Clear Sky Science · ja
網膜ファウンデーションモデルにおける事前学習データの影響を、2つの大規模眼底コホートで検証する
なぜ眼のスキャンとAIの学習データが重要なのか
眼の画像は、眼疾患を見つけるだけでなく、糖尿病や脳卒中リスクなど全身の健康に関する手がかりを明らかにするためにもますます用いられています。ファウンデーションモデルと呼ばれる強力な人工知能は、こうした何百万もの画像から学習し、さまざまな医療タスクに適応できます。本研究は単純だが重要な問いを投げかけます:これらのモデルを訓練する際に使うデータの種類――患者の属性、出身、画像の見え方など――は、モデルの性能や公平性にどのように影響するのか?
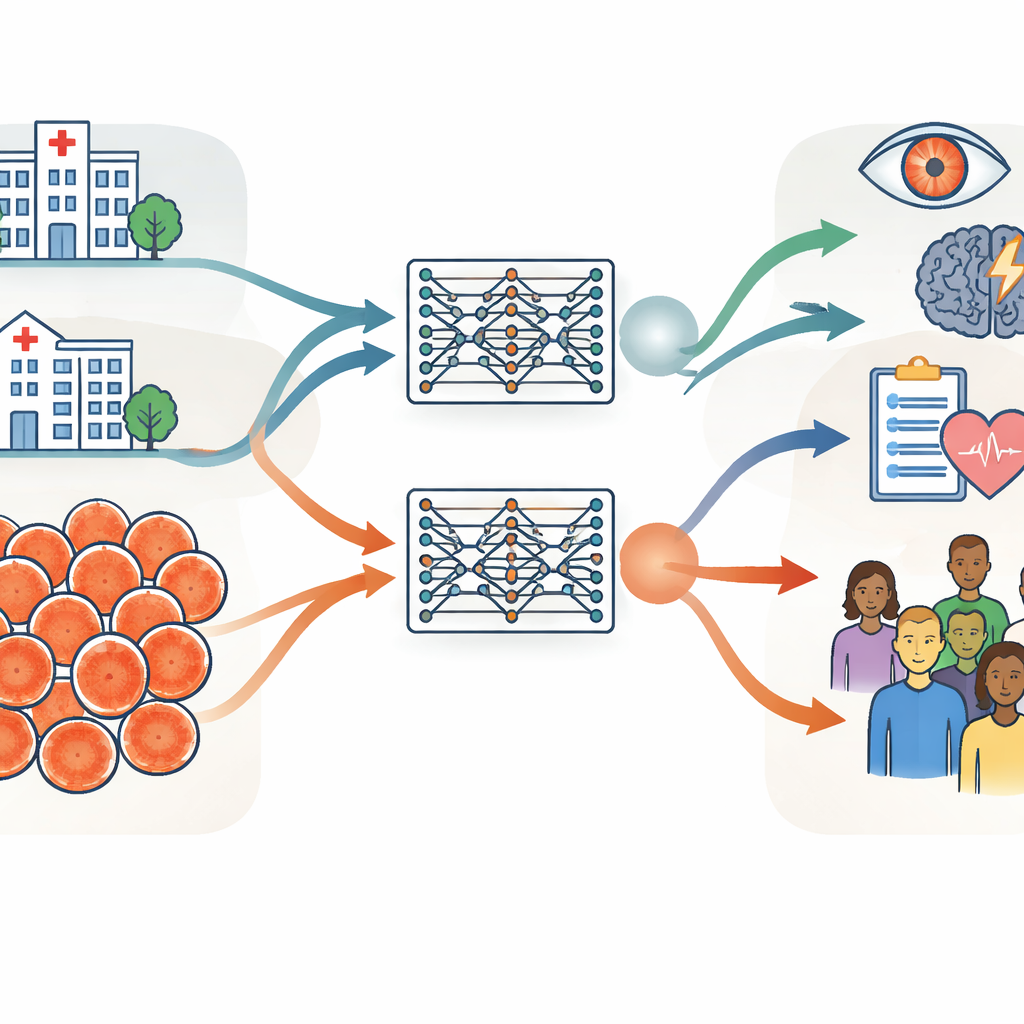
異なる大陸にある2つの巨大な眼底画像コレクション
研究者らは、各約90万枚の網膜写真を含む非常に大きな2つのコホートを軸に調査を組み立てました。一方は英国の専門病院であるムーアフィールド眼科病院からで、患者は高齢で眼疾患を持つ割合が高い傾向があります。もう一方は中国の上海糖尿病予防プログラムからで、地域のスクリーニング事業により若年で概ね健康な成人が中心です。年齢や健康状態以外にも、性別割合、人種構成、撮影に用いられたカメラ機器などが異なっていました。研究チームは年齢や性別といった基本情報、コンピュータが導出する画像特徴、網膜後部の血管や視神経乳頭に関する臨床的に意味のある指標を用いてこれらの差異を慎重に測定しました。
一般的性能を試すための双子モデルの訓練
同一の訓練手順を用いて、研究グループは2つの“双子”網膜ファウンデーションモデルを作成しました:1つは英国の病院画像のみで事前学習し、もう1つは中国のスクリーニング画像のみで事前学習しました。両モデルともラベルなしのスキャンから自己教師ありで学習し、その後糖尿病性眼疾患の検出や脳卒中リスクの予測など特定のタスクに適応されました。重要な検証は、一方で学習したモデルが他方の環境や、複数国で収集された公開データセットに適用したときに十分に機能するかどうかでした。ほとんどのタスクとデータセットにおいて、両モデルはかなり似た性能を示し、これまで見たことのないかなり異なる画像で評価しても同様でした。これは、網膜ファウンデーションモデルが十分な量のデータで訓練されれば、病院や国、カメラ種別を越えて良好に一般化できる可能性を示唆します。
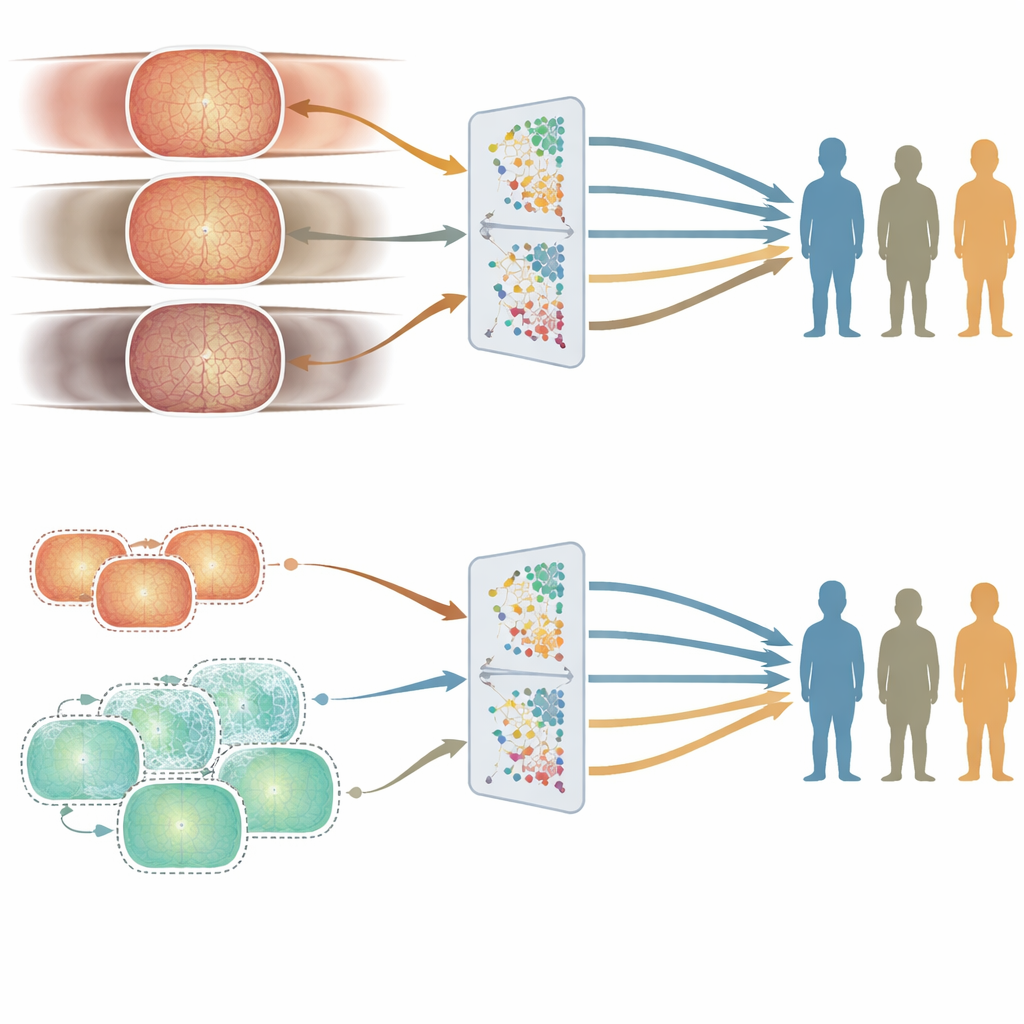
公平性の亀裂が現れる場所:年齢対性別・人種
平均的な精度が高くても、ある集団に対して優れて別の集団に対して劣るようでは不十分です。公平性を詳しく調べるために、著者らは慎重にキュレーションしたテストセットを用いて年齢、性別、人種の各サブグループで両モデルの性能を比較しました。最も影響が大きかったのは年齢でした。高齢者が多い英国訓練モデルは高齢層でより良い傾向があり、若年成人が中心の中国訓練モデルは若年層でより良い結果を示す傾向がありました。これらの差は複数の眼疾患タスクにわたって一貫して現れました。これに対して、男女間や主要な人種間の性能差は小さく一貫性に欠け、トレーニングデータ内でのその集団の占有率と単純に対応するものではありませんでした。
年齢とともに変わる眼そのものの構造
なぜ年齢がこれほど強い影響を持つのかを理解するため、チームは訓練セット内で網膜の外観が年齢とともにどのように変わるかを調べました。彼らは血管の複雑さや分岐といった臨床的指標と、AIモデル自体が画像から抽出する抽象的特徴の両方を解析しました。年齢群ごとに、性別や人種を統制しても両種の指標で明確かつ統計的に有意な差が見られました。言い換えれば、網膜の構造は年齢とともに実際に変化しており、モデルはそれを検出できるということです。そのため、ある年齢層に偏って大量に訓練されたモデルはその層に微妙に最適化され、結果として重要な公平性のギャップを生む可能性があります。
合成画像を使ってバランスを取る
年齢に関連するギャップを減らせるかを試すために、研究者らは若年患者に似せた何十万枚もの合成網膜画像を生成しました。これらを実際の病院画像と混ぜ、年齢バランスを改善した訓練セットを作って新たなモデルを訓練しました。全体性能はほぼ同等に保たれた一方で、若年層の精度は一部のタスクで向上し、年齢間の不公平性を縮小しました。この実験は、慎重に合成データを追加することで、膨大な実地画像を新たに集めることなく医療AIの盲点を緩和できる可能性を示しています。
今後の医療AIへの示唆
本研究は、医療AIシステムに与えるデータの“食材”が、その力だけでなく、誰が最も利益を得るかを強く形作ることを示しています。網膜ファウンデーションモデルは国や機器を越えて堅牢に機能しうるため、グローバルな利用にとって望ましい結果です。一方で、本研究は年齢のようないくつかのデータ属性が公平性に対して他より大きな影響を持つことを明らかにしました。患者や臨床医に向けたメッセージは、訓練データの透明性と重要な属性の意図的なバランス調整が、あらゆる年齢の人々に公平に役立つAIツールを作るために不可欠であるということです。
引用: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
キーワード: 網膜イメージング, 医療AIの公平性, ファウンデーションモデル, 事前学習データ, 糖尿病性網膜症