Clear Sky Science · he
הבנת השפעות נתוני האימון במודלים בסיסיים לרשתית באמצעות שני מאגרי פרנכיה גדולים
מדוע סריקות עיניים ונתוני אימון של בינה מלאכותית חשובים
סריקות עיניים משמשות יותר ויותר לא רק לזיהוי מחלות עיניים, אלא גם כדי לחשוף רמזים על מצבנו הבריאותי הכללי, החל מסוכרת ועד לסיכון לשבץ. מערכות בינה מלאכותית עוצמתיות הנקראות מודלים בסיסיים יכולות ללמוד ממיליוני תמונות כאלה ואז להיות מותאמות למשימות רפואיות רבות. המחקר הזה שואל שאלה פשוטה אך חשובה: האם סוג הנתונים שבהם אנו משתמשים לאימון המודלים — מי הם החולים, מאיפה הם מגיעים וכיצד נראית הסריקה שלהם — משנה עד כמה המודלים מדויקים והוגנים?
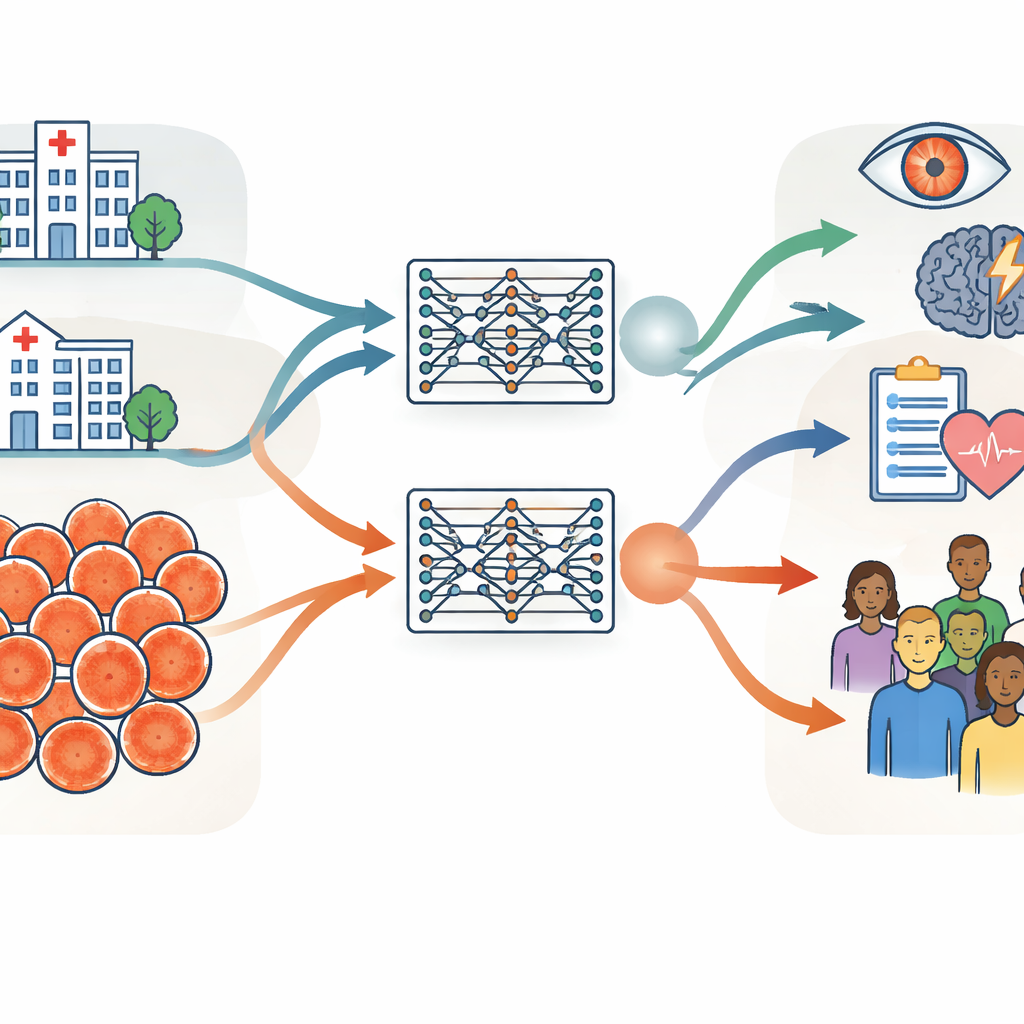
שתי אוספות עצומות של תמונות עין ביבשות שונות
החוקרים בנו את הבדיקה שלהם סביב שתי אוספות עצומות של צילומי רשתית, שכל אחת מהן כללה כ-900,000 תמונות. האחת נלקחה מבית החולים למורפילדס בבריטניה, בית חולים מומחה שבו המטופלים נוטים להיות מבוגרים יותר ולסבול יותר ממחלות עיניים. השנייה נלקחה מתוכנית מניעת סוכרת בשנגחאי, סין, תוכנית סקר קהילתית עם מבוגרים צעירים יותר ובריאים ברובם. מעבר לגיל ולמצב הבריאותי, הקבוצות שונות גם בהרכב המגדרי, במוצא האתני ובסוגי המצלמות שבהן צולמו התמונות. הצוות מדד בזהירות הבדלים אלה באמצעות מידע בסיסי כמו גיל ומגדר, תכונות תמונה שנגזרו על ידי מחשב, ומדדים קליניים משמעותיים של כלי הדם ועצב הראייה באזור האחורי של העין.
אימון זוג מודלים כדי לבחון ביצועים כלליים
באמצעות פרוצדורות אימון זהות, הקבוצה יצרה שני מודלים "תאומים" בסיסיים לרשתית: אחד שאומן רק על תמונות מבית החולים בבריטניה ואחד שאומן רק על תמונות מתוכנית הסקר בסין. שני המודלים למדו באופן עצמי מתמונות ללא תיוג, ואז הותאמו למשימות ספציפיות כמו זיהוי מחלות עיניים סוכרתיות וחיזוי סיכון לשבץ. המבחן המרכזי היה האם מודל שאומן בהקשר אחד יוכל עדיין לתפקד היטב כשמיישמים אותו על נתונים מההקשר השני או על מאגרי ציבוריים שנאספו במדינות נוספות. ברוב המשימות והמאגרים, שני המודלים הביצועים דומים, גם כאשר הוערכו על תמונות ששונות במידה ניכרת מאלו שראו קודם. ממצא זה מצביע על כך שמודלים בסיסיים לרשתית, לאחר שאומנו על מספיק נתונים, יכולים להכליל היטב בין בתי חולים, מדינות וסוגי מצלמות.
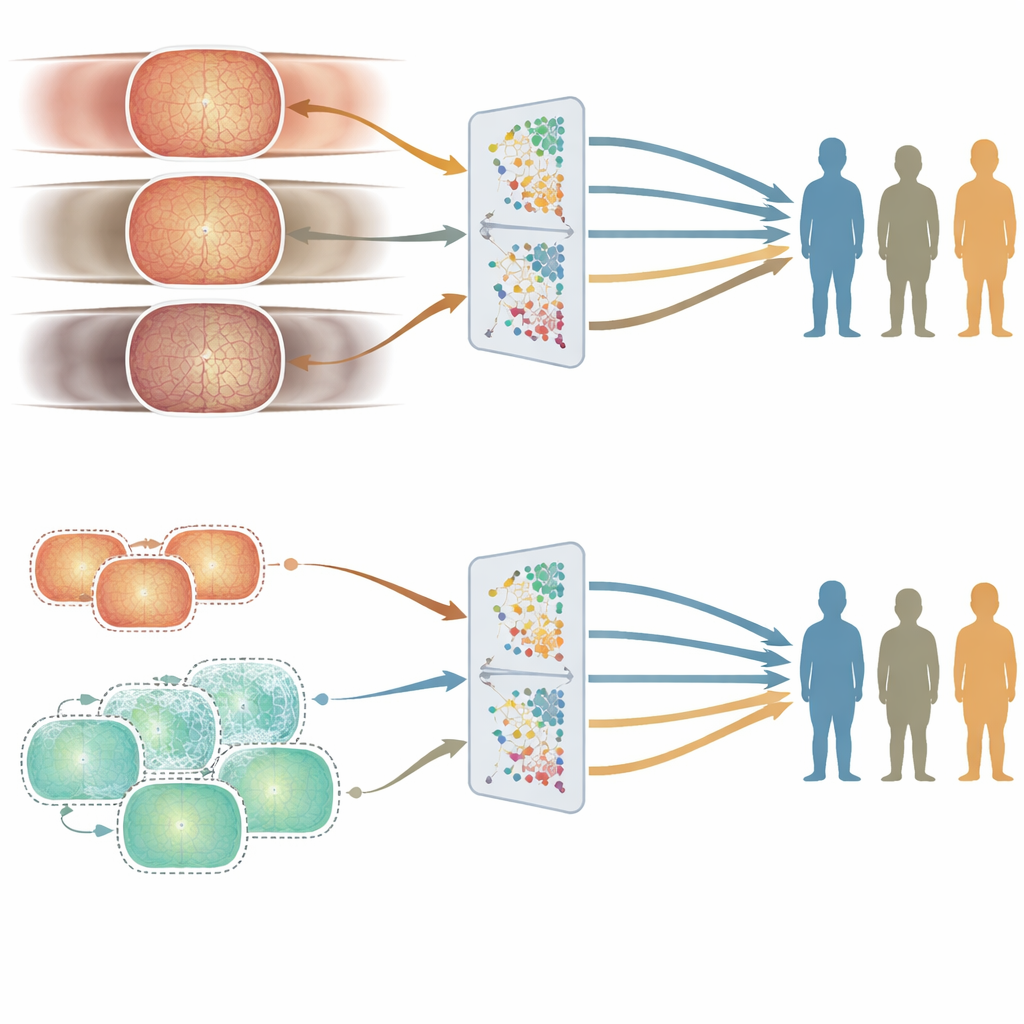
היכן מופיעים שברי הוגנות: גיל לעומת מגדר ואתניות
דיוק ממוצע טוב אינו מספיק אם המערכת עובדת טוב יותר עבור חלק מהאנשים לעומת אחרים. כדי לחקור הוגנות, המחברים השוו כיצד שני המודלים ביצעו בקבוצות משנה שונות מבחינת גיל, מגדר ואתניות בעזרת ערכת בדיקה מתוכננת בקפידה. גיל הסתבר כגורם המשמעותי ביותר. המודל שאומן בבריטניה, שנבנה ממטופלים מבוגרים יותר, נטה להצליח יותר בקבוצות גיל מבוגרות, בעוד המודל שאומן בסין, שנבנה ממבוגרים צעירים יותר, התברר כטוב יותר באוכלוסיות צעירות. פערים אלה הופיעו בעקביות במספר משימות הקשורות למחלת העיניים. לעומת זאת, הבדלים בביצועים בין גברים ונשים, או בין קבוצות אתניות עיקריות, היו קטנים ופחות עקביים, ולא עקבו בצורה פשוטה עם ייצוג הקבוצות בנתוני האימון.
כיצד העין עצמה משתנה עם הגיל
כדי להבין מדוע לגיל היה השפעה כה משמעותית, הצוות בחן כיצד הופעת הרשתית השתנתה עם הגיל בערכות האימון. הם בחנו הן מדדים קליניים — כמו מורכבות והסתעפות כלי הדם — והן תכונות מופשטות שהמודלים של הבינה המלאכותית עצמם חילצו מהתמונות. קבוצות גיל הראו הבדלים ברורים ובעלי משמעות סטטיסטית בשני סוגי המדדים, גם לאחר בקרה על מגדר ואתניות. במילים אחרות, מבנה הרשתית אכן משתנה עם הגיל בצורה שהמודלים יכולים לזהות. בעקבות כך, מודל שאומן בעיקר על טווח גיל מסוים עלול להתאים יותר לקבוצה זו, מה שמוביל לפערי הוגנות עדינים אך חשובים.
שימוש בתמונות סינתטיות כדי לאזן את השטח
כדי לבחון האם ניתן לצמצם את הפערים הקשורים לגיל, החוקרים ייצרו מאות אלפי תמונות רשתית סינתטיות שתוכננו להידמות למטופלים צעירים יותר. הם שילבו תמונות אלו עם תמונות בית החולים האמיתיות כדי ליצור ערכת אימון מאוזנת יותר מבחינת גיל ואז אימנו מודל חדש. הביצועים הכוללים נותרו דומים, אך הדיוק עבור צעירים השתפר בכמה משימות, וצמצם את חוסר ההוגנות בין קבוצות הגיל. הניסוי הזה מציע שהוספה מבוקרת של נתונים סינתטיים יכולה לעזור לטשטש נקודות עיוורון בבינה מלאכותית רפואית מבלי הצורך לאסוף כמות עצומה של תמונות אמיתיות נוספות.
מה משמעות הממצא לעתיד של בינה מלאכותית רפואית
המחקר מדגים כי ה"דיאטה" של נתונים המוזנת למערכות בינה מלאכותית רפואיות מעצבת בעוצמה לא רק עד כמה הן חזקות, אלא גם מי מרוויח מהן הכי הרבה. מודלים בסיסיים לרשתית יכולים לפעול בעקביות בין מדינות ומכשירים, מה שמעודד שימוש גלובלי. יחד עם זאת, העבודה חושפת שתכונות נתונים מסוימות — במקרה זה, גיל — משפיעות על ההוגנות יותר מאחרות. עבור מטופלים וצוותים קליניים, המסר הוא ששקיפות לגבי נתוני האימון ואיזון מכוון של מאפיינים מרכזיים הם חיוניים אם רוצים כלים מבוססי AI שמשרתים אנשים בכל הגילאים באופן שוויוני.
ציטוט: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
מילות מפתח: דימות רשתית, הוגנות בבינה מלאכותית רפואית, מודלים בסיסיים, נתוני אימון מקדימים, רטינופתיה סוכרתית