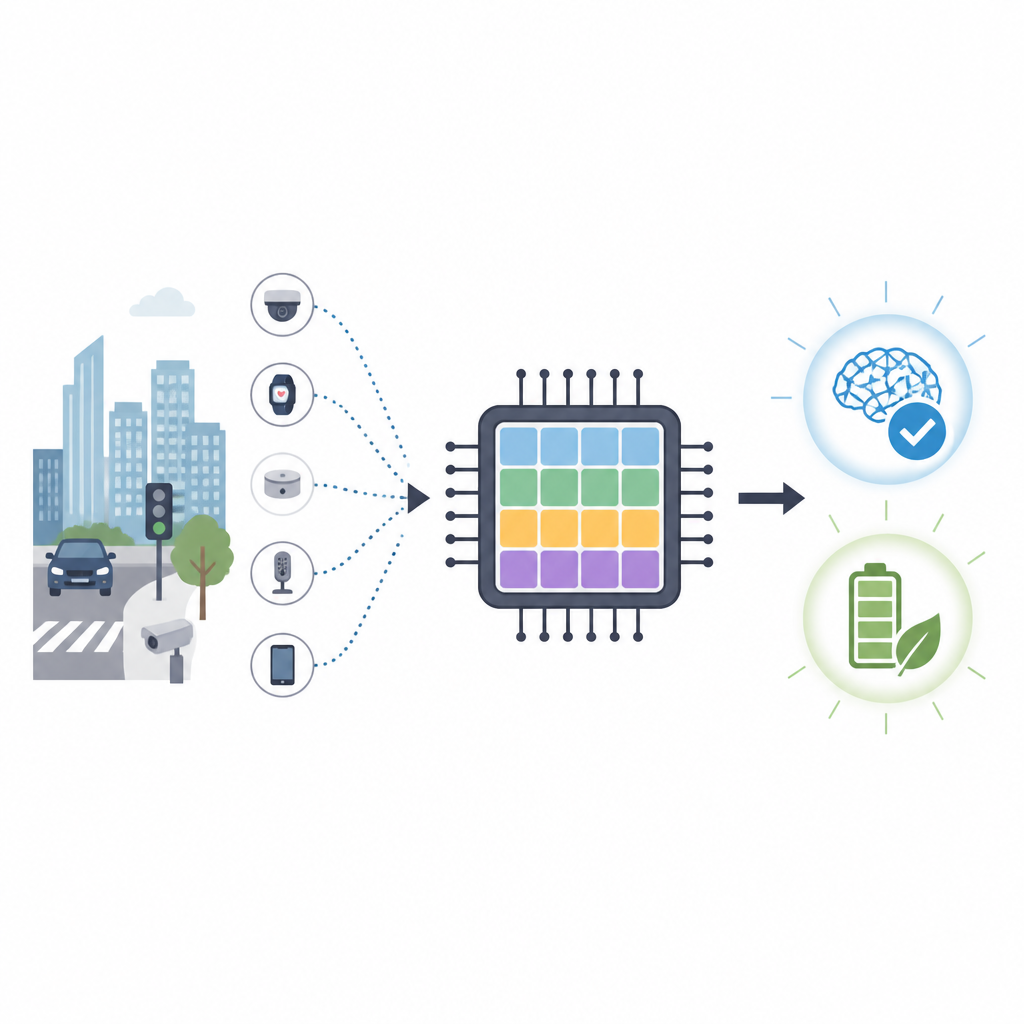
Smarter learning for gadgets at the edge
Our phones, cameras, and tiny sensors are getting smarter, but teaching them new tricks usually requires power hungry data centers. This paper presents a new kind of brain inspired computer chip that can learn directly on small devices while using far less energy than today’s graphics processors. It aims to bring flexible, privacy friendly learning to cars, drones, and other gadgets that must react quickly without constant help from the cloud.
Why brain like chips matter
Conventional chips such as GPUs are excellent at crunching numbers, but they burn a lot of energy and depend on fast links to distant servers. For tasks like traffic monitoring or drone navigation, sending raw data to the cloud is slow and can expose private information. Neuromorphic computing takes a different approach by imitating how networks of brain cells exchange short electrical spikes. Spiking neural networks promise high accuracy with far fewer operations, making them attractive for low power devices placed at the edge of the network.
The missing piece in spiking hardware
Many research chips already run spiking networks efficiently, yet almost all of them share a key limitation: they are good at using a fixed trained model, but not at training large deep spiking networks themselves. Most rely on simple local learning rules or offload the heavy back and forth training process to GPUs. That means designers cannot fully exploit the potential energy savings during learning, and it makes it harder for small devices to adapt on the fly when conditions change, such as new traffic signs or lighting conditions.
A new multi core design for on chip learning
The authors introduce a multi core neuromorphic architecture in which each core contains three cooperating engines: one that handles signals flowing forward through the network, one that sends error information backward, and one that updates the connection strengths. These cores are linked in a two dimensional grid, so different layers of a deep spiking network can sit on different cores and work in parallel. A carefully crafted communication network moves both fast one bit spikes and slower precise values between cores in step with the timing of the spikes, while a near memory design keeps most data on chip and reduces expensive trips to external memory.
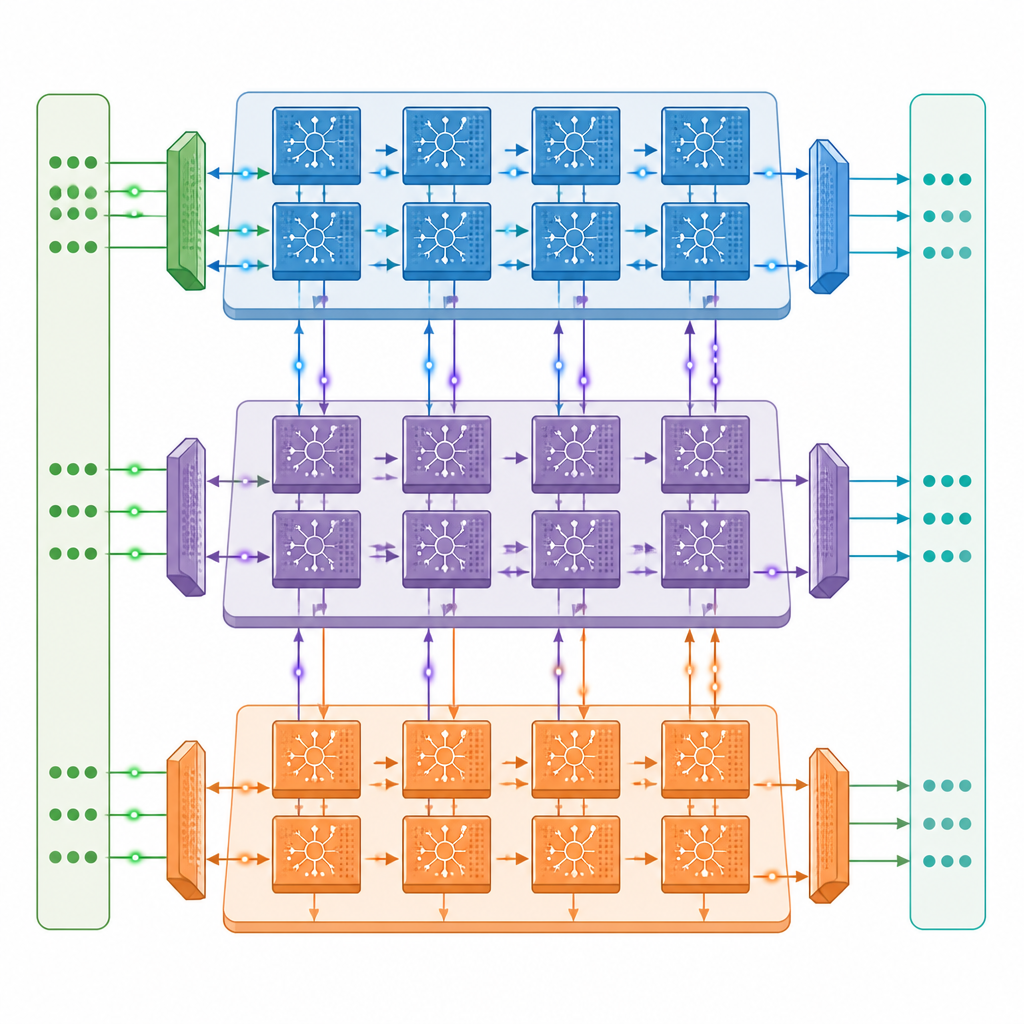
Doing more with less data movement
Inside each engine, the hardware is tuned to the stop start nature of spiking activity. Circuits detect when groups of neurons are silent and skip unnecessary calculations and memory reads, a strategy that cuts energy use by roughly half during training on standard image recognition models. The design also reuses stored data wherever possible and stores spikes as single bits, which greatly lowers the amount of external memory needed. In tests with popular deep spiking versions of ResNet and VGG networks, the prototype reaches up to about one third of the training speed of a powerful A100 data center GPU, despite having only around one twentieth of its raw compute capacity, and clearly outperforms a Jetson Orin edge system.
From lab prototype to real edge learning
To show that the idea works beyond simulations, the team mapped a smaller version of the architecture onto multiple FPGA boards and trained spiking networks on standard image and event based gesture datasets. The system handled continual learning, where models are updated as new kinds of samples appear, and federated learning, where several devices train locally and share only compact updates. In both cases, the distributed spiking system improved accuracy without centralizing raw data, hinting at future smart city and robotics applications where many devices learn together while keeping energy and bandwidth demands in check.
What this means for everyday technology
In simple terms, this work shows how to build a brain like training engine that fits the tight power budgets of edge devices. By combining many small learning cores, smart data routing, and aggressive skipping of needless work, the architecture trains deep spiking networks efficiently without leaning on giant data centers. If turned into chips, designs like this could help cameras, cars, and home gadgets learn from their surroundings in real time while preserving privacy and saving energy.
Citation: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
Keywords: neuromorphic computing, spiking neural networks, edge AI, low power hardware, on chip learning