Clear Sky Science · de
Eine hocheffiziente, mehrkernige neuromorphe Architektur zum Training tiefer spikender neuronaler Netze
Intelligenteres Lernen für Geräte am Rand des Netzes
Unsere Telefone, Kameras und kleinen Sensoren werden immer schlauer, doch das Antrainieren neuer Fähigkeiten erfordert meist energieintensive Rechenzentren. Dieses Paper stellt eine neue, vom Gehirn inspirierte Computerchip-Architektur vor, die direkt auf kleinen Geräten lernen kann und dabei deutlich weniger Energie verbraucht als heutige Grafikprozessoren. Das Ziel ist, flexibles, datenschutzfreundliches Lernen in Autos, Drohnen und anderen Geräten zu ermöglichen, die schnell reagieren müssen, ohne ständig auf die Cloud angewiesen zu sein.
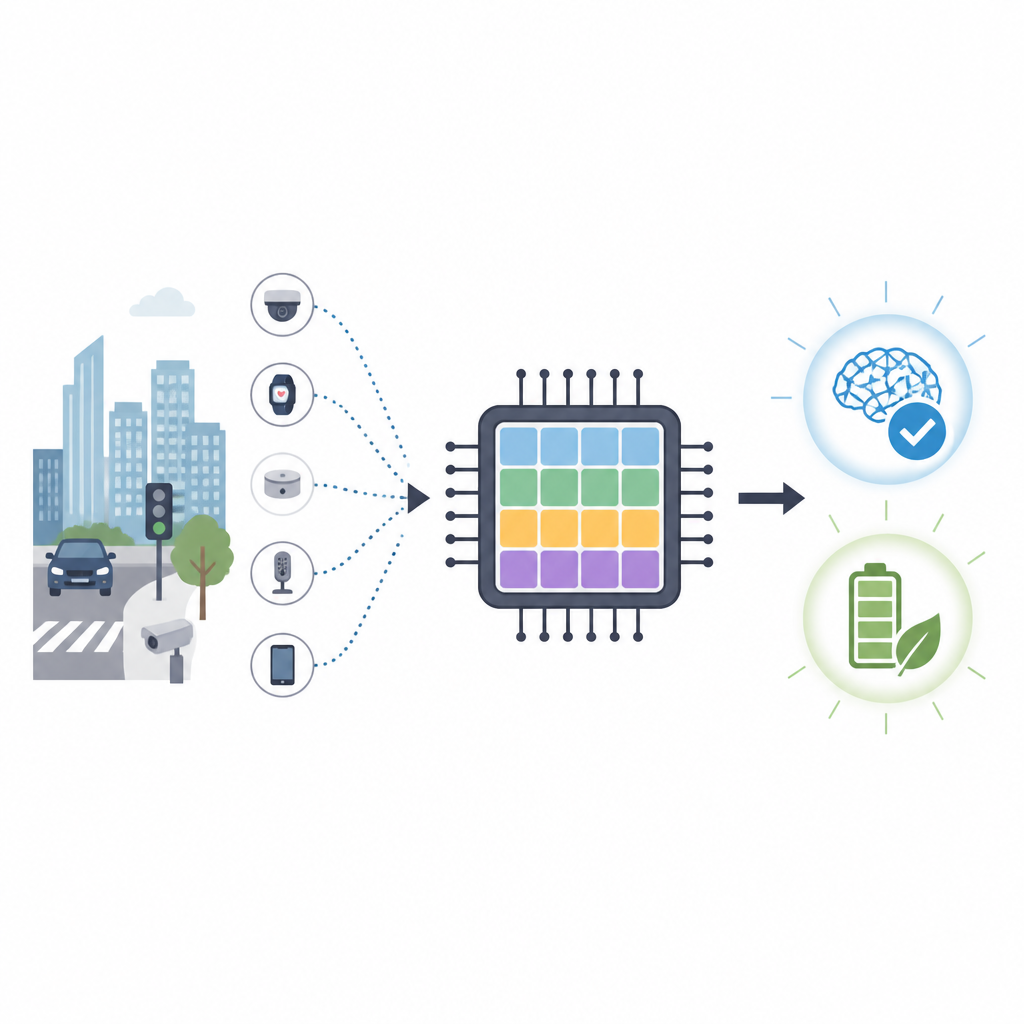
Warum gehirnähnliche Chips wichtig sind
Konventionelle Chips wie GPUs sind hervorragend im Rechnen, verbrauchen aber viel Energie und sind auf schnelle Verbindungen zu entfernten Servern angewiesen. Für Aufgaben wie Verkehrsüberwachung oder Drohnen-Navigation ist das Senden roher Daten in die Cloud langsam und kann private Informationen offenlegen. Neuromorphe Rechner verfolgen einen anderen Ansatz, indem sie nachahmen, wie Netzwerke von Nervenzellen kurze elektrische Spike-Signale austauschen. Spikende neuronale Netze versprechen hohe Genauigkeit bei deutlich weniger Operationen, was sie attraktiv für stromsparende Geräte am Netzwerkrand macht.
Das fehlende Stück in spikender Hardware
Viele Forschungschips führen bereits spikende Netze effizient aus, doch fast alle teilen eine wesentliche Einschränkung: Sie eignen sich gut zur Nutzung eines fixierten, bereits trainierten Modells, sind aber kaum in der Lage, selbst große, tiefe spikende Netze zu trainieren. Die meisten stützen sich auf einfache lokale Lernregeln oder lagern den aufwändigen bidirektionalen Trainingsprozess an GPUs aus. Das verhindert, dass Designer die potenziellen Energieeinsparungen beim Lernen voll ausschöpfen, und erschwert es kleinen Geräten, sich in Echtzeit an veränderte Bedingungen anzupassen, etwa neue Verkehrszeichen oder Lichtverhältnisse.
Ein neues Mehrkern-Design für On-Chip-Lernen
Die Autoren stellen eine mehrkernige neuromorphe Architektur vor, in der jeder Kern drei zusammenarbeitende Einheiten enthält: eine für die vorwärts fließenden Signale im Netz, eine für die rückwärts gesendeten Fehlersignale und eine zur Aktualisierung der Verbindungsstärken. Diese Kerne sind in einem zweidimensionalen Gitter verbunden, sodass verschiedene Schichten eines tiefen spikenden Netzes auf unterschiedlichen Kernen sitzen und parallel arbeiten können. Ein sorgfältig gestaltetes Kommunikationsnetzwerk überträgt sowohl schnelle Ein-Bit-Spikes als auch langsamere, präzise Werte zwischen den Kernen synchron zur Spike-Timing, während ein Near-Memory-Design die meisten Daten auf dem Chip hält und teure Zugriffe auf externen Speicher reduziert.
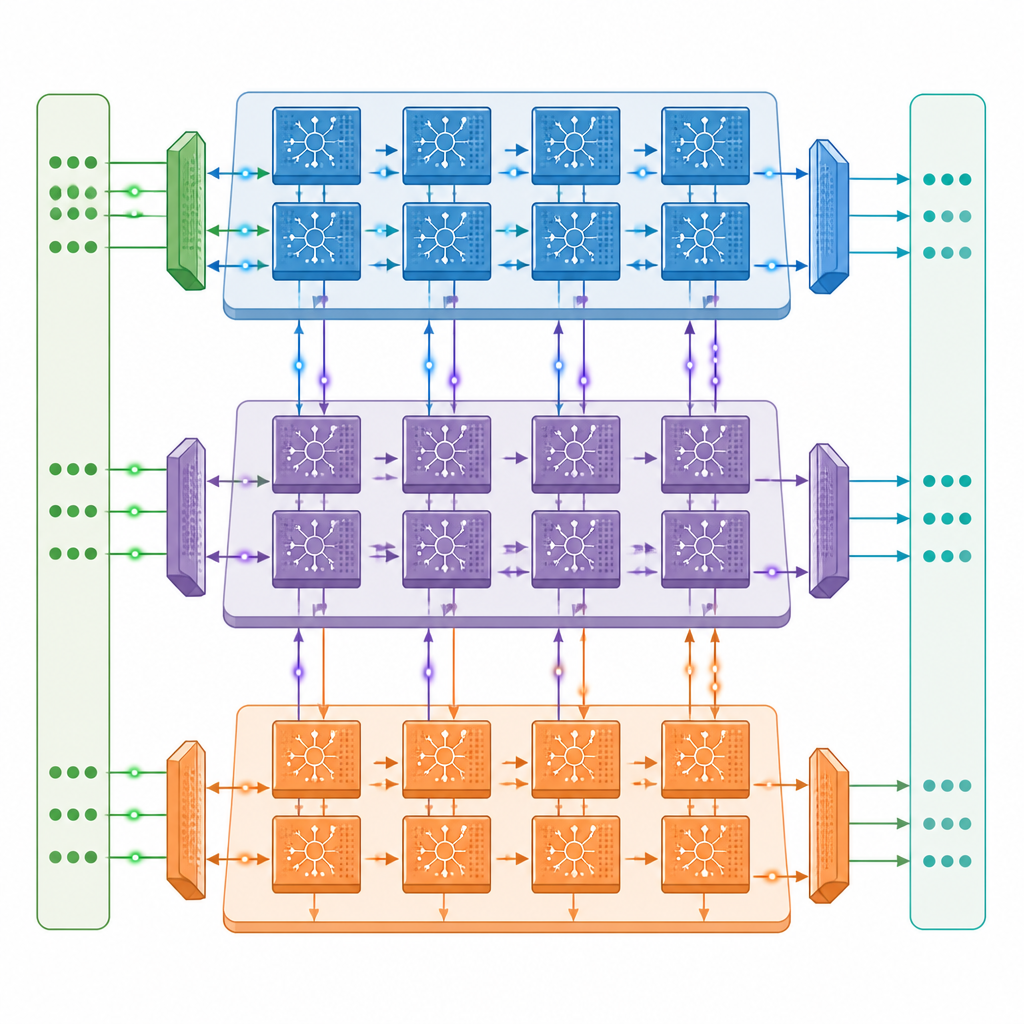
Mehr erreichen bei weniger Datenbewegung
Innerhalb jeder Einheit ist die Hardware auf das Stop-and-Go-Verhalten spikender Aktivität abgestimmt. Schaltungen erkennen, wenn Gruppen von Neuronen still sind, und überspringen unnötige Berechnungen und Speicherzugriffe—eine Strategie, die den Energieverbrauch beim Training auf gängigen Bildklassifikationsmodellen etwa halbiert. Das Design nutzt gespeicherte Daten wieder, wo immer möglich, und speichert Spikes als einzelne Bits, was den Bedarf an externem Speicher stark reduziert. In Tests mit populären tiefen spikenden Varianten von ResNet- und VGG-Netzen erreicht der Prototyp trotz nur etwa einem Zwanzigstel der rohen Rechenkapazität bis zu rund ein Drittel der Trainingsgeschwindigkeit einer leistungsstarken A100-Rechenzentrums-GPU und übertrifft deutlich ein Jetson-Orin-Edge-System.
Vom Laborprototyp zum echten Edge-Lernen
Um zu zeigen, dass die Idee über Simulationen hinaus funktioniert, haben die Autoren eine kleinere Version der Architektur auf mehrere FPGA-Boards abgebildet und spikende Netze mit Standard-Bild- und ereignisbasierten Gestendatensätzen trainiert. Das System bewältigte kontinuierliches Lernen, bei dem Modelle aktualisiert werden, sobald neue Arten von Proben auftauchen, sowie föderiertes Lernen, bei dem mehrere Geräte lokal trainieren und nur kompakte Updates austauschen. In beiden Fällen verbesserte das verteilte spikende System die Genauigkeit, ohne Rohdaten zu zentralisieren, und deutet auf künftige Anwendungen in Smart Cities und Robotik hin, in denen viele Geräte gemeinsam lernen bei gleichzeitiger Begrenzung von Energie- und Bandbreitenbedarf.
Was das für die Alltagstechnik bedeutet
Einfach ausgedrückt zeigt diese Arbeit, wie sich eine gehirnähnliche Trainingsmaschine bauen lässt, die in die engen Leistungsbudgets von Edge-Geräten passt. Durch die Kombination vieler kleiner Lernkerne, intelligenter Datenweiterleitung und aggressivem Überspringen unnötiger Arbeit trainiert die Architektur tiefe spikende Netze effizient, ohne auf riesige Rechenzentren angewiesen zu sein. Würden solche Entwürfe in Chips umgesetzt, könnten Kameras, Autos und Haushaltsgeräte aus ihrer Umgebung in Echtzeit lernen, dabei Energie sparen und die Privatsphäre wahren.
Zitation: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
Schlüsselwörter: neuromorphe Computertechnik, spikende neuronale Netze, Edge-AI, stromsparende Hardware, On-Chip-Lernen