Clear Sky Science · zh
使用两大全眼底队列研究视网膜基础模型中预训练数据影响的理解
为何眼部扫描与人工智能训练数据至关重要
眼部扫描不仅越来越多地用于发现眼部疾病,还能揭示关于总体健康的线索,从糖尿病到中风风险。称为基础模型的强大人工智能系统可以从数百万张此类图像中学习,然后被调整用于多种医疗任务。本研究提出了一个简单但重要的问题:我们用来训练这些模型的数据类型——患者构成、来源地点以及扫描的外观——是否会改变模型的表现及其公平性?
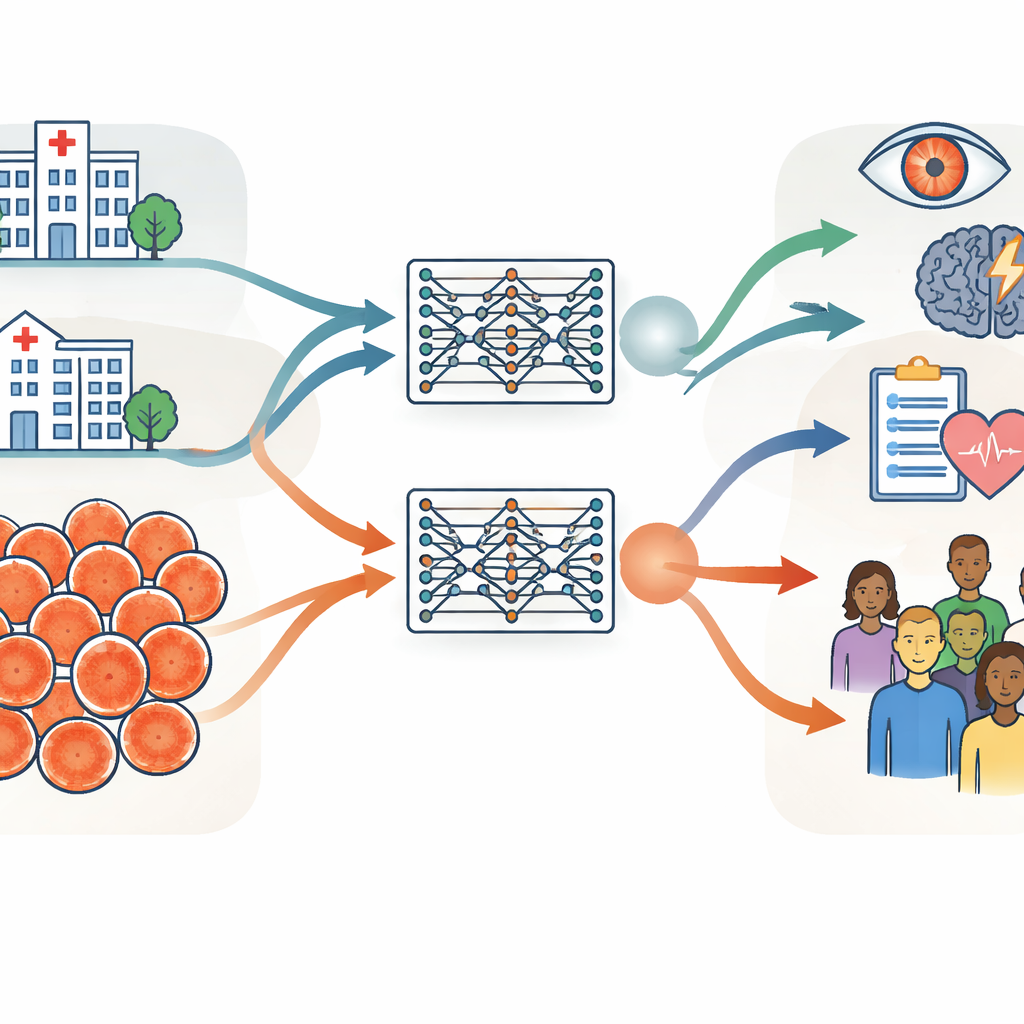
两套来自不同大陆的大规模眼底图像集合
研究者将调查建立在两套非常大规模的视网膜照片集合之上,每套约包含90万张图像。一套来自英国的穆尔菲尔德眼科医院(Moorfields Eye Hospital),这是一家专科医院,患者往往年龄较大且眼病较多。另一套来自中国的上海糖尿病防治项目,这是一个社区筛查项目,参与者较年轻且多数健康。除了年龄和健康状况外,两组在性别比例、民族构成以及拍摄图像所用相机设备上也存在差异。研究团队使用基本信息(如年龄和性别)、计算机衍生的图像特征以及具有临床意义的血管和视盘(视神经)测量,谨慎地量化了这些差异。
训练双胞胎式人工智能模型以测试总体性能
使用相同的训练流程,团队创建了两款“孪生”视网膜基础模型:一款仅用英国医院图像训练,另一款仅用中国筛查图像训练。两款模型都以自监督方式从未标注的影像中学习,然后被微调以完成特定任务,例如检测糖尿病性眼病和预测中风风险。关键测试是:在一个情境下训练的模型,在应用到另一个情境或来自多个其他国家的公开数据集时,是否仍能表现良好。在大多数任务和数据集中,两个模型的表现相似,即便是在评估那些与训练中所见图像差别较大的影像时也是如此。这表明,一旦在足够多的数据上训练,视网膜基础模型可以在医院、国家和相机类型之间很好地泛化。
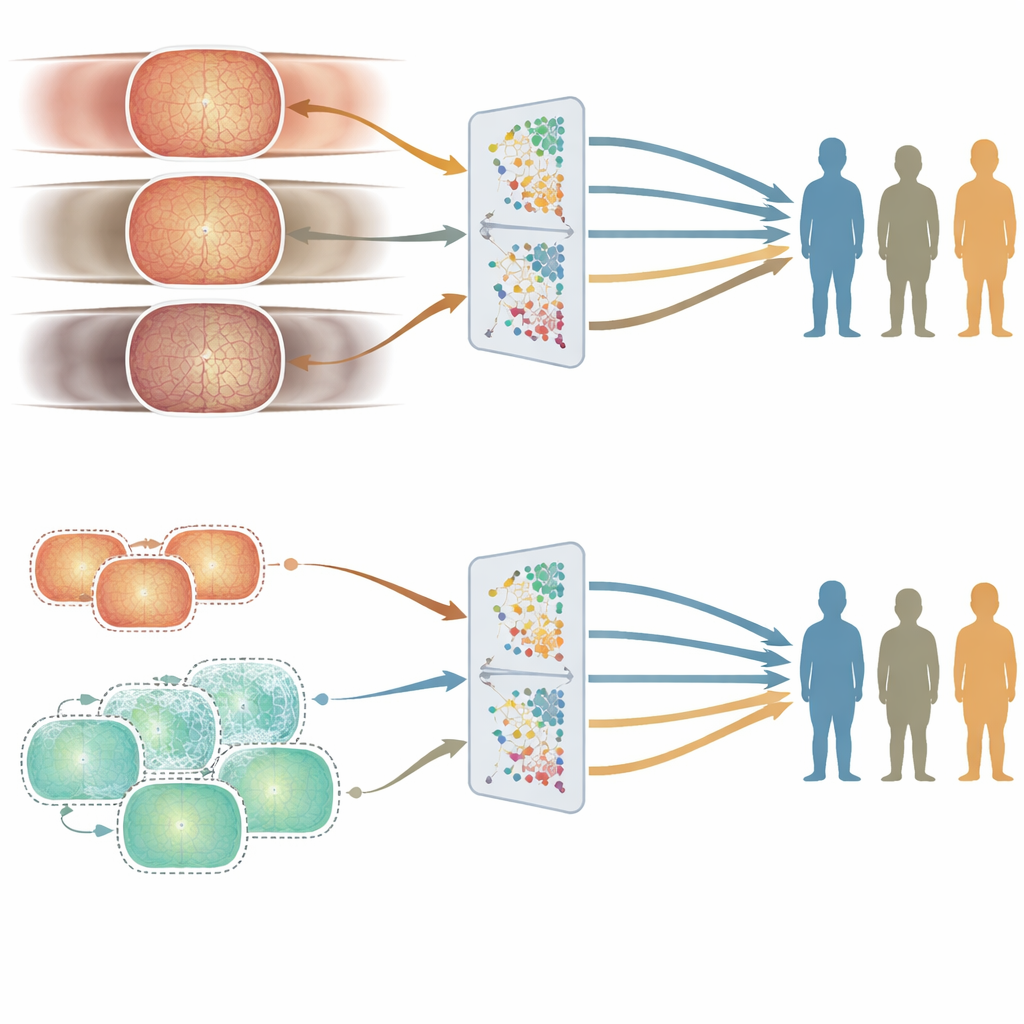
公平性出现裂缝的地方:年龄 vs. 性别与民族
良好的平均准确率并不足够,如果系统对某些人群的表现优于其他人就不公平。为了探究公平性,作者使用精心策划的测试集比较了两款模型在不同年龄、性别和民族亚组中的表现。结果显示年龄最为关键。以英国数据训练的模型(以较年长患者为主)在较高年龄组中表现更好,而以中国数据训练的模型(以较年轻成人为主)在年轻人中表现更佳。这些差距在若干眼病任务中持续出现。相比之下,男女之间或主要民族组之间的表现差异较小且不太一致,且并未以简单方式与这些群体在训练数据中的占比对应。
随年龄变化的眼部自身变化
为理解为何年龄具有如此强的影响,团队考察了训练集中随年龄变化的视网膜外观。他们既查看了临床测量——例如血管的复杂度和分支情况——也查看了模型从图像中提取的抽象特征。即便在控制了性别和民族后,各年龄组在这两类测量上都显示出明显且具有统计学意义的差异。换言之,视网膜的结构确实会随年龄发生可被模型检测到的变化。因此,某一年龄段占比过重的训练集会使模型对该年龄段更为敏感,从而产生细微但重要的公平性差距。
使用合成图像来平衡差距
为了检验能否减小这些与年龄相关的差距,研究者生成了数十万张设计为类似年轻患者的合成视网膜图像。他们将这些合成图像与真实的医院图像混合,以创建更为年龄平衡的训练集,并据此训练了新模型。总体性能保持相近,但在某些任务上对年轻人的准确率有所提高,缩小了不同年龄组之间的不公平。这一实验表明,经过谨慎设计的合成数据可以在无需大量新增真实图像的情况下,帮助弥补医疗人工智能的盲点。
对未来医疗人工智能的启示
该研究表明,供给医疗人工智能系统的数据“构成”强烈影响它们不仅有多强大,也影响谁能从中获益最多。视网膜基础模型能在国家和设备之间稳健工作,这对全球应用是一个积极信号。与此同时,研究也揭示了某些数据属性——在此例中为年龄——对公平性的影响大于其他属性。对于患者和临床人员而言,关键信息是:关于训练数据的透明度以及有意平衡关键特征都是必要的,如果我们希望人工智能工具能够公平地为各年龄段人群服务。
引用: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
关键词: 视网膜成像, 医疗人工智能公平性, 基础模型, 预训练数据, 糖尿病视网膜病变