Clear Sky Science · fr
Comprendre les effets des données de pré-entraînement dans les modèles fondamentaux rétiniens à l’aide de deux vastes cohortes de fonds de l’œil
Pourquoi les scans oculaires et les données d’entraînement en IA comptent
Les scans oculaires sont de plus en plus utilisés non seulement pour détecter les maladies de l’œil, mais aussi pour révéler des indices sur notre santé générale, du diabète au risque d’accident vasculaire cérébral. De puissants systèmes d’intelligence artificielle appelés modèles fondamentaux peuvent apprendre à partir de millions de ces images puis être adaptés à de nombreuses tâches médicales. Cette étude pose une question simple mais importante : le type de données que nous utilisons pour entraîner ces modèles — qui sont les patients, d’où ils viennent, et à quoi ressemblent leurs scans — modifie-t-il la performance et l’équité des modèles ?
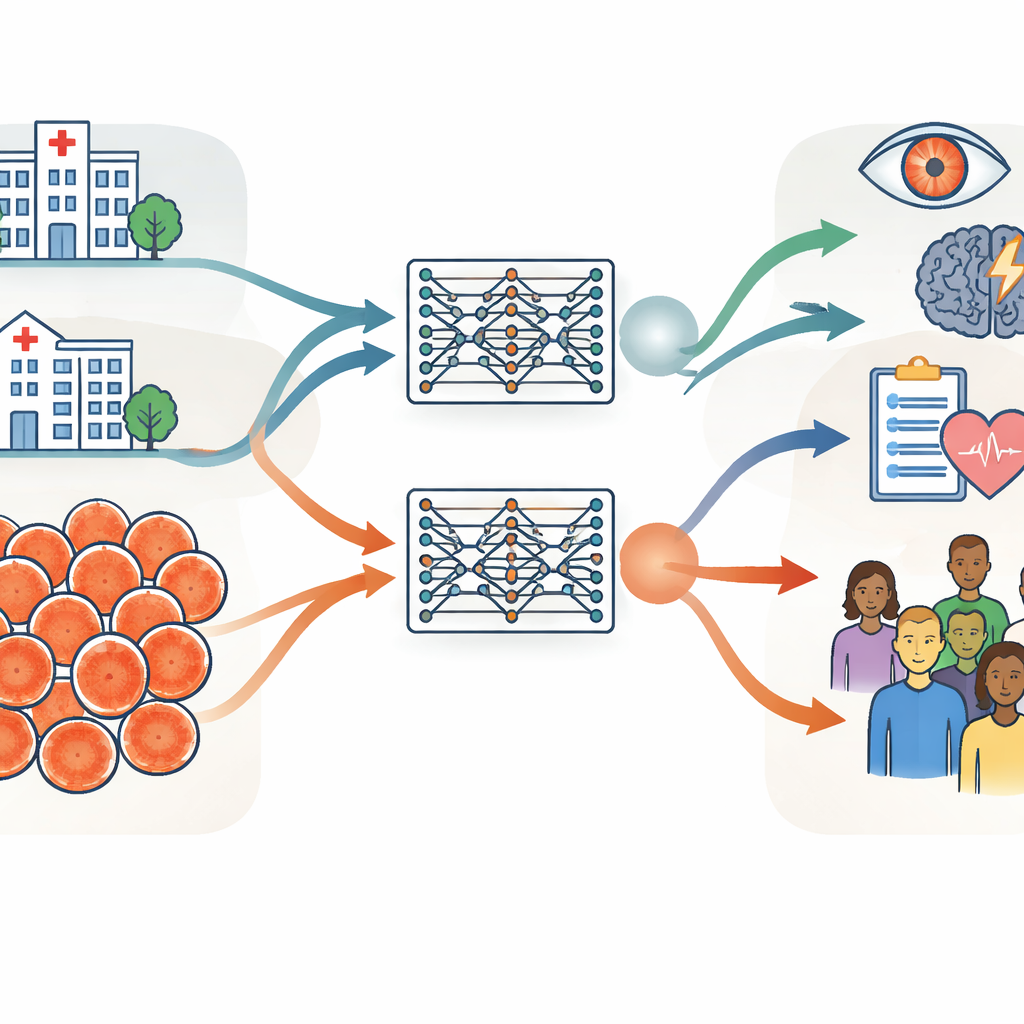
Deux immenses collections d’images oculaires sur différents continents
Les chercheurs ont structuré leur investigation autour de deux très grandes collections de photographies rétiniennes, chacune contenant environ 900 000 images. L’une provenait du Moorfields Eye Hospital au Royaume-Uni, un hôpital spécialisé où les patients ont tendance à être plus âgés et à présenter davantage de maladies oculaires. L’autre provenait du Shanghai Diabetes Prevention Program en Chine, un programme de dépistage communautaire avec des adultes plus jeunes et majoritairement en bonne santé. Outre l’âge et l’état de santé, les groupes différaient par la répartition des sexes, la composition ethnique et les appareils photo utilisés pour prendre les images. L’équipe a soigneusement mesuré ces différences à l’aide d’informations basiques comme l’âge et le sexe, de caractéristiques d’image dérivées par ordinateur et de mesures cliniquement significatives des vaisseaux sanguins et du nerf optique au fond de l’œil.
Entraîner des modèles jumeaux pour tester la performance générale
En utilisant des procédures d’entraînement identiques, le groupe a créé deux modèles fondamentaux rétiniens “jumeaux” : l’un entraîné uniquement sur les images de l’hôpital britannique et l’autre uniquement sur les images du dépistage chinois. Les deux modèles ont appris de manière autodirigée à partir de scans non étiquetés, puis ont été adaptés à des tâches spécifiques comme la détection des maladies oculaires diabétiques et la prédiction du risque d’AVC. Le test clé était de vérifier si un modèle entraîné dans un contexte pouvait encore bien fonctionner lorsqu’il était appliqué aux données de l’autre contexte ou à des jeux de données publics collectés dans plusieurs autres pays. Pour la plupart des tâches et des jeux de données, les deux modèles ont obtenu des performances similaires, même lorsqu’ils étaient évalués sur des images assez différentes de celles qu’ils avaient vues auparavant. Cela suggère que les modèles fondamentaux rétiniens, une fois entraînés sur suffisamment de données, peuvent bien se généraliser entre hôpitaux, pays et types d’appareils photo.
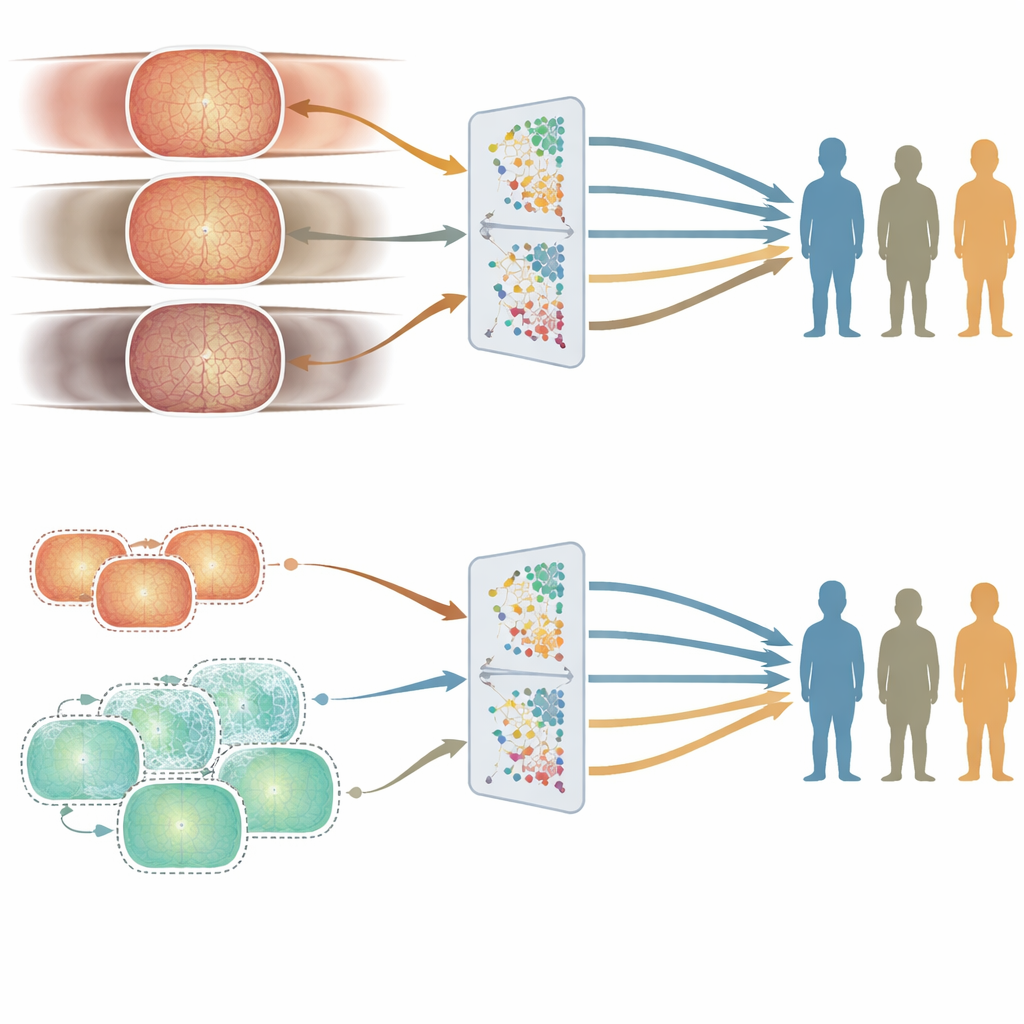
Où apparaissent les fissures d’équité : âge versus sexe et origine ethnique
Une bonne précision moyenne ne suffit pas si un système fonctionne mieux pour certaines personnes que pour d’autres. Pour sonder l’équité, les auteurs ont comparé les performances des deux modèles dans différents sous-groupes d’âge, de sexe et d’ethnicité en utilisant un ensemble de test soigneusement constitué. L’âge s’est avéré le facteur le plus important. Le modèle entraîné au Royaume-Uni, construit à partir de patients plus âgés, avait tendance à mieux fonctionner dans les tranches d’âge élevées, tandis que le modèle entraîné en Chine, construit à partir d’adultes plus jeunes, performait mieux chez les personnes plus jeunes. Ces écarts sont apparus de manière cohérente sur plusieurs tâches liées aux maladies oculaires. En revanche, les différences de performance entre hommes et femmes, ou entre grands groupes ethniques, étaient plus faibles et moins cohérentes, et ne suivaient pas de façon simple la représentation de ces groupes dans les données d’entraînement.
Comment l’œil lui-même change avec l’âge
Pour comprendre pourquoi l’âge avait un effet aussi marqué, l’équipe a examiné comment l’apparence de la rétine variait avec l’âge dans les jeux d’entraînement. Ils ont regardé à la fois des mesures cliniques — comme la complexité et le ramification des vaisseaux sanguins — et des caractéristiques abstraites que les modèles d’IA extraient eux-mêmes des images. Les groupes d’âge présentaient des différences claires et statistiquement significatives pour les deux types de mesures, même après contrôle du sexe et de l’ethnicité. Autrement dit, la structure de la rétine change réellement avec l’âge d’une manière que les modèles peuvent détecter. De ce fait, un modèle fortement entraîné sur une tranche d’âge donnée peut devenir plus finement ajusté à ce groupe, entraînant des écarts d’équité subtils mais importants.
Utiliser des images synthétiques pour rééquilibrer
Pour voir s’ils pouvaient réduire ces écarts liés à l’âge, les chercheurs ont généré des centaines de milliers d’images rétiniennes synthétiques conçues pour ressembler à des patients plus jeunes. Ils les ont mélangées avec des images hospitalières réelles pour créer un ensemble d’entraînement plus équilibré en âge, puis ont entraîné un nouveau modèle. La performance globale est restée similaire, mais la précision pour les personnes plus jeunes s’est améliorée sur certaines tâches, réduisant l’injustice entre les tranches d’âge. Cette expérience suggère que l’ajout soigneux de données synthétiques peut aider à lisser les angles morts de l’IA médicale sans nécessiter la collecte de beaucoup plus d’images réelles.
Ce que cela signifie pour l’avenir de l’IA médicale
L’étude montre que le “régime” de données fourni aux systèmes d’IA médicale façonne fortement non seulement leur puissance, mais aussi qui en bénéficie le plus. Les modèles fondamentaux rétiniens peuvent fonctionner de manière robuste entre pays et appareils, ce qui est encourageant pour une utilisation mondiale. En même temps, ce travail révèle que certains attributs des données — ici l’âge — ont un impact plus important sur l’équité que d’autres. Pour les patients et les cliniciens, le message est que la transparence sur les données d’entraînement et l’équilibrage délibéré des caractéristiques clés sont essentiels si l’on veut des outils d’IA qui servent équitablement des personnes de tous âges.
Citation: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
Mots-clés: imagerie rétinienne, justice en IA médicale, modèles fondamentaux, données de pré-entraînement, rétinopathie diabétique