Clear Sky Science · de
Verstehen der Auswirkungen von Vortrainingsdaten in retinalen Foundation-Modellen anhand zweier großer Fundus-Kohorten
Warum Augenaufnahmen und KI-Trainingsdaten wichtig sind
Augenaufnahmen werden zunehmend nicht nur zur Erkennung von Augenkrankheiten eingesetzt, sondern liefern auch Hinweise auf unseren allgemeinen Gesundheitszustand, von Diabetes bis zum Schlaganfallrisiko. Leistungsfähige künstliche Intelligenzsysteme, sogenannte Foundation-Modelle, können aus Millionen dieser Bilder lernen und anschließend an viele medizinische Aufgaben angepasst werden. Diese Studie stellt eine einfache, aber wichtige Frage: Verändert sich die Leistungsfähigkeit und Fairness dieser Modelle je nach Art der Trainingsdaten — wer die Patienten sind, woher sie stammen und wie ihre Aufnahmen aussehen?
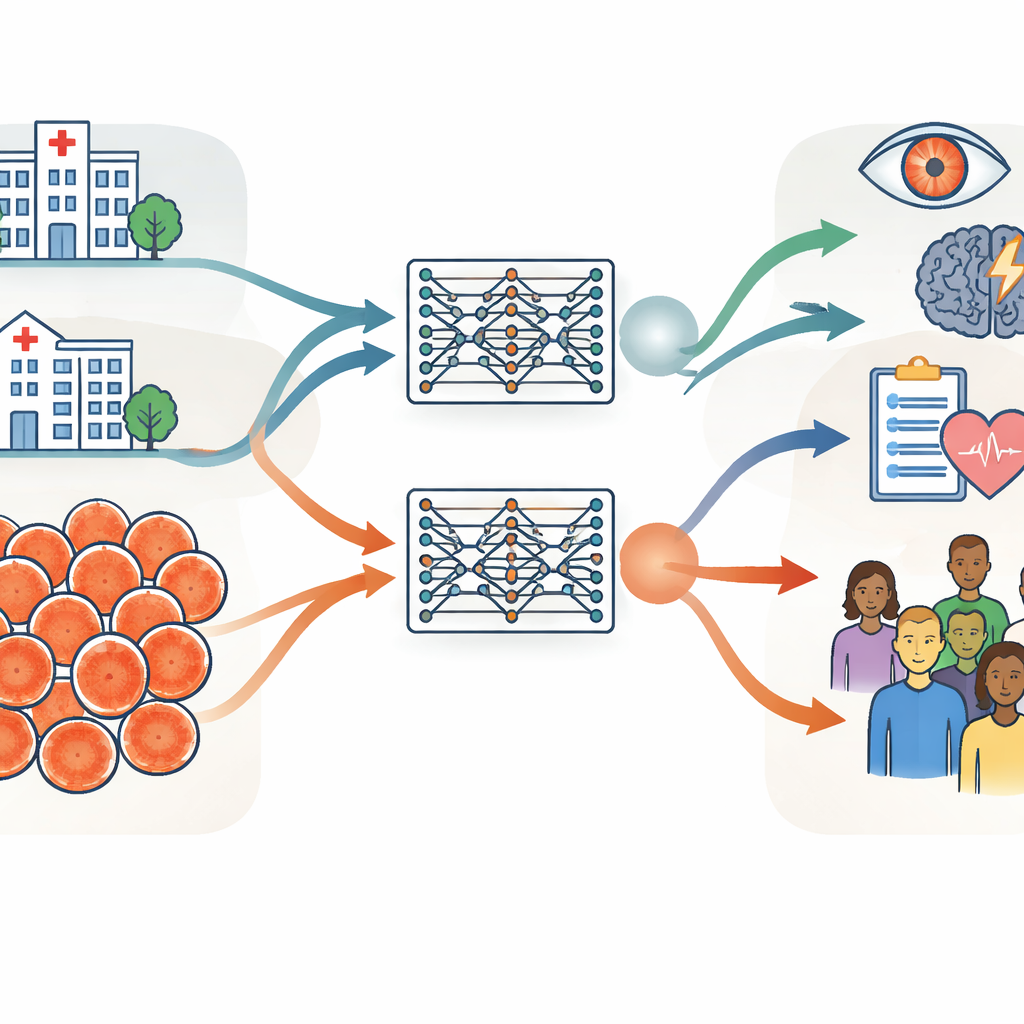
Zwei riesige Bildsammlungen vom Auge auf verschiedenen Kontinenten
Die Forschenden bauten ihre Untersuchung auf zwei sehr großen Sammlungen von Netzhautfotografien auf, die jeweils etwa 900.000 Bilder enthalten. Die eine stammte vom Moorfields Eye Hospital im Vereinigten Königreich, einem spezialisierten Krankenhaus, in dem die Patienten tendenziell älter sind und häufiger Augenkrankheiten aufweisen. Die andere kam vom Shanghai Diabetes Prevention Program in China, einem kommunalen Screeningprogramm mit jüngeren, überwiegend gesunden Erwachsenen. Über Alter und Gesundheitszustand hinaus unterschieden sich die Gruppen in Geschlechterverteilung, ethnischer Zusammensetzung und den verwendeten Kamerageräten. Das Team quantifizierte diese Unterschiede sorgfältig anhand grundlegender Informationen wie Alter und Geschlecht, computerabgeleiteter Bildmerkmale und klinisch relevanter Maße der Blutgefäße und des Sehnervs im hinteren Augenbereich.
Zwei identische KI-Modelle trainieren, um die allgemeine Leistungsfähigkeit zu testen
Mit identischen Trainingsverfahren erstellte die Gruppe zwei „zwillingsartige" retinalen Foundation-Modelle: eines, das ausschließlich mit den UK-Krankenhausbildern trainiert wurde, und eines, das nur mit den chinesischen Screening-Bildern trainiert wurde. Beide Modelle lernten selbstgesteuert aus unlabeled Aufnahmen und wurden dann für spezifische Aufgaben wie die Erkennung diabetischer Augenerkrankungen und die Vorhersage des Schlaganfallrisikos angepasst. Der entscheidende Test war, ob ein in einem Setting trainiertes Modell auch gute Leistungen erbringt, wenn es auf Daten aus dem anderen Setting oder auf öffentliche Datensätze aus mehreren anderen Ländern angewendet wird. Bei den meisten Aufgaben und Datensätzen zeigten die beiden Modelle ähnliche Leistungen, selbst wenn sie mit Bildern bewertet wurden, die sich deutlich von den zuvor gesehenen unterschieden. Das deutet darauf hin, dass retinalen Foundation-Modelle, sobald sie mit ausreichend Daten trainiert wurden, gut über Krankenhäuser, Länder und Kameratypen generalisieren können.
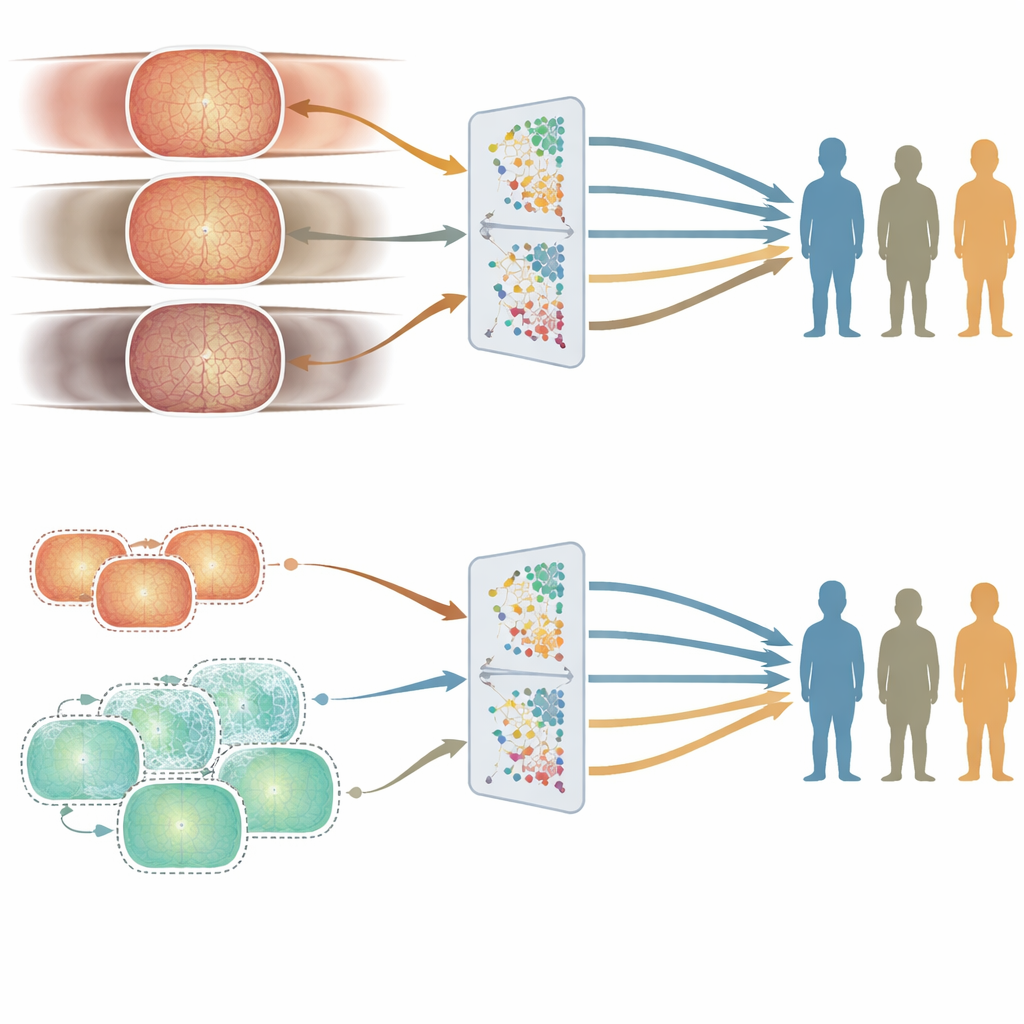
Wo Fairness-Lücken auftreten: Alter versus Geschlecht und Ethnie
Gute durchschnittliche Genauigkeit reicht nicht aus, wenn ein System für bestimmte Personen besser funktioniert als für andere. Um Fairness zu untersuchen, verglichen die Autoren die Leistung der beiden Modelle in verschiedenen Alters-, Geschlechts- und Ethnie-Subgruppen mithilfe eines sorgfältig kuratierten Testsets. Das Alter erwies sich als der wichtigste Faktor. Das in Großbritannien trainierte Modell, das aus älteren Patientendaten stammte, zeigte tendenziell bessere Ergebnisse in älteren Altersgruppen, während das in China trainierte Modell, das aus jüngeren Erwachsenen aufgebaut wurde, in jüngeren Gruppen besser abschnitt. Diese Unterschiede traten konsistent über mehrere Aufgaben zur Augenerkrankung hinweg auf. Im Gegensatz dazu waren Leistungsunterschiede zwischen Männern und Frauen oder zwischen großen ethnischen Gruppen kleiner und weniger konsistent und ließen sich nicht auf einfache Weise mit der Repräsentation dieser Gruppen in den Trainingsdaten erklären.
Wie sich das Auge selbst mit dem Alter verändert
Um zu verstehen, warum das Alter einen so starken Effekt hatte, untersuchte das Team, wie sich das Erscheinungsbild der Netzhaut mit dem Alter in den Trainingssätzen veränderte. Sie betrachteten sowohl klinische Messgrößen — etwa wie komplex und verzweigt die Blutgefäße sind — als auch abstrakte Merkmale, die die KI-Modelle selbst aus den Bildern extrahieren. Altersgruppen zeigten deutliche und statistisch signifikante Unterschiede in beiden Arten von Maßen, selbst nachdem für Geschlecht und Ethnie kontrolliert wurde. Mit anderen Worten: Die Struktur der Netzhaut verändert sich tatsächlich mit dem Alter auf eine Weise, die die Modelle erkennen können. Daher kann ein Modell, das stark auf einen bestimmten Altersbereich trainiert wurde, feiner auf diese Gruppe abgestimmt sein, was zu subtilen, aber wichtigen Fairness-Lücken führt.
Mit synthetischen Bildern für ausgeglichenere Trainingsdaten sorgen
Um zu prüfen, ob sich diese altersbedingten Lücken verringern lassen, erzeugten die Forschenden Hunderttausende synthetischer Netzhautbilder, die jüngeren Patienten ähneln sollten. Sie mischten diese mit realen Krankenhausbildern, um einen altersausgewogeneren Trainingssatz zu schaffen, und trainierten dann ein neues Modell. Die Gesamtleistung blieb ähnlich, aber die Genauigkeit für jüngere Menschen verbesserte sich bei einigen Aufgaben, wodurch die Ungerechtigkeit zwischen den Altersgruppen verringert wurde. Dieses Experiment legt nahe, dass das gezielte Hinzufügen synthetischer Daten helfen kann, blinde Flecken in medizinischer KI zu glätten, ohne eine sehr viel größere Sammlung realer Bilder zu benötigen.
Was das für die zukünftige medizinische KI bedeutet
Die Studie zeigt, dass die „Ernährung" von Daten, die medizinischen KI-Systemen zugeführt wird, stark beeinflusst, wie mächtig sie sind und wer am meisten von ihnen profitiert. Retinale Foundation-Modelle können robust über Länder und Geräte hinweg funktionieren, was für den globalen Einsatz ermutigend ist. Gleichzeitig offenbart die Arbeit, dass bestimmte Datenattribute — in diesem Fall das Alter — einen größeren Einfluss auf die Fairness haben als andere. Für Patientinnen, Patienten und Kliniker lautet die Botschaft, dass Transparenz über Trainingsdaten und eine bewusste Ausbalancierung wichtiger Merkmale unerlässlich sind, wenn wir KI-Werkzeuge wollen, die Menschen jeden Alters gerecht dienen.
Zitation: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
Schlüsselwörter: retinale Bildgebung, medizinische KI-Gerechtigkeit, Foundation-Modelle, Vortrainingsdaten, diabetische Retinopathie