Clear Sky Science · nl
Invloed van pre-trainingsdata op retina‑foundation‑modellen onderzocht met twee grote funduscohorten
Waarom oogscans en AI‑trainingsdata ertoe doen
Oogscans worden steeds vaker gebruikt, niet alleen om oogaandoeningen te herkennen, maar ook om aanwijzingen te geven over onze algemene gezondheid — van diabetes tot het risico op een beroerte. Krachtige kunstmatige‑intelligentiesystemen, zogenaamde foundation‑modellen, kunnen leren van miljoenen van zulke beelden en daarna worden aangepast voor veel medische taken. Deze studie stelt een eenvoudige maar belangrijke vraag: verandert het soort gegevens waarop we deze modellen trainen — wie de patiënten zijn, waar ze vandaan komen en hoe hun scans eruitzien — de prestaties en eerlijkheid van de modellen?
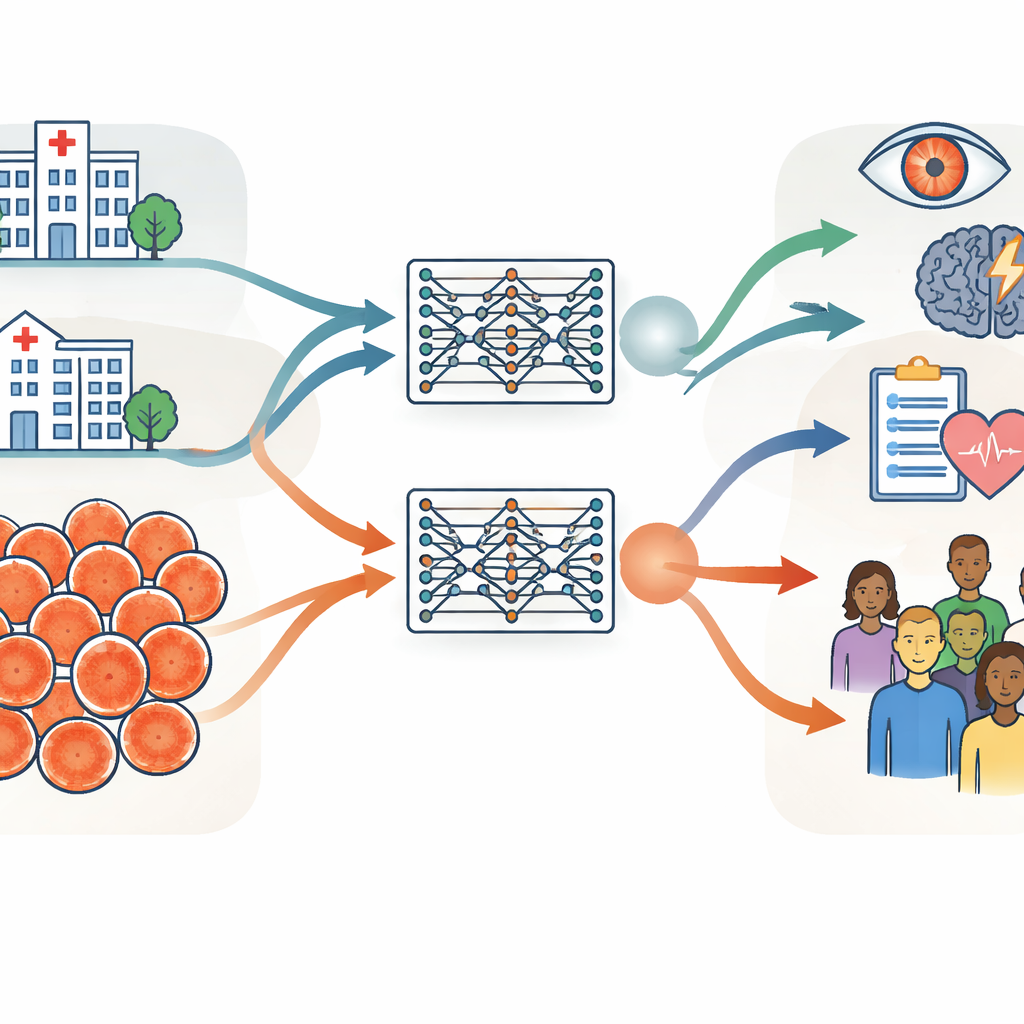
Twee enorme verzamelingen oogbeelden op verschillende continenten
De onderzoekers bouwden hun onderzoek rond twee zeer grote verzamelingen retinafoto’s, elk met ongeveer 900.000 afbeeldingen. De ene kwam van het Moorfields Eye Hospital in het Verenigd Koninkrijk, een gespecialiseerd ziekenhuis waar patiënten doorgaans ouder zijn en meer oogaandoeningen hebben. De andere kwam van het Shanghai Diabetes Prevention Program in China, een gemeenschaps‑screeningsprogramma met jongere, grotendeels gezonde volwassenen. Naast leeftijd en gezondheid verschilden de groepen in sekseverhouding, etnische samenstelling en de cameramodellen die werden gebruikt om de beelden te maken. Het team mat deze verschillen zorgvuldig met basisgegevens zoals leeftijd en geslacht, computerafgeleide beeldkenmerken en klinisch relevante metingen van de bloedvaten en de oogzenuwachterwand.
Twee identieke AI‑modellen trainen om algemene prestaties te testen
Met identieke trainingsprocedures creëerde het team twee “tweeling” retinal‑foundation‑modellen: één getraind uitsluitend op de Britse ziekenhuisbeelden en één uitsluitend op de Chinese screeningsbeelden. Beide modellen leerden op een zelfgestuurde manier van niet‑gelabelde scans en werden daarna aangepast aan specifieke taken zoals het detecteren van diabetische oogaandoeningen en het voorspellen van beroerterisico. De belangrijkste test was of een model dat in de ene context getraind was, nog steeds goed presteerde wanneer het werd toegepast op data uit de andere context of op openbare datasets uit meerdere landen. Over de meeste taken en datasets presteerden de twee modellen vergelijkbaar, zelfs wanneer ze werden geëvalueerd op beelden die behoorlijk verschilden van wat ze eerder hadden gezien. Dit suggereert dat retinal‑foundation‑modellen, eenmaal getraind op voldoende data, goed kunnen generaliseren over ziekenhuizen, landen en cameratypes heen.
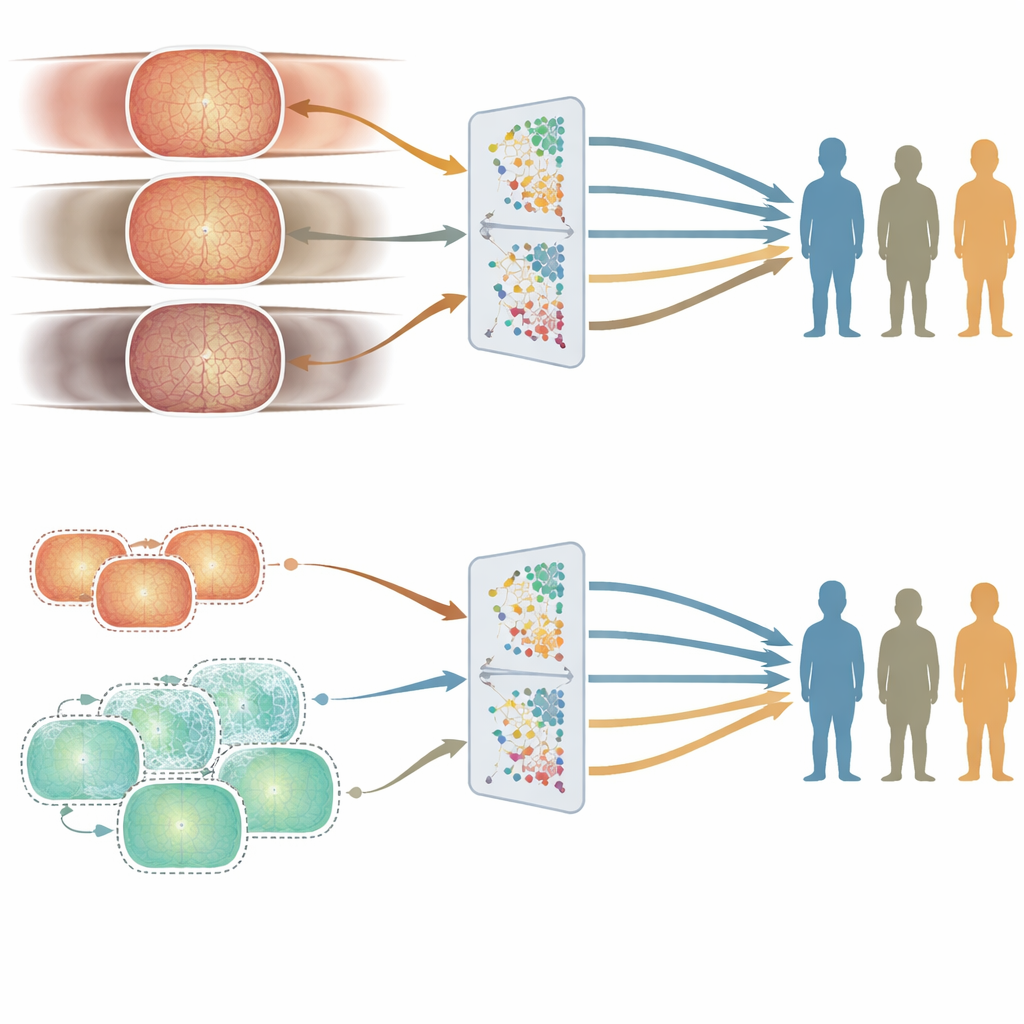
Waar ongelijkheid optreedt: leeftijd versus geslacht en etniciteit
Goede gemiddelde nauwkeurigheid is niet voldoende als een systeem voor sommige mensen beter werkt dan voor anderen. Om eerlijkheid te onderzoeken, vergeleken de auteurs hoe de twee modellen presteerden in verschillende leeftijds‑, geslachts‑ en etnische subgroepen met behulp van een zorgvuldig samengestelde testset. Leeftijd bleek het belangrijkst. Het in het VK getrainde model, gebouwd op oudere patiënten, deed het vaak beter in oudere leeftijdsgroepen, terwijl het in China getrainde model, opgebouwd uit jongere volwassenen, het beter deed bij jongere mensen. Deze verschillen verschenen consistent over meerdere oogziektetaken. Daarentegen waren prestatieverschillen tussen mannen en vrouwen, of tussen belangrijke etnische groepen, kleiner en minder consistent, en volgden ze geen eenvoudige relatie met hoe die groepen in de trainingsdata waren vertegenwoordigd.
Hoe het oog zelf verandert met de leeftijd
Om te begrijpen waarom leeftijd zo’n sterk effect had, onderzocht het team hoe het uiterlijk van het netvlies varieerde met leeftijd in de trainingssets. Ze bekeken zowel klinische metingen — zoals hoe complex en vertakt de bloedvaten waren — als abstracte kenmerken die de AI‑modellen zelf uit de beelden halen. Leeftijdsgroepen vertoonden duidelijke en statistisch significante verschillen in beide typen metingen, zelfs na controle voor geslacht en etniciteit. Met andere woorden: de structuur van het netvlies verandert echt met de leeftijd op een manier die de modellen kunnen detecteren. Daardoor kan een model dat sterk getraind is op één leeftijdsgroep fijner afgestemd raken op die groep, wat leidt tot subtiele maar belangrijke ongelijkheidskloofjes.
Gebruik van synthetische beelden om het speelveld gelijk te trekken
Om te onderzoeken of ze deze leeftijdsgebonden verschillen konden verkleinen, genereerden de onderzoekers honderden duizenden synthetische retinaafbeeldingen die bedoeld waren jongere patiënten te lijken. Ze mengden deze met echte ziekenhuisbeelden om een meer leeftijdsgebalanceerde trainingsset te creëren en trainden daarna een nieuw model. De algemene prestaties bleven vergelijkbaar, maar de nauwkeurigheid voor jongere mensen verbeterde bij sommige taken, waardoor de ongelijkheid tussen leeftijdsgroepen kleiner werd. Dit experiment suggereert dat het zorgvuldig toevoegen van synthetische data kan helpen blinde vlekken in medische AI te dichten zonder dat er veel meer echte beelden verzameld hoeven te worden.
Wat dit betekent voor toekomstige medische AI
De studie laat zien dat het “dieet” van data waarmee medische AI‑systemen worden gevoed sterk bepaalt niet alleen hoe krachtig ze zijn, maar ook wie er het meest van profiteert. Retina‑foundation‑modellen kunnen robuust werken over landen en apparaten heen, wat bemoedigend is voor wereldwijd gebruik. Tegelijkertijd toont het werk aan dat bepaalde data‑eigenschappen — in dit geval leeftijd — een grotere invloed op eerlijkheid hebben dan andere. Voor patiënten en clinici is de boodschap dat transparantie over trainingsdata en het doelbewust balanceren van belangrijke kenmerken essentieel zijn als we AI‑hulpmiddelen willen die mensen van alle leeftijden eerlijk dienen.
Bronvermelding: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
Trefwoorden: retina‑beeldvorming, medische AI‑rechtvaardigheid, foundation‑modellen, pretrainingdata, diabetische retinopathie