Clear Sky Science · zh
TamilSTARNet:通过三阶段架构分割与基于注意力的识别处理手写泰米尔字符
将古老的泰米尔书写带入数字时代
在南印度及更远的地方,许多珍贵的故事、诗篇和记录以泰米尔文手写在逐渐褪色的纸张、棕榈叶和笔记本里,难以读取。由于大量材料是手写的,计算机难以识别,从而导致泰米尔文化的大量内容难以被检索、共享或研究。本文介绍了 TamilSTARNet——一个专门为识别手写泰米尔而设计的新型计算机视觉系统,旨在将数百年的文化遗产保存并以数字形式提供访问。
为什么手写泰米尔对计算机来说很难
泰米尔文字丰富且富有表现力:一小组基本元音和辅音可以组合成超过300个复合字符。在纸面上,这些字母通过环、曲线以及位于主笔画上方、下方或旁边的小符号相互连接。人们以许多个人风格书写,笔画可能连接、重叠或粗细不一。标准光学字符识别(OCR)工具在整齐印刷的英文文本上表现良好,但在这里常常失灵:它们会误读相连的字母、漏掉改变含义的小符号,并在墨迹褪色或间距不规则时出错。现有针对泰米尔的研究虽然通过手工规则或通用神经网络取得了一些进展,但大多数方法要么假定字符已被干净地逐个切分,要么在字符相互接触、拥挤时崩溃。
一种三步走的页面切分方法
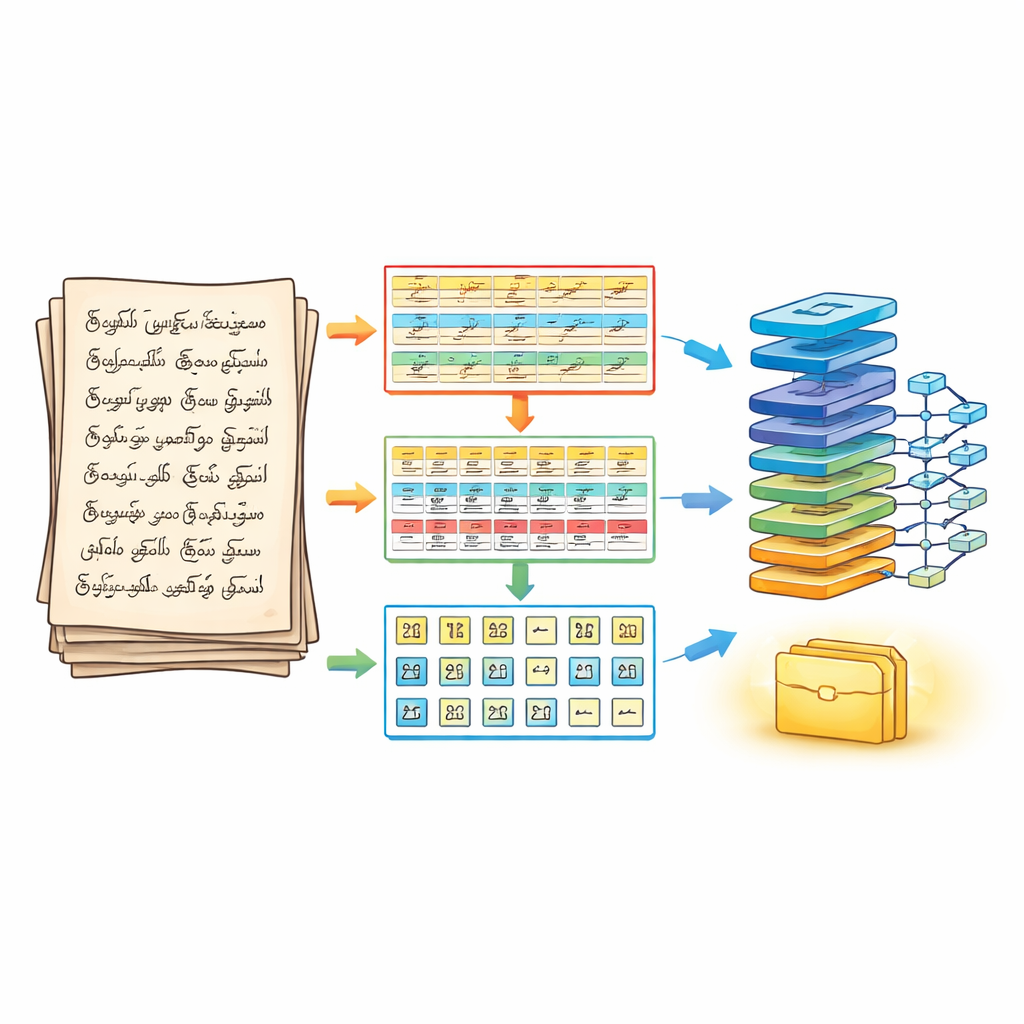
为了解决这个问题,作者首先重新设计了在任何识别之前对页面的切分方式。他们的三阶段分割流水线将手写文档视为一个分层的拼图。第一阶段,使用标准图像处理步骤对页面进行去噪和锐化,然后将其分割成水平的文本行。第二阶段,对每一行进行拆分为单词,谨慎调整相邻笔画的合并程度,以免丢失微小的元音符号。第三阶段,使用轮廓和包围框根据实际墨迹笔画进一步将每个单词切分为单个字符。结果是一个结构化的三维数组——行、词、字符——既保留阅读顺序,又为识别引擎提供清晰分离的字符。
一种让计算机更聪明地“注意”笔画的方法
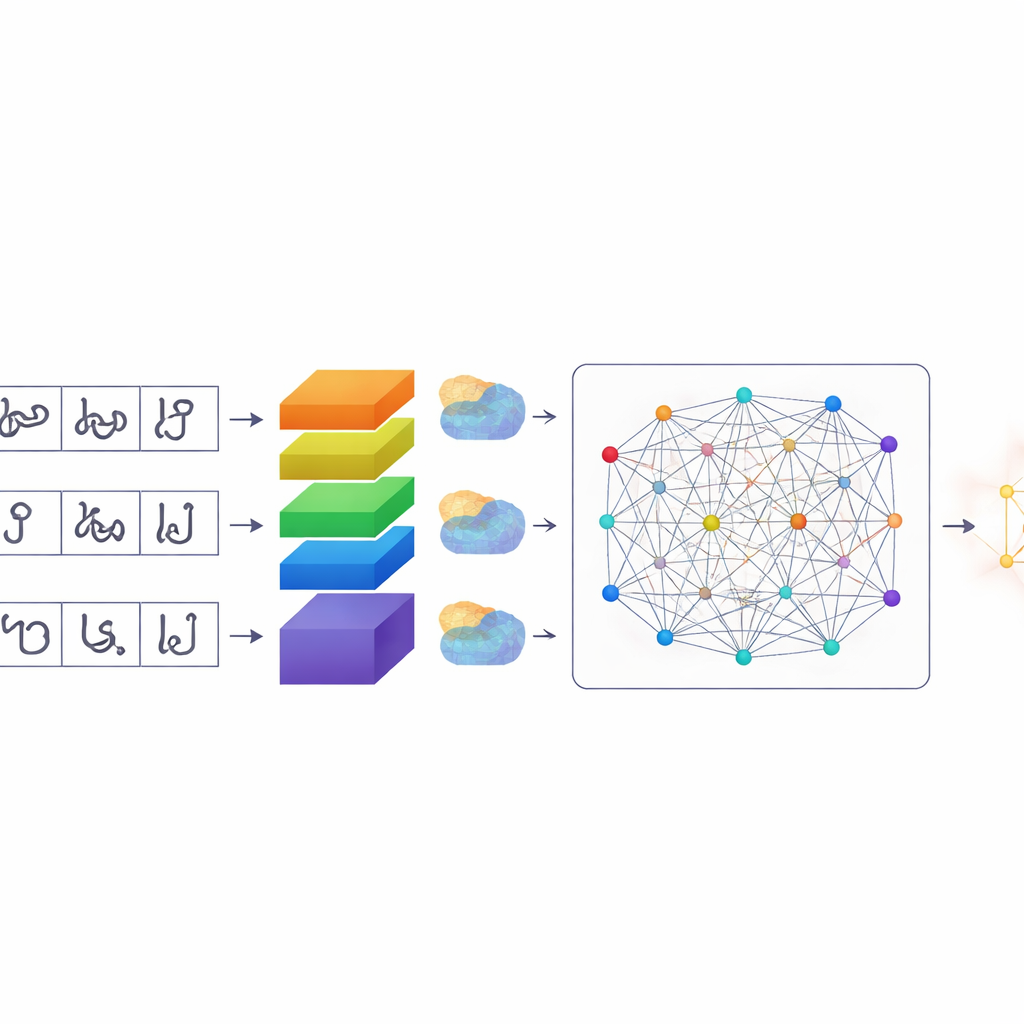
字符分割完成后,TamilSTARNet 使用一个定制的深度学习模型来识别每个字符。其核心是一组卷积层,从图像中学习视觉模式。在此基础上,作者加入了几种注意力机制。这些模块帮助网络决定图像的哪些部分和哪些内部特征最为重要。一个组件强调捕捉细微笔画差异的特定通道——正是那些区分相似泰米尔字母的小钩和环;另一个组件关注重要笔画在字符表面的位置;最后的自注意力层则在整个字符范围内进行全局关联,连接那些共同定义字符形状的远端笔画。通过结合这些注意力形式,系统能更好地区分仅由细小符号或曲线差异之处的字符。
系统的表现如何
研究者在两个大型公开数据集上测试了 TamilSTARNet,这些数据集合计包含超过160,000个样本,覆盖来自数百名书写者的156个字符类别。训练后,模型在测试字符上的识别率约为96%,优于诸如 Tesseract OCR 以及若干深度神经网络基线方法。三阶段分割也被证明至关重要:当在没有这种细致行–词–字符切分的情况下使用相同识别模型时,准确性和可靠性都会下降。团队还在具有挑战性的棕榈叶手稿上评估了他们的方法——该类材料墨迹微弱、表面不规则——虽在这种苛刻条件下性能自然较低,但仍足以表明该方法可扩展到真实的历史材料。
这对保存泰米尔遗产意味着什么
简而言之,TamilSTARNet 为计算机观察手写泰米尔提供了一种更为审慎的方式:它先将凌乱的页面组织为分离良好的部分,然后针对重要笔画对每个字符进行有针对性的关注。这种组合使系统比以往工具更可靠地读取复杂手写。虽然仍存在困难情形——例如高度程式化的书写或严重损坏的页面——但该方法标志着朝着大规模泰米尔文本数字化迈出的切实一步。随着此类系统的改进与推广,旧笔记本、信件和手稿可以被转化为可搜索的数字图书馆,帮助确保泰米尔的文学遗产不仅免于物理腐朽,而且更便于后代探索。
引用: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
关键词: 泰米尔手写 OCR, 文档数字化, 基于注意力的神经网络, 文化遗产保护, 文字识别