Clear Sky Science · fr
Une architecture neuromorphique multicœur très économe en énergie pour l’apprentissage de réseaux de neurones à impulsions profonds
Un apprentissage plus intelligent pour les appareils en périphérie
Nos téléphones, caméras et petits capteurs deviennent plus intelligents, mais leur apprendre de nouvelles compétences nécessite généralement des centres de données énergivores. Cet article présente un nouveau type de puce inspirée du cerveau capable d’apprendre directement sur de petits appareils tout en consommant beaucoup moins d’énergie que les processeurs graphiques actuels. L’objectif est d’apporter un apprentissage flexible et respectueux de la vie privée aux voitures, drones et autres appareils qui doivent réagir rapidement sans dépendre en permanence du cloud.
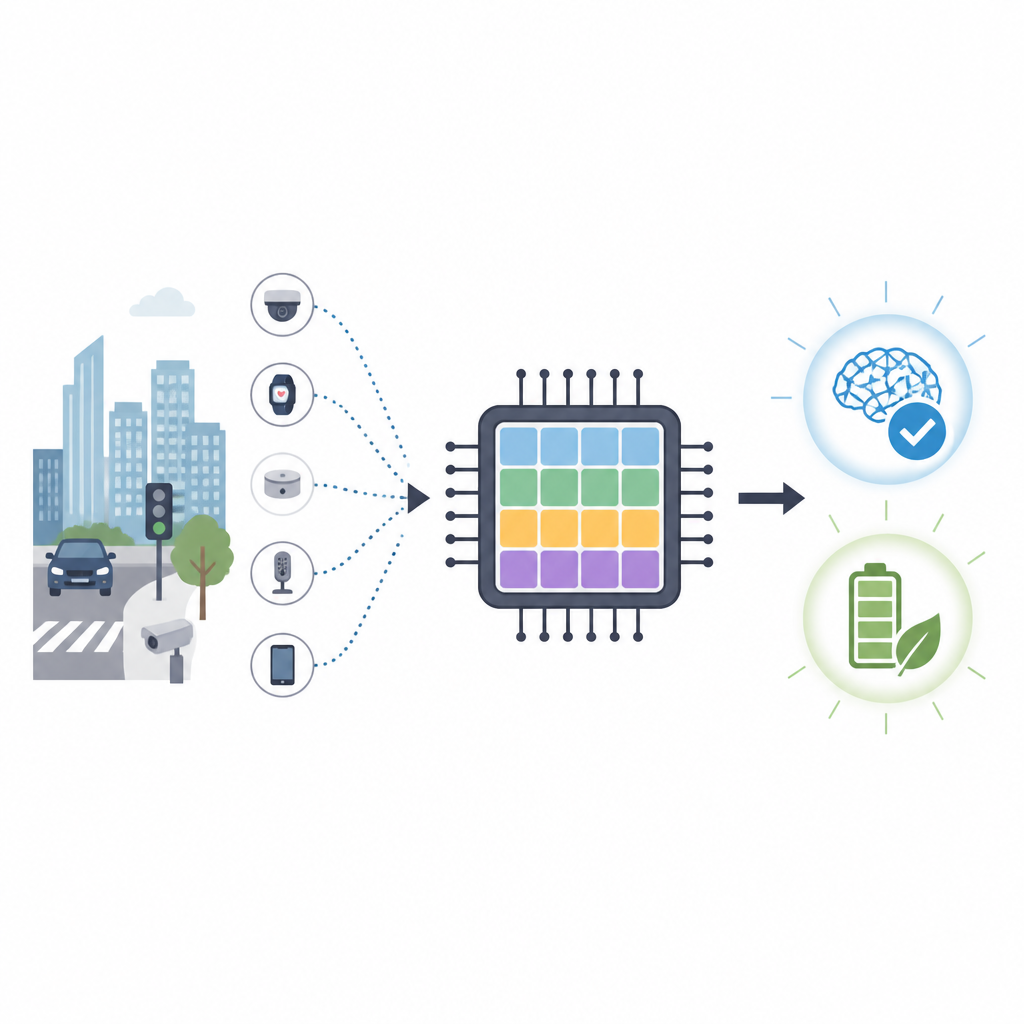
Pourquoi les puces de type cérébral comptent
Les puces conventionnelles comme les GPU excellent pour traiter des calculs, mais elles consomment beaucoup d’énergie et dépendent de liens rapides vers des serveurs distants. Pour des tâches telles que la surveillance du trafic ou la navigation de drones, envoyer des données brutes vers le cloud est lent et peut exposer des informations privées. L’informatique neuromorphique adopte une approche différente en imitant la façon dont les réseaux de cellules cérébrales échangent de courtes impulsions électriques. Les réseaux de neurones à impulsions promettent une grande précision avec beaucoup moins d’opérations, ce qui les rend attrayants pour des dispositifs à faible consommation situés en périphérie du réseau.
La pièce manquante dans le matériel à impulsions
Beaucoup de puces de recherche exécutent déjà des réseaux à impulsions de manière efficace, mais presque toutes partagent une limitation majeure : elles savent bien exploiter un modèle entraîné fixe, mais pas entraîner elles-mêmes de grands réseaux à impulsions profonds. La plupart s’appuient sur des règles d’apprentissage locales simples ou externalisent le processus d’entraînement intensif vers des GPU. Cela empêche les concepteurs d’exploiter pleinement les économies d’énergie potentielles pendant l’apprentissage et rend plus difficile l’adaptation en temps réel des petits appareils lorsque les conditions changent, par exemple l’apparition de nouveaux panneaux de signalisation ou des variations d’éclairage.
Une nouvelle conception multicœur pour l’apprentissage sur puce
Les auteurs présentent une architecture neuromorphique multicœur dans laquelle chaque cœur contient trois moteurs coopérants : un qui gère les signaux circulant vers l’avant dans le réseau, un qui envoie les informations d’erreur vers l’arrière, et un qui met à jour les forces de connexion. Ces cœurs sont reliés en une grille bidimensionnelle, de sorte que différentes couches d’un réseau à impulsions profond peuvent être réparties sur différents cœurs et fonctionner en parallèle. Un réseau de communication soigneusement conçu transporte à la fois des impulsions rapides d’un bit et des valeurs plus lentes et précises entre les cœurs, synchronisées avec le timing des impulsions, tandis qu’une conception « near memory » conserve la majorité des données sur la puce et réduit les allers-retours coûteux vers la mémoire externe.
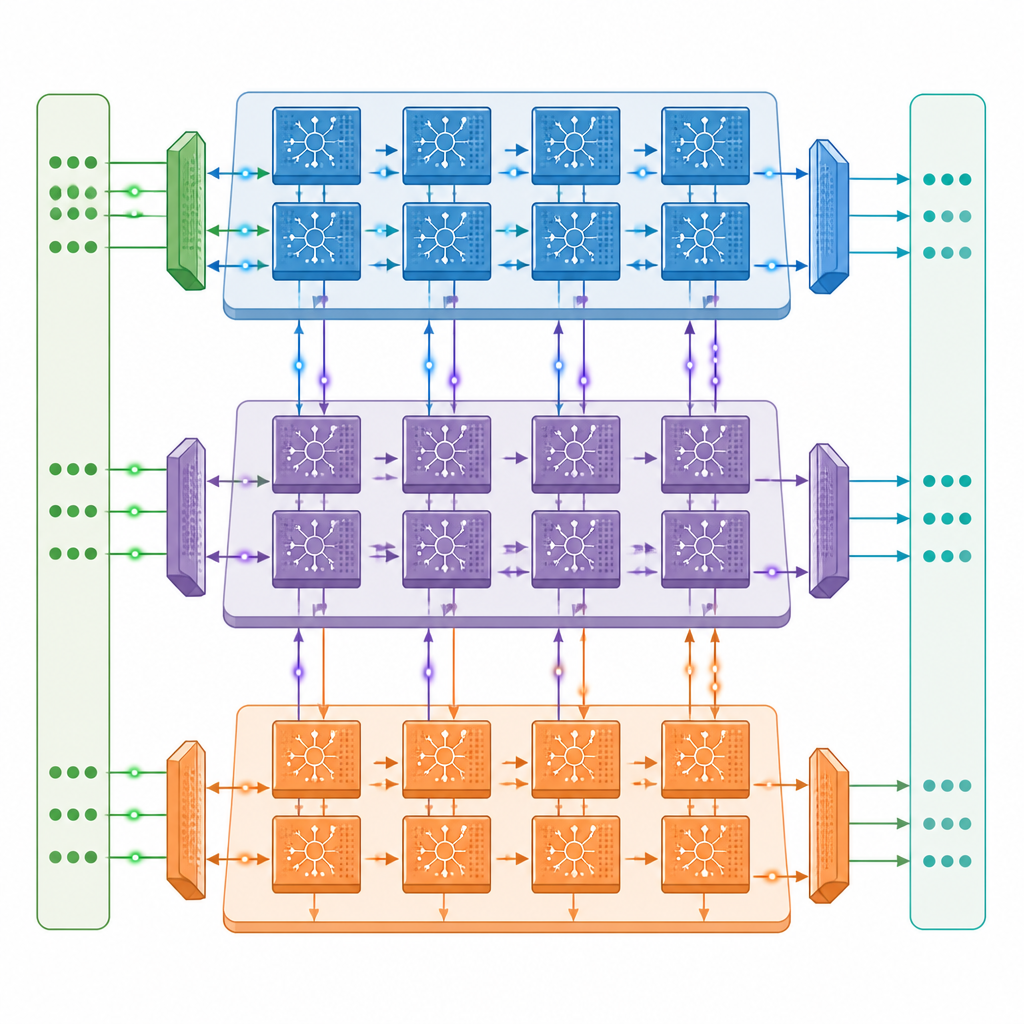
Faire plus avec moins de transfert de données
À l’intérieur de chaque moteur, le matériel est adapté à la nature intermittente de l’activité à impulsions. Les circuits détectent lorsque des groupes de neurones sont silencieux et évitent les calculs et lectures mémoire inutiles, une stratégie qui réduit la consommation d’énergie d’environ moitié lors de l’entraînement sur des modèles standard de reconnaissance d’images. La conception réutilise également les données stockées autant que possible et enregistre les impulsions sous forme de bits uniques, ce qui réduit fortement la quantité de mémoire externe nécessaire. Dans des tests sur des versions à impulsions populaires des réseaux ResNet et VGG, le prototype atteint jusqu’à environ un tiers de la vitesse d’entraînement d’un puissant GPU A100 de centre de données, malgré une capacité de calcul brute d’environ un vingtième, et surpasse nettement un système d’edge Jetson Orin.
Du prototype de laboratoire à l’apprentissage réel en périphérie
Pour montrer que l’idée fonctionne au‑delà des simulations, l’équipe a mappé une version réduite de l’architecture sur plusieurs cartes FPGA et entraîné des réseaux à impulsions sur des ensembles de données standard d’images et de gestes basés sur des événements. Le système a géré l’apprentissage continu, où les modèles sont mis à jour au fur et à mesure que de nouveaux types d’exemples apparaissent, ainsi que l’apprentissage fédéré, où plusieurs appareils s’entraînent localement et ne partagent que des mises à jour compactes. Dans les deux cas, le système réparti à impulsions a amélioré la précision sans centraliser les données brutes, suggérant des applications futures pour les villes intelligentes et la robotique où de nombreux appareils apprennent ensemble tout en maîtrisant la consommation d’énergie et la bande passante.
Ce que cela signifie pour la technologie quotidienne
Concrètement, ce travail montre comment construire un moteur d’entraînement de type cérébral qui tient dans les contraintes énergétiques strictes des dispositifs en périphérie. En combinant de nombreux petits cœurs d’apprentissage, un routage de données intelligent et l’élimination agressive des travaux inutiles, l’architecture entraîne efficacement des réseaux à impulsions profonds sans s’appuyer sur d’immenses centres de données. Si elle était industrialisée en puces, une telle conception pourrait aider caméras, voitures et appareils domestiques à apprendre de leur environnement en temps réel tout en préservant la vie privée et en économisant de l’énergie.
Citation: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
Mots-clés: informatique neuromorphique, réseaux de neurones à impulsions, IA en périphérie, matériel basse consommation, apprentissage sur puce