Clear Sky Science · en
Understanding pre-training data effects in retinal foundation models using two large fundus cohorts
Why eye scans and AI training data matter
Eye scans are increasingly being used not just to spot eye disease, but also to reveal clues about our general health, from diabetes to stroke risk. Powerful artificial intelligence systems called foundation models can learn from millions of these images and then be adapted to many medical tasks. This study asks a simple but important question: does the kind of data we use to train these models—who the patients are, where they come from, and how their scans look—change how well and how fairly the models work?
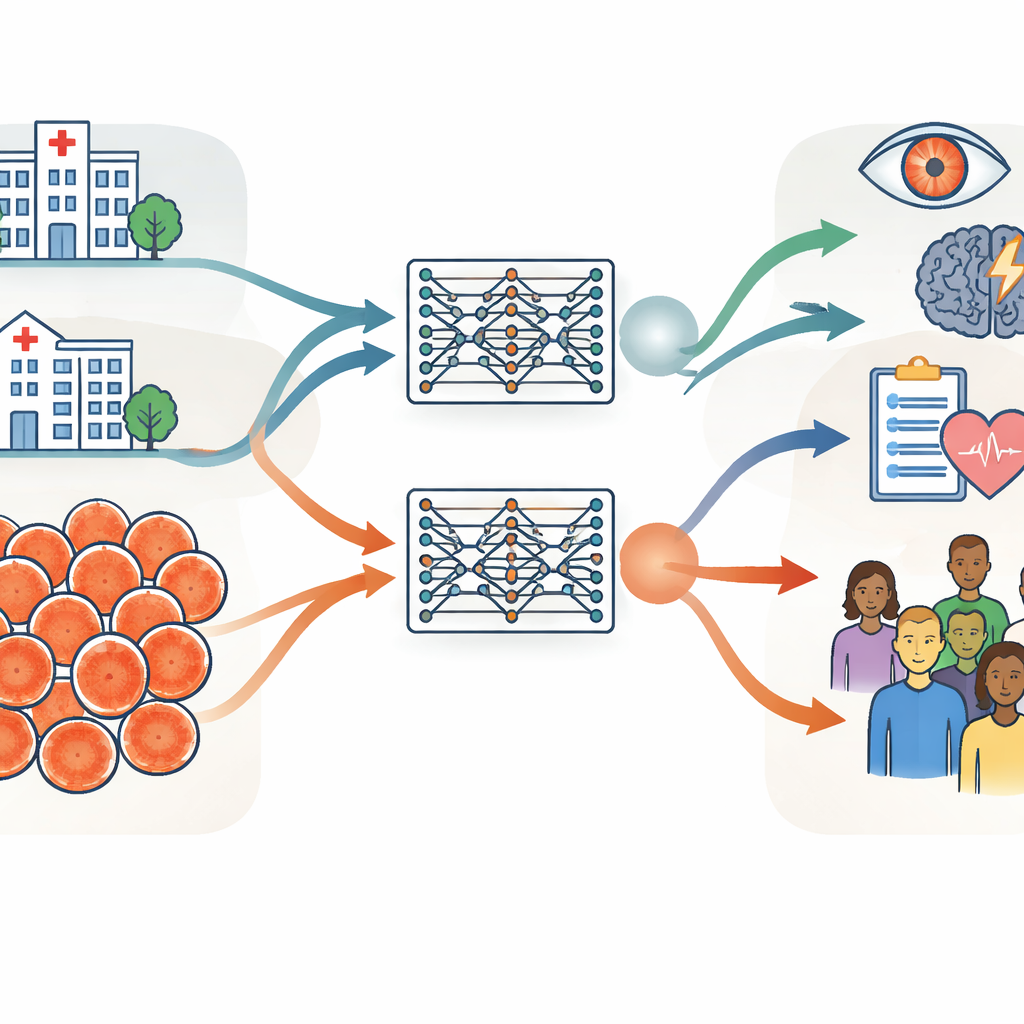
Two huge eye image collections on different continents
The researchers built their investigation around two very large collections of retinal photographs, each containing about 900,000 images. One came from Moorfields Eye Hospital in the United Kingdom, a specialist hospital where patients tend to be older and have more eye disease. The other came from the Shanghai Diabetes Prevention Program in China, a community screening program with younger, mostly healthy adults. Beyond age and health, the groups differed in sex balance, ethnic makeup, and the camera devices used to take the images. The team carefully measured these differences using basic information like age and sex, computer-derived image features, and clinically meaningful measures of the blood vessels and optic nerve at the back of the eye.
Training twin AI models to test general performance
Using identical training procedures, the group created two “twin” retinal foundation models: one trained only on the UK hospital images and one only on the Chinese screening images. Both models learned in a self-directed way from unlabeled scans, then were adapted to specific tasks such as detecting diabetic eye disease and predicting stroke risk. The key test was whether a model trained in one setting could still perform well when applied to data from the other setting or from public datasets collected in several other countries. Across most tasks and datasets, the two models performed similarly, even when evaluated on images quite different from those they had seen before. This suggests that retinal foundation models, once trained on enough data, can generalize well across hospitals, countries, and camera types.
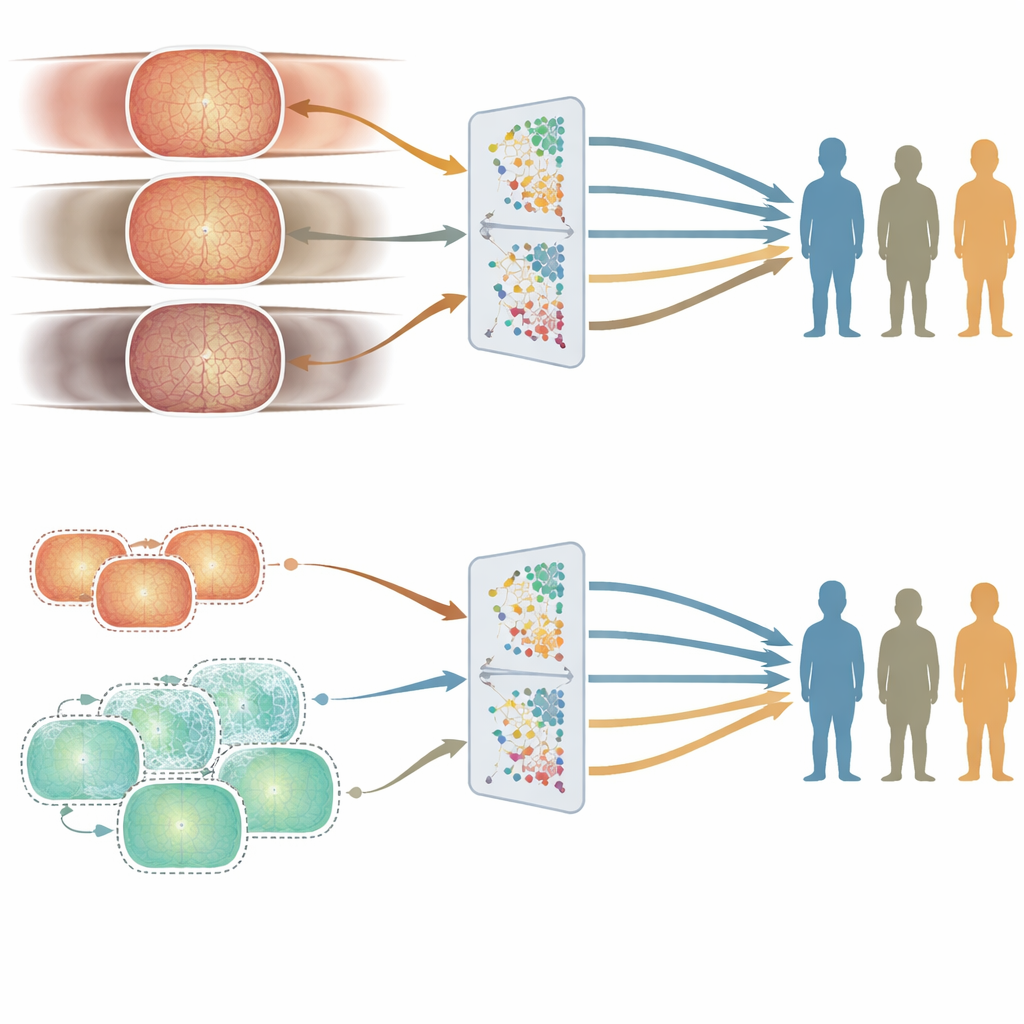
Where fairness cracks appear: age versus sex and ethnicity
Good average accuracy is not enough if a system works better for some people than others. To probe fairness, the authors compared how the two models performed in different age, sex, and ethnic subgroups using a carefully curated test set. Age turned out to matter most. The UK-trained model, built from older patients, tended to do better in older age groups, while the China-trained model, built from younger adults, did better in younger people. These gaps showed up consistently across several eye disease tasks. In contrast, performance differences between men and women, or between major ethnic groups, were smaller and less consistent, and did not track in any simple way with how those groups were represented in the training data.
How the eye itself changes with age
To understand why age had such a strong effect, the team examined how the appearance of the retina varied with age in the training sets. They looked both at clinical measures—such as how complex and branching the blood vessels were—and at abstract features that the AI models themselves extract from the images. Age groups showed clear and statistically significant differences in both kinds of measures, even after controlling for sex and ethnicity. In other words, the structure of the retina really does change with age in a way that the models can detect. Because of this, a model heavily trained on one age range can become more finely tuned to that group, leading to subtle but important fairness gaps.
Using synthetic images to even the playing field
To see whether they could reduce these age-related gaps, the researchers generated hundreds of thousands of synthetic retinal images designed to resemble younger patients. They mixed these with real hospital images to create a more age-balanced training set and then trained a new model. Overall performance stayed similar, but accuracy for younger people improved on some tasks, narrowing the unfairness between age groups. This experiment suggests that carefully adding synthetic data can help smooth out blind spots in medical AI without needing to collect vastly more real-world images.
What this means for future medical AI
The study shows that the “diet” of data fed to medical AI systems strongly shapes not only how powerful they are, but also who benefits most from them. Retinal foundation models can work robustly across countries and devices, which is encouraging for global use. At the same time, the work reveals that certain data attributes—in this case, age—have a larger impact on fairness than others. For patients and clinicians, the message is that transparency about training data and deliberate balancing of key characteristics are essential if we want AI tools that serve people of all ages equitably.
Citation: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
Keywords: retinal imaging, medical AI fairness, foundation models, pretraining data, diabetic retinopathy