Clear Sky Science · ja
深いスパイキングニューラルネットワークを学習させるための高エネルギー効率マルチコアニューロモルフィックアーキテクチャ
エッジ機器のためのより賢い学習
私たちのスマートフォン、カメラ、小型センサーは賢くなっていますが、新しい能力を教えるには通常、電力を大量に消費するデータセンターが必要です。本論文は、小型デバイス上で直接学習でき、現在のグラフィックスプロセッサよりもはるかに少ないエネルギーで動作する脳に着想を得た新しいタイプのコンピュータチップを示します。これにより、自動車やドローンなど、クラウドの常時支援を必要とせず迅速に反応しなければならない機器に対して、柔軟でプライバシーに配慮した学習をもたらすことを目指します。
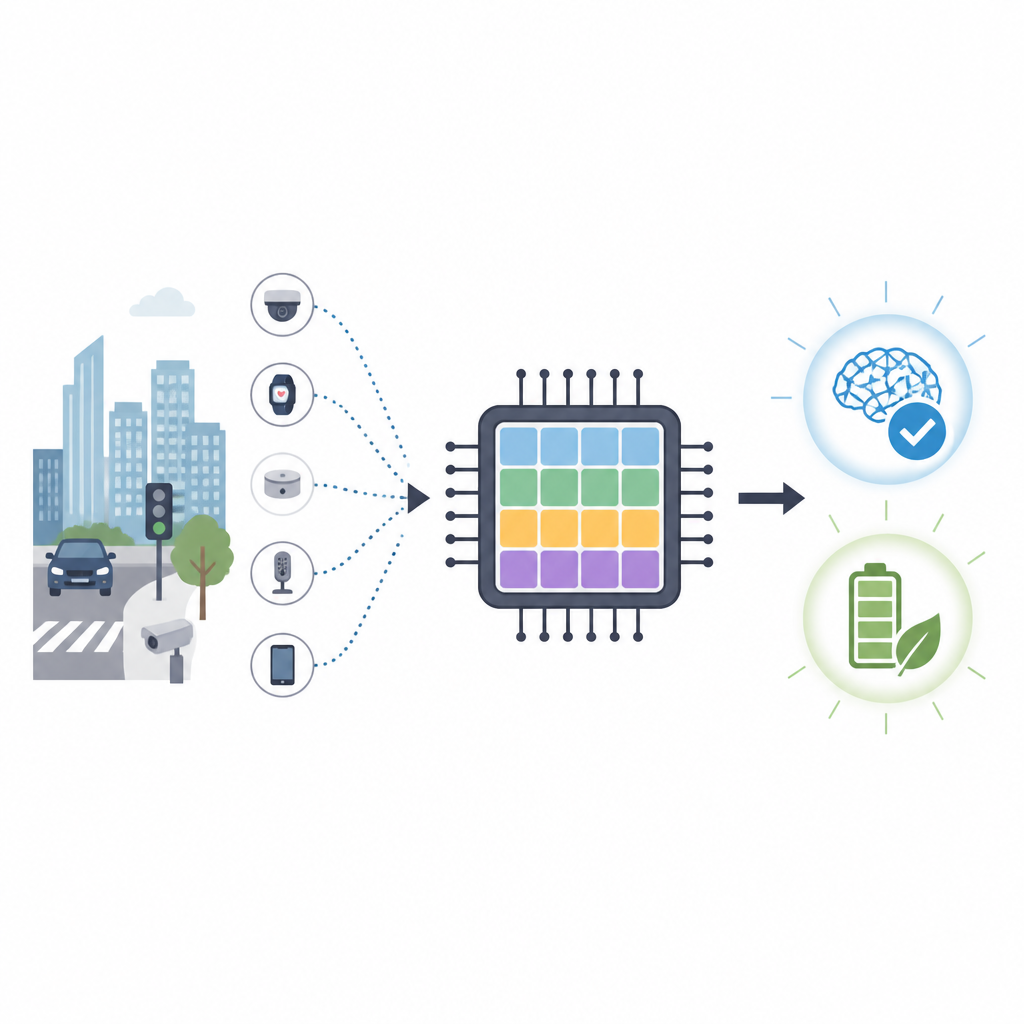
なぜ脳に似たチップが重要か
従来のチップ、たとえばGPUは数値計算に優れていますが、大量のエネルギーを消費し、遠隔サーバーへの高速な接続に依存します。交通監視やドローンの航行のようなタスクでは、生データをクラウドへ送るのは遅く、プライバシーのリスクも高まります。ニューロモルフィックコンピューティングは脳細胞ネットワークが短い電気スパイクを交換する仕組みを模倣することで異なるアプローチを取ります。スパイキングニューラルネットワークははるかに少ない演算で高精度を実現する可能性があり、ネットワークのエッジに置かれる低消費電力デバイスにとって魅力的です。
スパイキングハードウェアの欠けている要素
多くの研究用チップはすでにスパイキングネットワークを効率的に実行しますが、ほとんどすべてに共通する重要な制約があります。つまり、既に訓練された固定モデルを使うのは得意でも、大規模な深いスパイキングネットワーク自体を学習させるのは不得手です。多くは単純な局所学習則に頼るか、重い訓練処理をGPUにオフロードします。そのため、学習中の潜在的なエネルギー節約を十分に活用できず、新しい交通標識や照明条件など環境が変化した際に小型デバイスが即座に適応するのが難しくなります。
オンチップ学習のための新しいマルチコア設計
著者らは、各コアが3つの協調するエンジンを内蔵するマルチコアニューロモルフィックアーキテクチャを導入します:ネットワークを通して信号を前方に伝えるエンジン、誤差信号を後方に伝えるエンジン、そして結合強度を更新するエンジンです。これらのコアは2次元グリッドで接続されており、深いスパイキングネットワークの異なる層を別々のコアに配置して並列に動作させることが可能です。巧妙に設計された通信ネットワークは、高速の1ビットスパイクとより遅い精密な値の両方をスパイクのタイミングに合わせてコア間で移動させ、近接メモリ設計によりほとんどのデータをオンチップに保持して外部メモリへの高コストなアクセスを減らします。
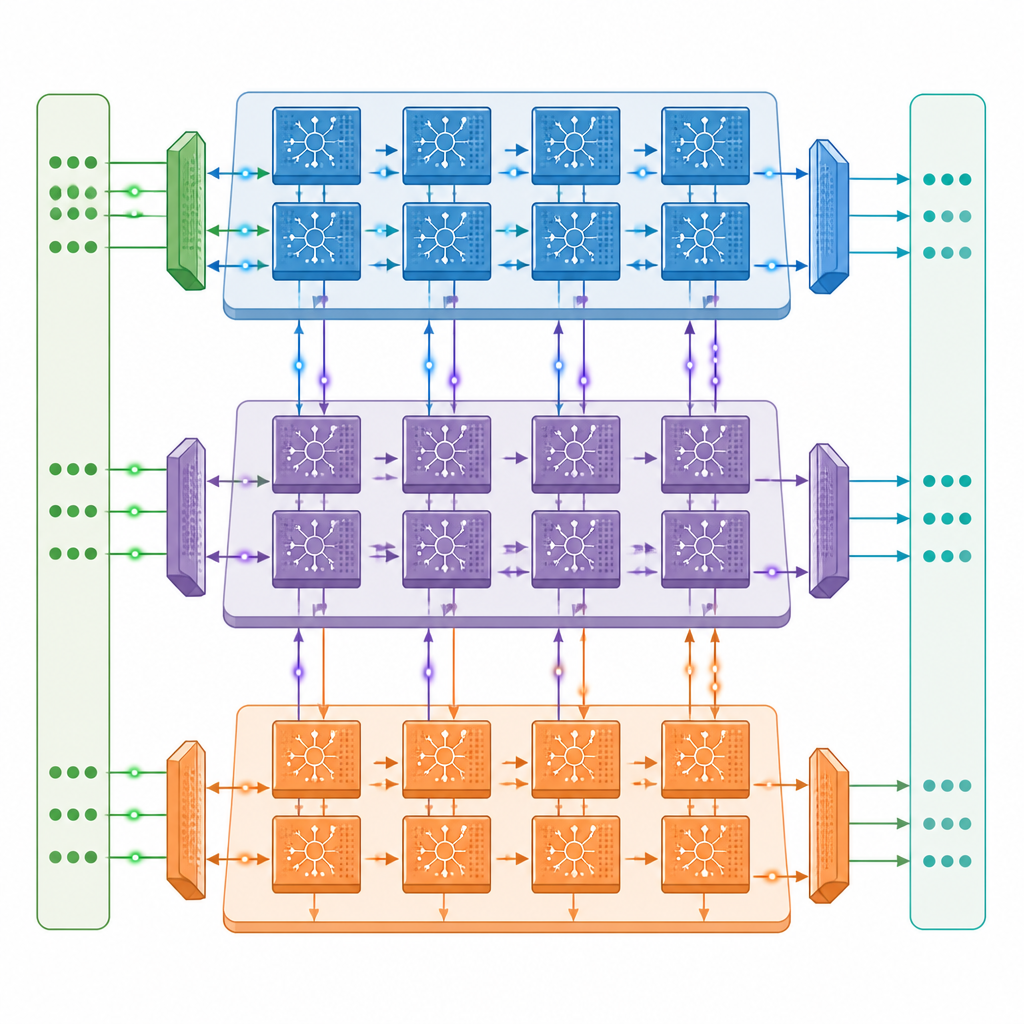
データ移動を抑えてより多くを行う
各エンジン内部では、ハードウェアがスパイキング活動の停止・開始という性質に合わせて調整されています。回路は複数のニューロン群が沈黙している時を検出し、不必要な計算やメモリ読み出しをスキップします。この戦略により、標準的な画像認識モデルの学習時に消費エネルギーを約半分に削減できます。設計はまた、保存データの再利用を最大限に行い、スパイクを1ビットで表現することで外部メモリの必要量を大幅に低減します。ResNetやVGGの深いスパイキング版でのテストでは、プロトタイプは強力なA100データセンターGPUの学習速度のおよそ3分の1程度に達しており、生の演算能力は約20分の1しかないにもかかわらず、Jetson Orinのようなエッジシステムを明確に上回っています。
実験室の試作から実際のエッジ学習へ
アイデアがシミュレーションを超えて機能することを示すため、チームはアーキテクチャの小型版を複数のFPGAボードにマップし、標準的な画像およびイベントベースのジェスチャーデータセットでスパイキングネットワークを学習させました。システムは、新しい種類のサンプルが現れるたびにモデルを更新する継続学習や、複数のデバイスがローカルで学習しコンパクトな更新のみを共有するフェデレーテッドラーニングを扱いました。いずれの場合も、分散スパイキングシステムは生データを集中させることなく精度を改善し、多くのデバイスが協調して学習しつつエネルギーと帯域幅の要求を抑える将来のスマートシティやロボティクスへの応用を示唆しました。
日常技術にもたらすもの
簡単に言えば、本研究はエッジデバイスの厳しい電力予算に収まるような脳に似た学習エンジンの構築方法を示しています。多数の小さな学習コア、スマートなデータルーティング、不要な作業の徹底的なスキップを組み合わせることで、このアーキテクチャは巨大なデータセンターに依存することなく深いスパイキングネットワークを効率的に学習させます。チップとして実装されれば、カメラ、車、家庭用機器が周囲からリアルタイムで学習し、プライバシーを保護しながらエネルギーを節約するのに役立つ可能性があります。
引用: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
キーワード: ニューロモルフィックコンピューティング, スパイキングニューラルネットワーク, エッジAI, 低消費電力ハードウェア, オンチップ学習