Clear Sky Science · sv
En mycket energieffektiv flerkärnig neuromorf arkitektur för träning av djupa spikande neurala nätverk
Smartare inlärning för enheter i kanten
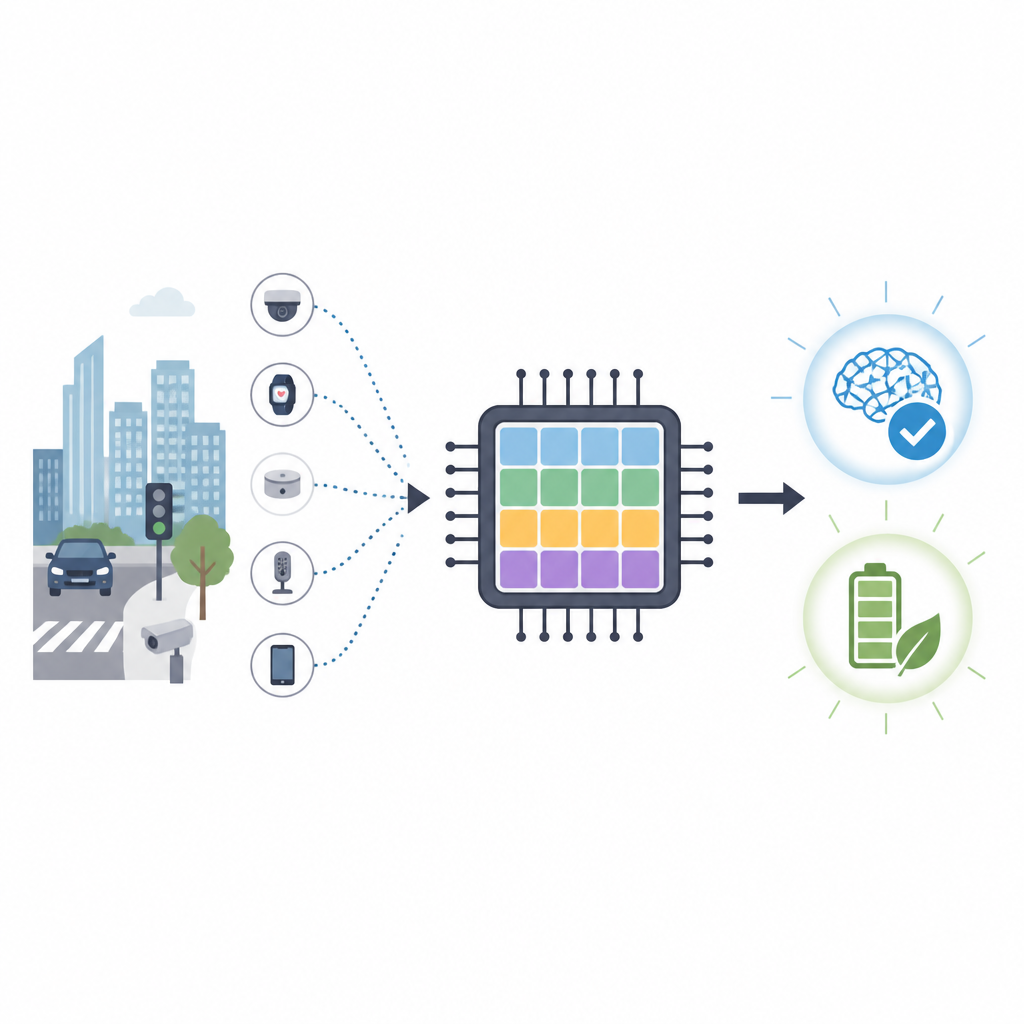
Våra telefoner, kameror och små sensorer blir allt smartare, men att lära dem nya färdigheter kräver ofta energikrävande datacenter. Denna artikel presenterar en ny typ av hjärninspirerat datorchip som kan lära direkt på små enheter samtidigt som det använder avsevärt mindre energi än dagens grafikprocessorer. Målet är att erbjuda flexibel, integritetsvänlig inlärning till bilar, drönare och andra prylar som måste reagera snabbt utan konstant hjälp från molnet.
Varför hjärnlika chip är viktiga
Konventionella chip som GPU:er är utmärkta på tunga beräkningar, men de förbrukar mycket energi och är beroende av snabba länkar till distanta servrar. För uppgifter som trafikövervakning eller drönarnavigering är det långsamt och potentiellt integritetskritiskt att skicka rådata till molnet. Neuromorf beräkning tar en annan väg genom att efterlikna hur nätverk av hjärnceller utbyter korta elektriska spikar. Spikande neurala nätverk lovar hög noggrannhet med betydligt färre operationer, vilket gör dem attraktiva för lågströmsenheter i nätverkets kant.
Den saknade pusselbiten i spikande hårdvara
Många forskningschip kör redan spikande nätverk effektivt, men nästan alla delar en viktig begränsning: de är bra på att använda en färdigtränad modell, men inte på att själva träna stora djupa spikande nätverk. De flesta förlitar sig på enkla lokala inlärningsregler eller avlastar den tunga fram- och återgående träningsprocessen till GPU:er. Det betyder att designers inte kan utnyttja de potentiella energivinsterna fullt ut under inlärning, och det gör det svårare för små enheter att anpassa sig i realtid när förhållanden förändras, som nya trafikskyltar eller ljusförhållanden.
En ny flerkärnig design för in-chip inlärning
Författarna introducerar en flerkärnig neuromorf arkitektur där varje kärna innehåller tre samverkande enheter: en som hanterar signaler framåt genom nätverket, en som skickar felinformation bakåt och en som uppdaterar anslutningsstyrkorna. Dessa kärnor är länkade i ett tvådimensionellt rutnät, så olika lager i ett djupt spikande nätverk kan placeras på olika kärnor och arbeta parallellt. Ett noggrant utformat kommunikationsnät rör både snabba enbitsspikarna och långsammare precisa värden mellan kärnorna i takt med spikarnas timing, medan en near-memory-design håller de flesta data på chipet och minskar dyra resor till extern minne.
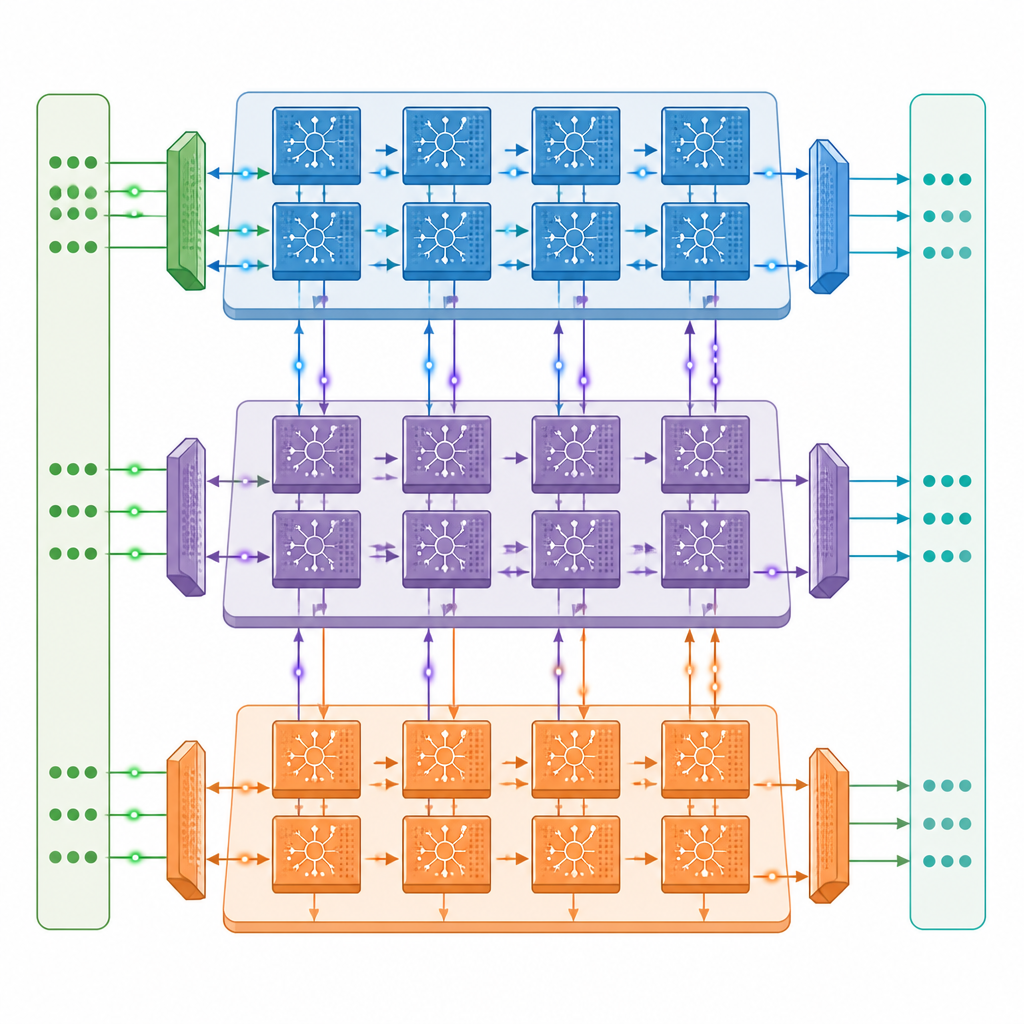
Göra mer med mindre datarörelse
Inuti varje enhet är hårdvaran anpassad till den start-stopp-liknande naturen hos spikande aktivitet. Kretsar upptäcker när grupper av neuroner är tysta och hoppar över onödiga beräkningar och minnesläsningar, en strategi som halverar energianvändningen ungefär vid träning på standardmodeller för bildigenkänning. Designen återanvänder också lagrade data där det är möjligt och sparar spikar som enstaka bitar, vilket kraftigt minskar behovet av externt minne. I tester med populära djupa spikande versioner av ResNet och VGG når prototypen upp till omkring en tredjedel av träningshastigheten hos en kraftfull A100-datacenter-GPU, trots att den bara har omkring en tjugondel av dess råa beräkningskapacitet, och överträffar tydligt ett Jetson Orin-edge-system.
Från labbprototyp till verklig edge-inlärning
För att visa att idén fungerar bortom simuleringar kartlade teamet en mindre version av arkitekturen på flera FPGA-kort och tränade spikande nätverk på standardiserade bild- och händelsebaserade gestdatamängder. Systemet hanterade kontinuerlig inlärning, där modeller uppdateras när nya typer av prov dyker upp, och federerad inlärning, där flera enheter tränar lokalt och endast delar kompakta uppdateringar. I båda fallen förbättrade det distribuerade spikande systemet noggrannheten utan att centralisera rådata, vilket pekar mot framtida smart city- och robotikapplikationer där många enheter lär sig tillsammans samtidigt som energioch bandbreddsbehov hålls i schack.
Vad detta betyder för vardagsteknik
Enkelt uttryckt visar detta arbete hur man bygger en hjärnilik träningsmotor som ryms inom de snäva strömramarna för enheter i kanten. Genom att kombinera många små lärandekärnor, smart datarouting och aggressivt hoppande över onödigt arbete tränar arkitekturen djupa spikande nätverk effektivt utan att luta sig mot gigantiska datacenter. Om detta förverkligas i chipform kan sådana designer hjälpa kameror, bilar och hushållsapparater att lära av sin omgivning i realtid samtidigt som integriteten bevaras och energi sparas.
Citering: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
Nyckelord: neuromorf beräkning, spikande neurala nätverk, edge-AI, lågenergihårdvara, in-chip inlärning