Clear Sky Science · pl
Zrozumienie wpływu danych do wstępnego trenowania na modele bazowe siatkówki przy użyciu dwóch dużych kohort funduszy
Dlaczego skany oka i dane do trenowania AI mają znaczenie
Skany oczu są coraz częściej wykorzystywane nie tylko do wykrywania chorób oczu, lecz także do ujawniania wskazówek o ogólnym stanie zdrowia — od cukrzycy po ryzyko udaru. Potężne systemy sztucznej inteligencji, zwane modelami bazowymi, mogą uczyć się na milionach takich obrazów, a następnie być dostosowywane do różnych zadań medycznych. W tym badaniu postawiono proste, lecz istotne pytanie: czy rodzaj danych użytych do trenowania tych modeli — kim są pacjenci, skąd pochodzą i jak wyglądają ich skany — wpływa na to, jak dobrze i jak sprawiedliwie modele działają?
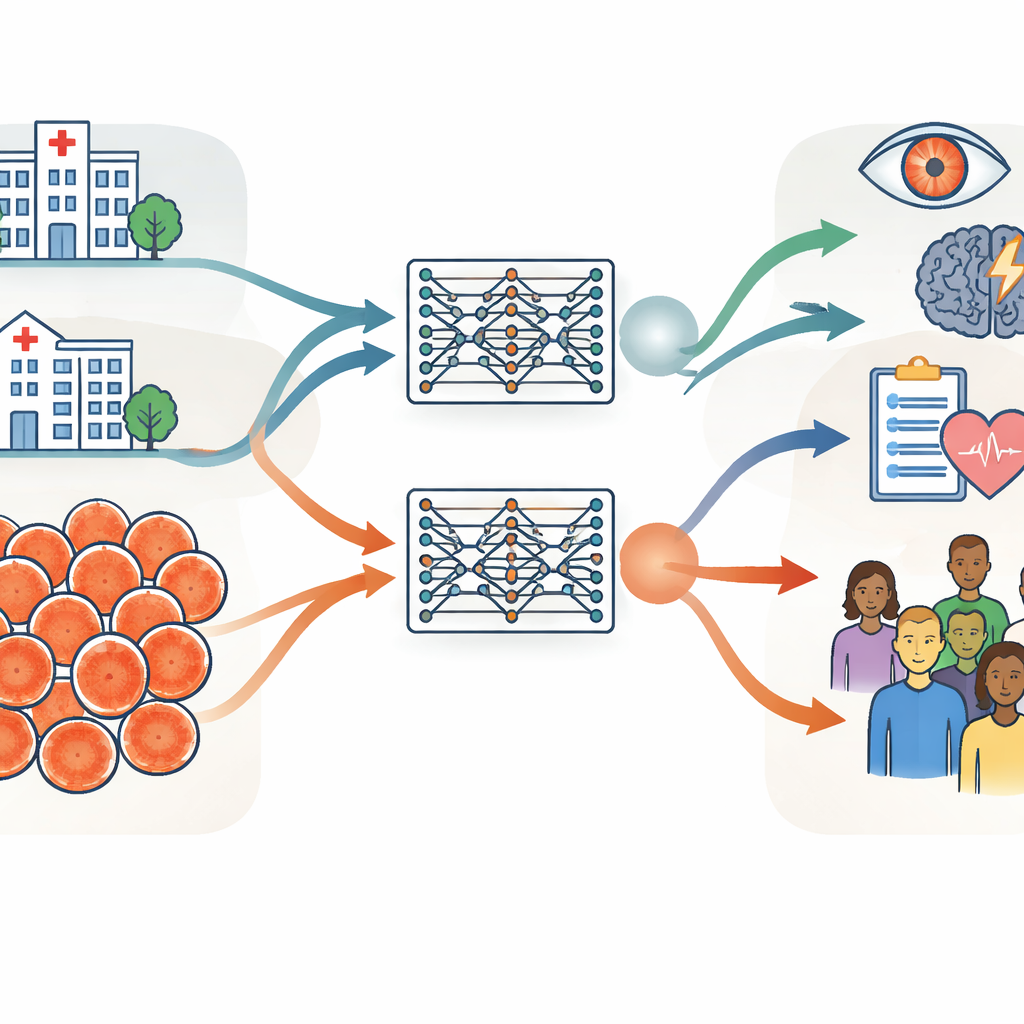
Dwie ogromne kolekcje obrazów oka na różnych kontynentach
Naukowcy zbudowali swoje badanie wokół dwóch bardzo dużych zbiorów fotografii dna oka, z których każdy zawierał około 900 000 obrazów. Jeden pochodził z Moorfields Eye Hospital w Wielkiej Brytanii, szpitala specjalistycznego, gdzie pacjenci mają tendencję do bycia starszymi i częściej występują u nich choroby oczu. Drugi pochodził z Shanghai Diabetes Prevention Program w Chinach, programu przesiewowego w środowisku społecznościowym obejmującego młodsze, przeważnie zdrowe osoby dorosłe. Poza wiekiem i stanem zdrowia grupy różniły się równowagą płci, składem etnicznym oraz urządzeniami fotograficznymi użytymi do wykonania obrazów. Zespół dokładnie zmierzył te różnice, korzystając z podstawowych informacji takich jak wiek i płeć, cech obrazów wyprowadzonych przez komputer oraz klinicznie istotnych miar naczyń krwionośnych i nerwu wzrokowego na tyle oka.
Trenowanie bliźniaczych modeli AI w celu sprawdzenia ogólnej wydajności
Stosując identyczne procedury treningowe, grupa stworzyła dwa „bliźniacze” modele bazowe siatkówki: jeden trenowany wyłącznie na obrazach ze szpitala w Wielkiej Brytanii, drugi wyłącznie na obrazach z chińskiego programu przesiewowego. Oba modele uczyły się w sposób samodzielny z nieoznakowanych skanów, a następnie były adaptowane do konkretnych zadań, takich jak wykrywanie chorób oka związanych z cukrzycą czy przewidywanie ryzyka udaru. Kluczowym testem było sprawdzenie, czy model wytrenowany w jednym środowisku nadal wypada dobrze, gdy zastosuje się go do danych z drugiego środowiska lub do publicznych zestawów danych zebranych w kilku innych krajach. W większości zadań i zestawów danych oba modele osiągały podobne wyniki, nawet gdy oceniano je na obrazach znacznie różniących się od tych, które widziały wcześniej. Sugeruje to, że modele bazowe siatkówki, jeśli zostaną wytrenowane na wystarczająco dużej liczbie danych, potrafią dobrze uogólniać naprzeciwko różnych szpitali, krajów i typów aparatów.
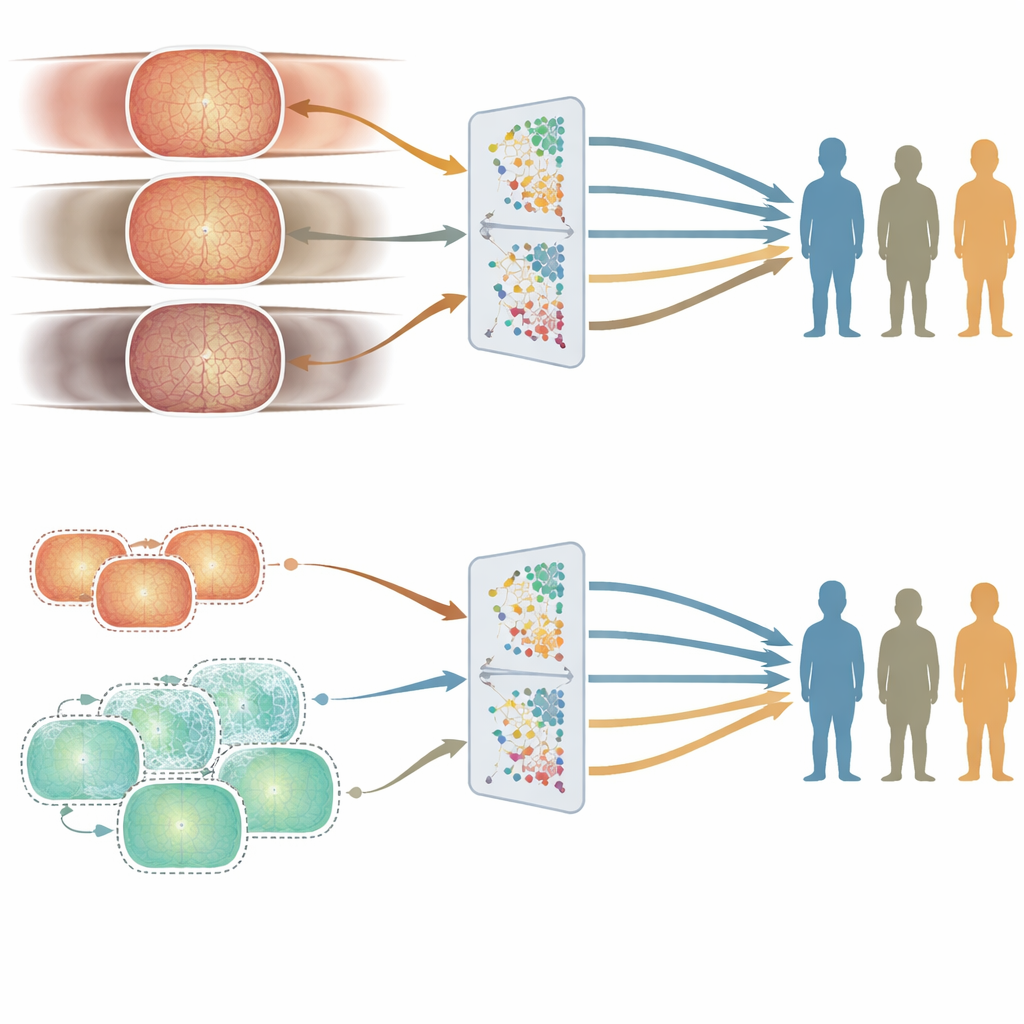
Gdzie pojawiają się pęknięcia sprawiedliwości: wiek kontra płeć i etniczność
Dobra średnia dokładność nie wystarcza, jeśli system działa lepiej dla niektórych osób niż dla innych. Aby zbadać sprawiedliwość, autorzy porównali wydajność obu modeli w różnych podgrupach wiekowych, płciowych i etnicznych, używając starannie skuratorowanego zestawu testowego. Wiek okazał się mieć największe znaczenie. Model trenowany na danych z Wielkiej Brytanii, zbudowany z danych starszych pacjentów, zwykle radził sobie lepiej w starszych grupach wiekowych, podczas gdy model trenowany na danych z Chin, powstały na podstawie młodszych dorosłych, osiągał lepsze wyniki u młodszych osób. Te różnice pojawiały się konsekwentnie w kilku zadaniach dotyczących chorób oczu. W przeciwieństwie do tego różnice w wydajności między mężczyznami i kobietami czy między głównymi grupami etnicznymi były mniejsze i mniej spójne, i nie korelowały w prosty sposób z tym, jak te grupy były reprezentowane w danych treningowych.
Jak samo oko zmienia się wraz z wiekiem
Aby zrozumieć, dlaczego wiek miał tak silny wpływ, zespół zbadał, jak wygląd siatkówki zmieniał się z wiekiem w zbiorach treningowych. Przyjrzeli się zarówno miarom klinicznym — takim jak złożoność i rozgałęzienie naczyń krwionośnych — jak i abstrakcyjnym cechom, które modele AI same wyodrębniają z obrazów. Grupy wiekowe wykazywały wyraźne i statystycznie istotne różnice w obu rodzajach miar, nawet po kontrolowaniu płci i etniczności. Innymi słowy, struktura siatkówki rzeczywiście zmienia się z wiekiem w sposób wykrywalny przez modele. Z tego powodu model silnie wytrenowany na jednym przedziale wiekowym może stać się lepiej dopasowany do tej grupy, prowadząc do subtelnych, lecz istotnych nierówności w sprawiedliwości.
Wykorzystanie obrazów syntetycznych do wyrównania szans
Aby sprawdzić, czy można zmniejszyć te wiekowe luki, badacze wygenerowali setki tysięcy syntetycznych obrazów siatkówki zaprojektowanych tak, by przypominać obrazy młodszych pacjentów. Wymieszali je z rzeczywistymi obrazami ze szpitala, tworząc bardziej zrównoważony wiekowo zbiór treningowy, po czym wytrenowali nowy model. Ogólna wydajność pozostała zbliżona, ale dokładność dla młodszych osób poprawiła się w niektórych zadaniach, zmniejszając nierówności między grupami wiekowymi. Ten eksperyment sugeruje, że ostrożne dodawanie danych syntetycznych może pomóc w wygładzeniu słabych punktów medycznej AI bez potrzeby zbierania znacznie większej liczby rzeczywistych obrazów.
Co to oznacza dla przyszłej medycznej AI
Badanie pokazuje, że „dieta” danych podawana systemom AI w medycynie w silny sposób kształtuje nie tylko ich skuteczność, ale też to, kto najwięcej z nich skorzysta. Modele bazowe siatkówki mogą działać solidnie między krajami i urządzeniami, co jest zachęcające dla zastosowań globalnych. Jednocześnie praca ujawnia, że pewne cechy danych — w tym przypadku wiek — mają większy wpływ na sprawiedliwość niż inne. Dla pacjentów i klinicystów przesłanie jest takie, że przejrzystość dotycząca danych treningowych oraz celowe bilansowanie kluczowych cech są niezbędne, jeśli chcemy, by narzędzia AI obsługiwały osoby w każdym wieku w sposób sprawiedliwy.
Cytowanie: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
Słowa kluczowe: obrazowanie siatkówki, sprawiedliwość AI w medycynie, modele bazowe, dane do wstępnego trenowania, retinopatia cukrzycowa