Clear Sky Science · sv
Förstå effekterna av förträningsdata i retinala foundation-modeller med två stora funduskohorter
Varför ögonskanningar och AI-träningsdata spelar roll
Ögonskanningar används i allt större utsträckning inte bara för att upptäcka ögonsjukdomar, utan också för att ge ledtrådar om vår allmänna hälsa, från diabetes till risk för stroke. Kraftfulla artificiella intelligenssystem, så kallade foundation-modeller, kan lära sig från miljontals sådana bilder och därefter anpassas till många medicinska uppgifter. Den här studien ställer en enkel men viktig fråga: förändrar typen av data vi använder för att träna dessa modeller — vilka patienter som ingår, var de kommer ifrån och hur deras skanningar ser ut — hur väl och hur rättvist modellerna fungerar?
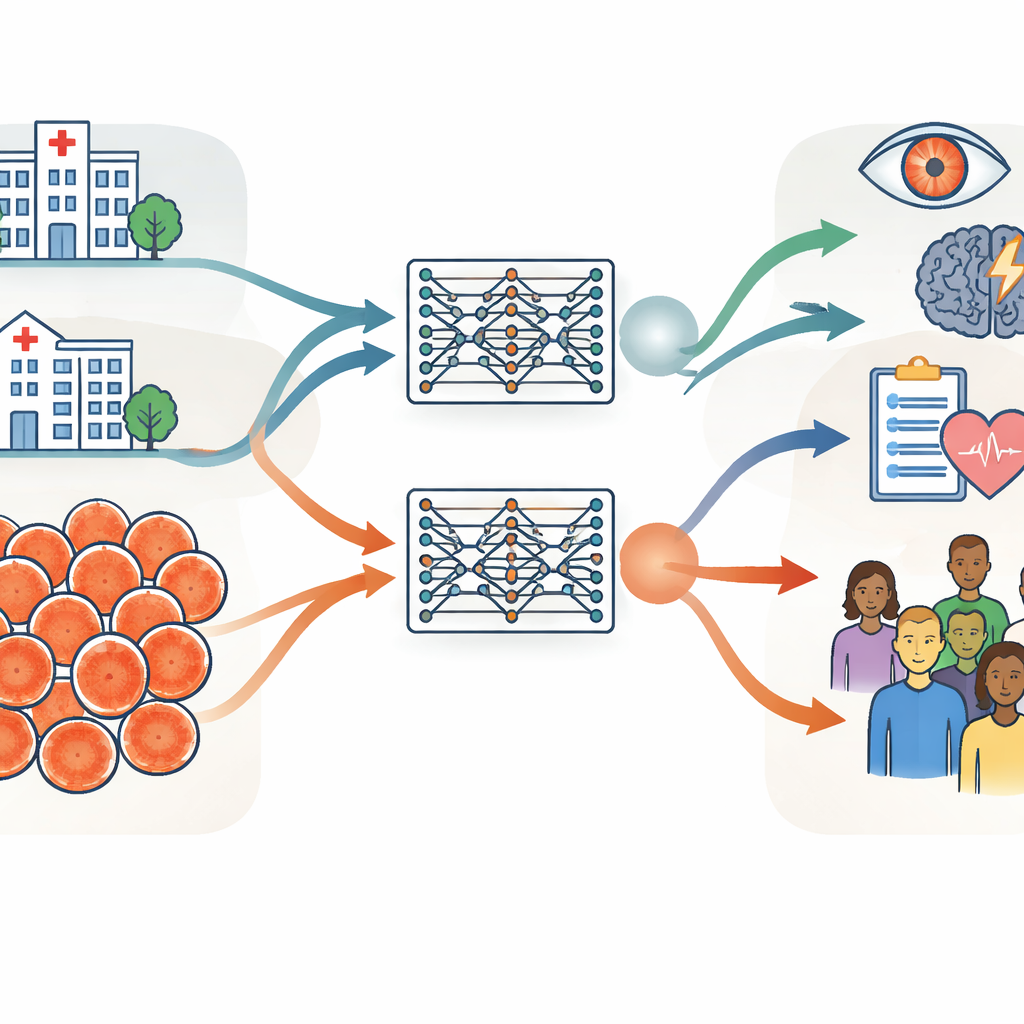
Två enorma samlingar av ögonbilder på olika kontinenter
Forskarna byggde sin undersökning kring två mycket stora samlingar av retinalfotografier, vardera med omkring 900 000 bilder. Den ena kom från Moorfields Eye Hospital i Storbritannien, ett specialistcentrum där patienterna tenderar att vara äldre och ha mer ögonsjukdom. Den andra kom från Shanghai Diabetes Prevention Program i Kina, ett samhällsbaserat screeningsprogram med yngre, oftast friska vuxna. Utöver ålder och hälsa skiljde sig grupperna åt i könsfördelning, etnisk sammansättning och de kameror som användes för att ta bilderna. Teamet mätte dessa skillnader noggrant med hjälp av grundläggande uppgifter som ålder och kön, datorgenererade bildfunktioner och kliniskt meningsfulla mått på blodkärlen och synnerven i ögats bakre del.
Träna tvilling-AI-modeller för att testa generell prestanda
Med identiska träningsprocedurer skapade gruppen två ”tvilling”-retinala foundation-modeller: en tränad endast på de brittiska sjukhusbilderna och en endast på de kinesiska screeningbilderna. Båda modellerna lärde sig självstyrt från omärkta skanningar och anpassades sedan till specifika uppgifter, såsom att upptäcka diabetisk ögonsjukdom och förutse strokerisk. Det viktigaste testet var om en modell tränad i ena miljön fortfarande kunde prestera väl när den tillämpades på data från den andra miljön eller från publika dataset insamlade i flera andra länder. I de flesta uppgifter och dataset presterade de två modellerna likartat, även när de utvärderades på bilder som var ganska olika dem de sett tidigare. Det tyder på att retinala foundation-modeller, när de väl tränats på tillräckligt mycket data, kan generalisera väl över sjukhus, länder och kameratyper.
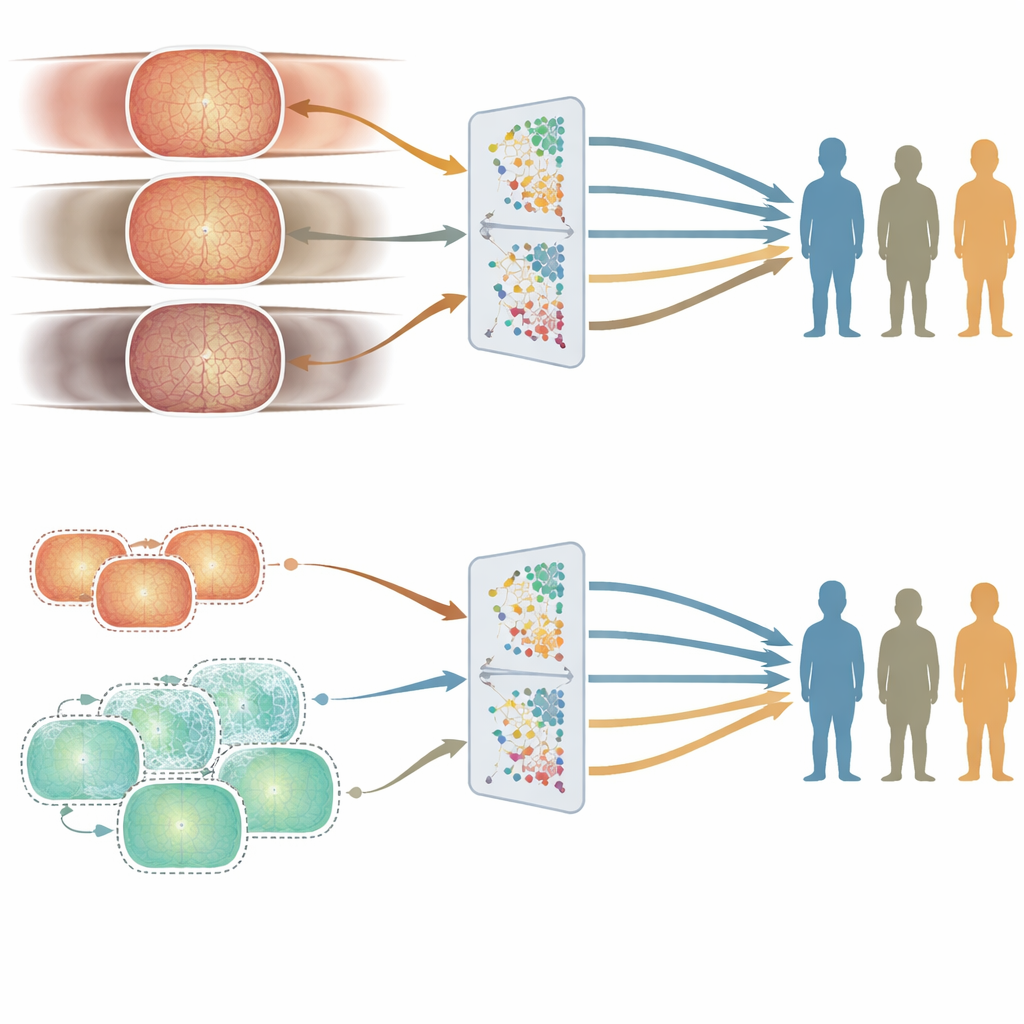
Var ojämlikheter uppstår: ålder kontra kön och etnicitet
God genomsnittlig noggrannhet räcker inte om ett system fungerar bättre för vissa personer än för andra. För att undersöka rättvisa jämförde författarna hur de två modellerna presterade i olika ålders-, köns- och etniska delgrupper med hjälp av en noggrant kurerad testuppsättning. Ålder visade sig spela störst roll. Den UK-tränade modellen, byggd på äldre patienter, presterade tendentiellt bättre i äldre åldersgrupper, medan Kina-tränade modellen, byggd på yngre vuxna, fungerade bättre för yngre personer. Dessa skillnader återkom konsekvent över flera ögonsjukdomsuppgifter. I kontrast var prestandaskillnader mellan män och kvinnor, eller mellan större etniska grupper, mindre och mindre konsekventa, och följde inte på något enkelt sätt hur dessa grupper var representerade i träningsdatan.
Hur ögat självt förändras med åldern
För att förstå varför ålder hade så stark effekt undersökte teamet hur retinas utseende varierade med ålder i träningsdatabasen. De studerade både kliniska mått — som hur komplex och förgrenad kärlstrukturen var — och abstrakta funktioner som AI-modellerna själva extraherar från bilderna. Åldersgrupper visade tydliga och statistiskt signifikanta skillnader i båda typerna av mått, även efter kontroll för kön och etnicitet. Med andra ord ändrar sig retinas struktur verkligen med åldern på ett sätt som modellerna kan upptäcka. På grund av detta kan en modell som i hög grad tränats på ett visst åldersintervall bli mer finjusterad för den gruppen, vilket leder till subtila men viktiga rättviseskillnader.
Använda syntetiska bilder för att jämna ut förutsättningarna
För att se om de kunde minska dessa åldersrelaterade skillnader genererade forskarna hundratusentals syntetiska retinalbilder utformade för att likna yngre patienter. De blandade dessa med verkliga sjukhusbilder för att skapa en mer åldersbalanserad träningsuppsättning och tränade därefter en ny modell. Den övergripande prestandan förblev liknande, men noggrannheten för yngre personer förbättrades i vissa uppgifter, vilket minskade orättvisorna mellan åldersgrupperna. Denna experimentella demonstration tyder på att ett noggrant tillskott av syntetiska data kan hjälpa till att jämna ut blinda fläckar i medicinsk AI utan att behöva samla in mycket fler verkliga bilder.
Vad detta betyder för framtidens medicinska AI
Studien visar att ”kosten” av data som matas in i medicinska AI-system starkt påverkar inte bara hur kraftfulla de är, utan också vilka som gynnas mest av dem. Retinala foundation-modeller kan fungera robust över länder och enheter, vilket är uppmuntrande för global användning. Samtidigt visar arbetet att vissa dataegenskaper — i detta fall ålder — har större inverkan på rättvisa än andra. För patienter och kliniker är budskapet att transparens kring träningsdata och avsiktlig balansering av nyckelkarakteristika är avgörande om vi vill ha AI-verktyg som tjänar människor i alla åldrar rättvist.
Citering: Zhou, Y., Wang, Z., Wu, Y. et al. Understanding pre-training data effects in retinal foundation models using two large fundus cohorts. Nat Commun 17, 3309 (2026). https://doi.org/10.1038/s41467-026-70077-z
Nyckelord: retinal avbildning, medicinsk AI-rättvisa, foundation-modeller, förträningsdata, diabetisk retinopati