Clear Sky Science · it
Comprendere gli effetti dei dati di pre-addestramento nei modelli fondamentali retinici usando due grandi coorti di fondo oculare
Perché le scansioni oculari e i dati di addestramento dell’IA contano
Le scansioni oculari vengono sempre più spesso utilizzate non solo per individuare malattie dell’occhio, ma anche per rivelare indizi sul nostro stato di salute generale, dal diabete al rischio di ictus. Sistemi di intelligenza artificiale potenti, detti modelli fondamentali, possono apprendere da milioni di queste immagini e poi essere adattati a molteplici compiti medici. Questo studio pone una domanda semplice ma importante: il tipo di dati che usiamo per addestrare questi modelli — chi sono i pazienti, da dove provengono e come appaiono le loro scansioni — cambia l’efficacia e l’equità dei modelli?
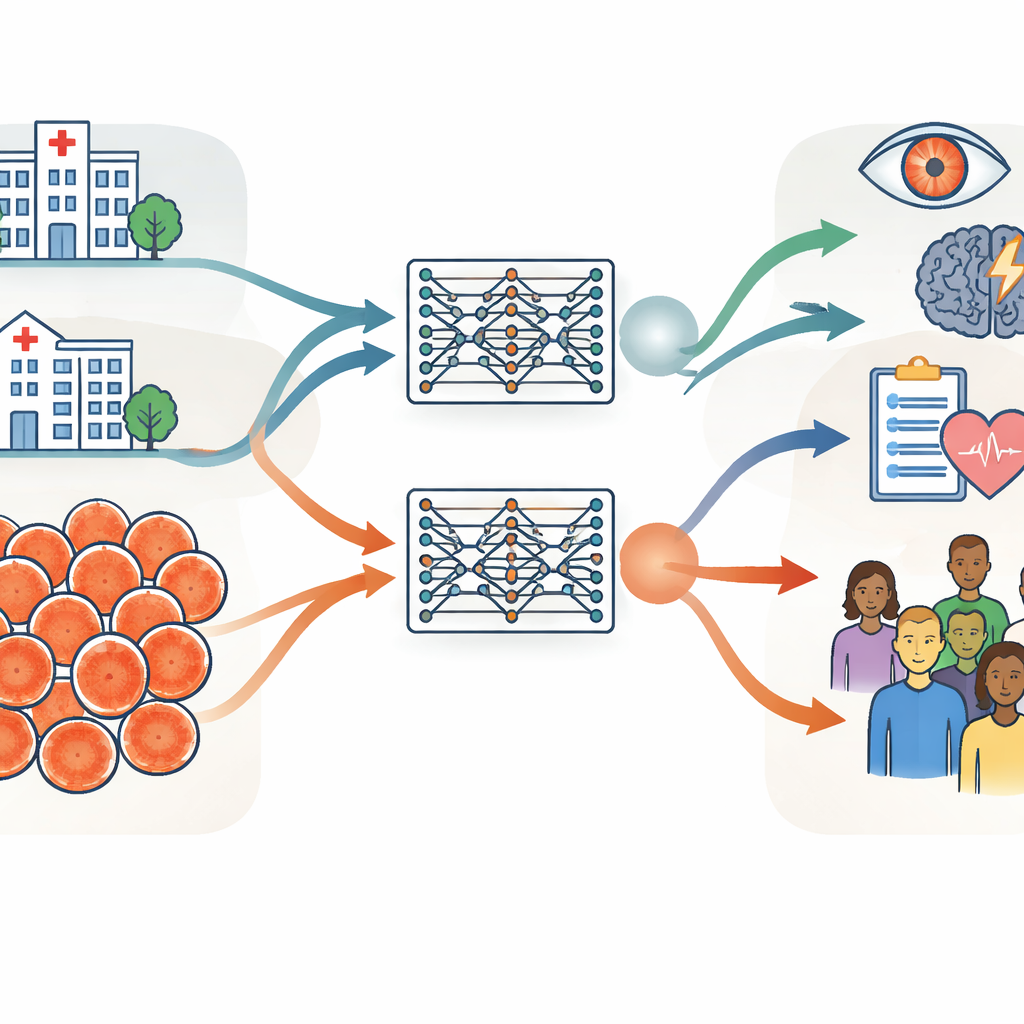
Due enormi collezioni di immagini oculari in continenti diversi
I ricercatori hanno costruito la loro indagine attorno a due collezioni molto ampie di fotografie retiniche, ciascuna contenente circa 900.000 immagini. Una proveniva dal Moorfields Eye Hospital nel Regno Unito, un ospedale specialistico dove i pazienti tendono a essere più anziani e con più patologie oculari. L’altra proveniva dallo Shanghai Diabetes Prevention Program in Cina, un programma di screening comunitario con adulti più giovani e per lo più sani. Oltre all’età e allo stato di salute, i gruppi differivano per equilibrio di genere, composizione etnica e dispositivi fotografici utilizzati per acquisire le immagini. Il team ha misurato con cura queste differenze usando informazioni di base come età e sesso, caratteristiche dell’immagine derivate dal computer e misure clinicamente significative dei vasi sanguigni e del nervo ottico sul retro dell’occhio.
Addestrare modelli gemelli per testare le prestazioni generali
Utilizzando procedure di addestramento identiche, il gruppo ha creato due modelli fondamentali retinici “gemelli”: uno addestrato solo sulle immagini dell’ospedale del Regno Unito e uno solo sulle immagini dello screening cinese. Entrambi i modelli hanno appreso in modo autodiretto da scansioni non etichettate, per poi essere adattati a compiti specifici come rilevare malattie retiniche diabetiche e prevedere il rischio di ictus. Il test chiave era verificare se un modello addestrato in un contesto potesse ancora funzionare bene applicandolo a dati provenienti dall’altro contesto o a set pubblici raccolti in diversi altri paesi. Nella maggior parte dei compiti e dei dataset, i due modelli hanno mostrato prestazioni simili, anche quando valutati su immagini piuttosto diverse da quelle viste in addestramento. Questo suggerisce che i modelli fondamentali retinici, una volta addestrati con dati sufficienti, possono generalizzare bene tra ospedali, paesi e tipi di fotocamere.
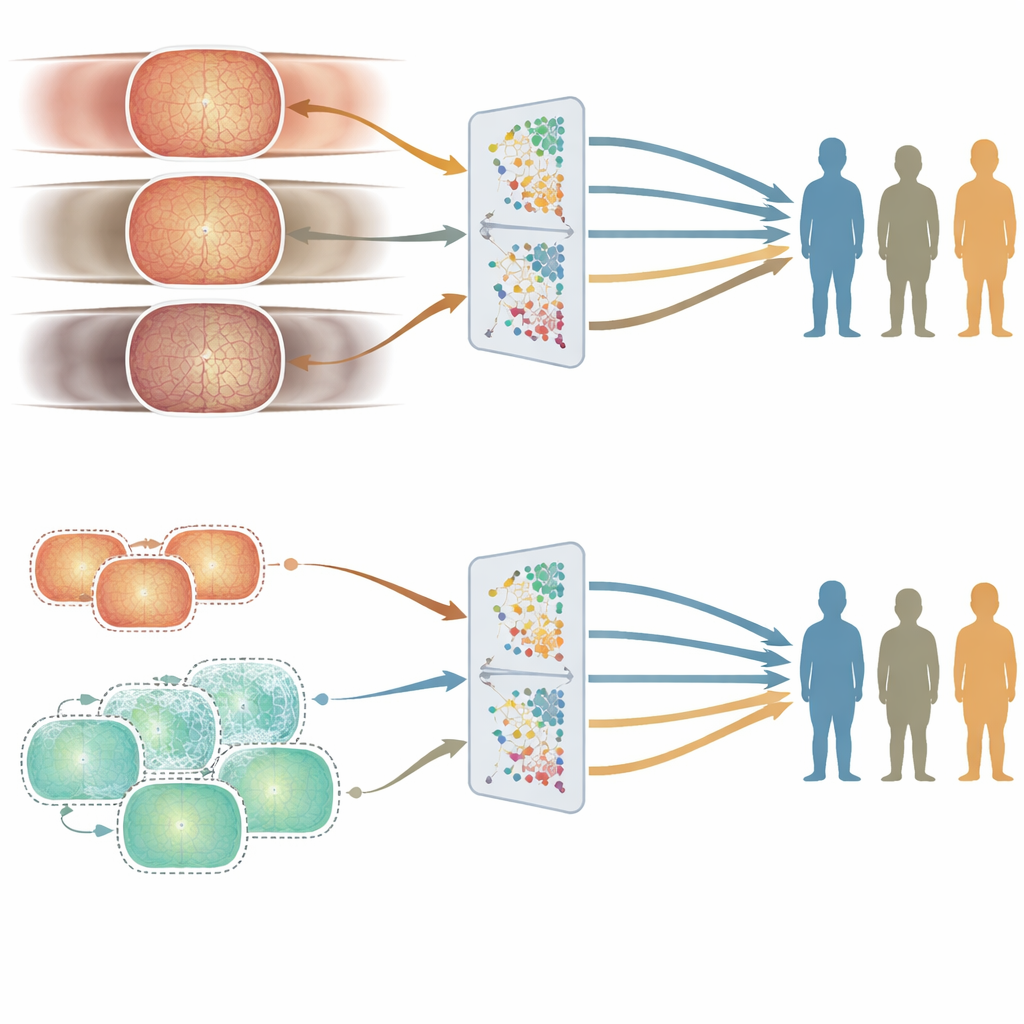
Dove emergono crepe nell’equità: età rispetto a sesso ed etnia
Una buona accuratezza media non basta se un sistema funziona meglio per alcune persone rispetto ad altre. Per sondare l’equità, gli autori hanno confrontato le prestazioni dei due modelli in diversi sottogruppi per età, sesso ed etnia usando un set di test accuratamente curato. L’età si è rivelata il fattore più rilevante. Il modello addestrato nel Regno Unito, costruito su pazienti più anziani, tendeva a performare meglio nei gruppi di età più avanzata, mentre il modello cinese, basato su adulti più giovani, otteneva risultati migliori nei soggetti più giovani. Questi divari sono comparsi in modo coerente in diversi compiti relativi alle malattie oculari. Al contrario, le differenze di prestazione tra uomini e donne, o tra i principali gruppi etnici, erano più piccole e meno coerenti, e non seguivano in modo semplice la rappresentanza di quei gruppi nei dati di addestramento.
Come l’occhio stesso cambia con l’età
Per capire perché l’età avesse un impatto così marcato, il team ha esaminato come l’aspetto della retina variava con l’età nei set di addestramento. Hanno analizzato sia misure cliniche — come la complessità e il grado di ramificazione dei vasi sanguigni — sia caratteristiche astratte che i modelli di IA estraggono dalle immagini. I gruppi per età mostravano differenze chiare e statisticamente significative in entrambi i tipi di misure, anche dopo aver controllato per sesso ed etnia. In altre parole, la struttura della retina cambia davvero con l’età in modo rilevabile dai modelli. Per questo motivo, un modello fortemente addestrato su una fascia d’età può divenire più finemente sintonizzato su quel gruppo, portando a discrepanze di equità sottili ma importanti.
Usare immagini sintetiche per riequilibrare
Per verificare se fosse possibile ridurre questi divari legati all’età, i ricercatori hanno generato centinaia di migliaia di immagini retiniche sintetiche progettate per assomigliare a pazienti più giovani. Le hanno mescolate con immagini ospedaliere reali per creare un set di addestramento più bilanciato per età e hanno quindi addestrato un nuovo modello. Le prestazioni complessive sono rimaste simili, ma l’accuratezza per i soggetti più giovani è migliorata in alcuni compiti, riducendo l’iniquità tra le fasce d’età. Questo esperimento suggerisce che l’aggiunta mirata di dati sintetici può aiutare a colmare punti ciechi nell’IA medica senza la necessità di raccogliere un gran numero di nuove immagini reali.
Cosa significa questo per il futuro dell’IA medica
Lo studio mostra che la “dieta” di dati fornita ai sistemi di IA medica plasma fortemente non solo quanto sono potenti, ma anche chi ne beneficia maggiormente. I modelli fondamentali retinici possono funzionare in modo robusto tra paesi e dispositivi, il che è incoraggiante per un uso globale. Allo stesso tempo, il lavoro rivela che alcune caratteristiche dei dati — in questo caso l’età — hanno un impatto maggiore sull’equità rispetto ad altre. Per pazienti e clinici, il messaggio è che la trasparenza sui dati di addestramento e il bilanciamento intenzionale delle caratteristiche chiave sono essenziali se vogliamo strumenti di IA che servano equamente persone di tutte le età.
Citazione: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
Parole chiave: imaging retinico, equa intelligenza artificiale medica, modelli fondamentali, dati di pre-addestramento, retinopatia diabetica