Clear Sky Science · pt
TamilSTARNet: segmentação via arquitetura em três fases e reconhecimento baseado em atenção para caracteres manuscritos tâmil
Levando a escrita tâmil antiga para a era digital
Por todo o sul da Índia e além, histórias, poemas e registros preciosos escritos em tâmil permanecem presos em papéis desbotados, folhas de palmeira e cadernos. Como grande parte desse material é manuscrita, os computadores têm dificuldade para lê‑lo, o que faz com que vastas porções da cultura tâmil sejam difíceis de buscar, compartilhar ou estudar. Este artigo apresenta o TamilSTARNet, um novo sistema de visão computacional projetado especificamente para ler manuscritos tâmil, para que séculos de patrimônios possam ser preservados e acessados em formato digital.
Por que o tâmil manuscrito é difícil para computadores
O alfabeto tâmil é rico e expressivo: um pequeno conjunto de vogais e consoantes básicas combina em mais de 300 caracteres compostos. Na página, essas letras fluem juntas com laços, curvas e pequenos sinais acima, abaixo e ao lado dos traços principais. As pessoas escrevem em estilos pessoais variados, com traços que se juntam, se sobrepõem ou variam em espessura. Ferramentas padrão de Reconhecimento Óptico de Caracteres (OCR), que funcionam bem em textos impressos e organizados em inglês, frequentemente falham aqui. Elas interpretam mal letras unidas, perdem pequenos sinais que mudam o significado e tropeçam quando a tinta está desbotada ou o espaçamento é irregular. Pesquisas existentes para o tâmil avançaram usando regras feitas à mão ou redes neurais genéricas, mas a maioria dos métodos assume caracteres limpos recortados individualmente ou entra em colapso quando os caracteres tocam e se aglomeram.
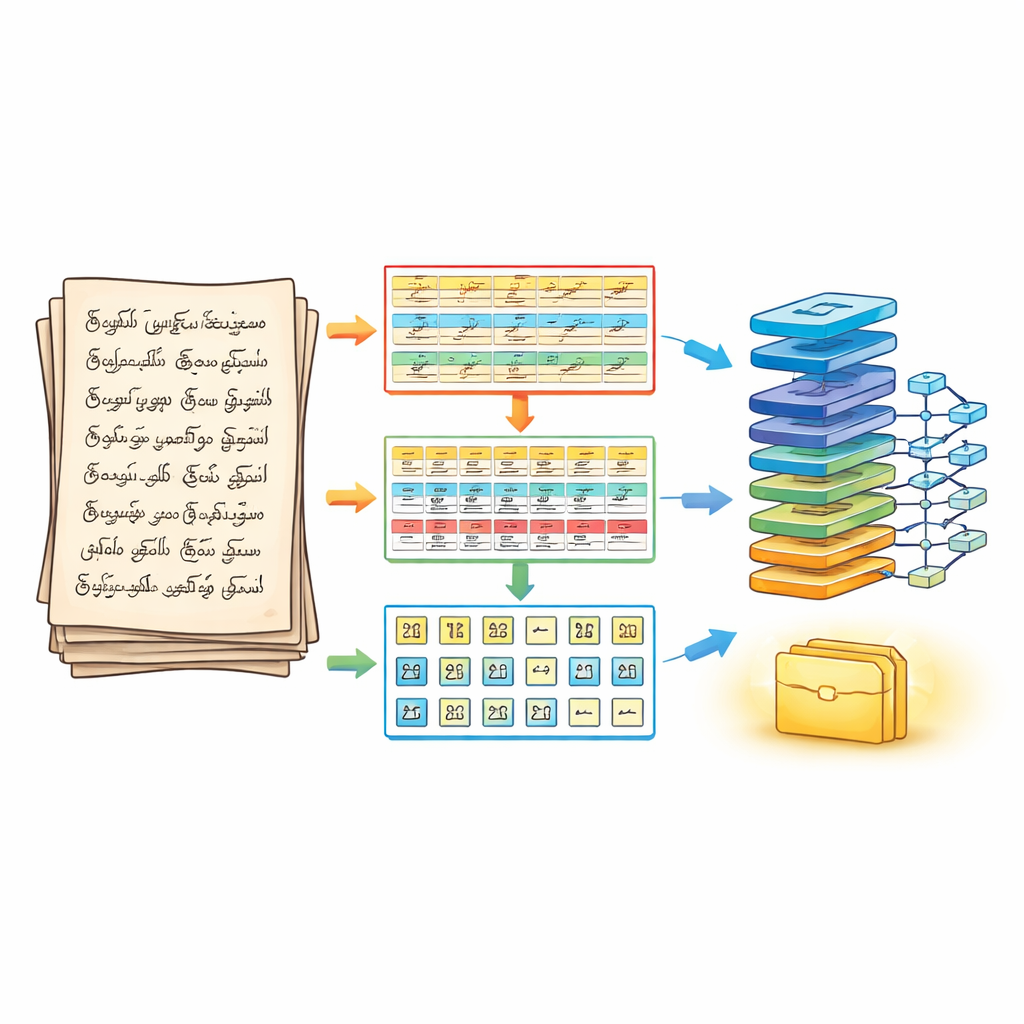
Uma maneira em três etapas para fatiar a página
Para enfrentar esse problema, os autores redesenham antes como a página é dividida antes de qualquer reconhecimento. Seu pipeline de segmentação em três fases trata um documento manuscrito como um quebra‑cabeça em camadas. Na primeira fase, a página é limpa e realçada usando passos padrão de processamento de imagem, e então dividida em linhas horizontais de texto. Na segunda fase, cada linha é separada em palavras, ajustando cuidadosamente o quanto traços vizinhos são mesclados para que pequenos sinais vocálicos não se percam. Na terceira fase, cada palavra é ainda segmentada em caracteres individuais usando contornos e caixas delimitadoras que seguem os traços reais de tinta. O resultado é um arranjo tridimensional estruturado — linha, palavra, caractere — que preserva a ordem de leitura enquanto fornece caracteres claramente isolados ao motor de reconhecimento.
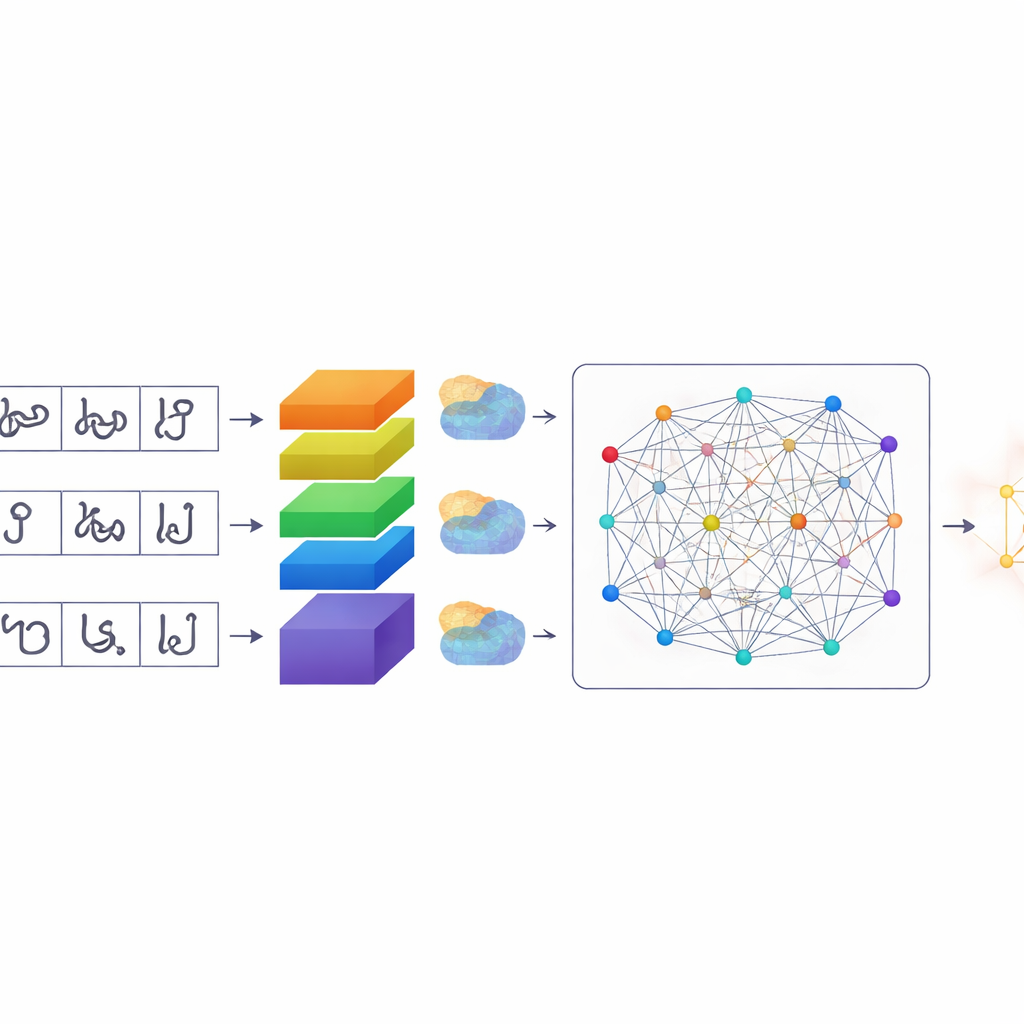
Uma forma mais inteligente de os computadores prestarem atenção
Uma vez segmentados os caracteres, o TamilSTARNet usa um modelo de deep learning ajustado para identificar cada um deles. No núcleo há uma pilha de camadas convolucionais que aprendem padrões visuais a partir das imagens. Sobre isso, os autores adicionam diversos tipos de mecanismos de “atenção”. Esses módulos ajudam a rede a decidir quais partes da imagem e quais características internas importam mais. Um componente destaca canais específicos que capturam diferenças sutis de traço — exatamente os pequenos ganchos e laços que distinguem letras tâmil semelhantes. Outro componente foca em onde os traços importantes se situam na superfície do caractere. Uma camada final de auto‑atenção observa o caractere por inteiro, ligando traços distantes que juntos definem sua forma. Ao combinar essas formas de atenção, o sistema fica melhor em separar caracteres que diferem apenas por um pequeno sinal ou curva.
Como o sistema se sai
Os pesquisadores testaram o TamilSTARNet em dois grandes conjuntos de dados públicos que juntos contêm mais de 160.000 exemplos cobrindo 156 classes de caracteres de centenas de escritores. Após o treinamento, o modelo reconheceu corretamente cerca de 96% dos caracteres de teste, superando alternativas conhecidas como o Tesseract OCR e várias linhas de base com redes neurais profundas. A segmentação em três fases também mostrou‑se importante: quando o mesmo modelo de reconhecimento foi usado sem essa divisão cuidadosa linha–palavra–caractere, a precisão e a confiabilidade caíram. A equipe avaliou ainda a abordagem em manuscritos de folhas de palmeira desafiadores, onde a tinta é fraca e as superfícies são irregulares. O desempenho foi naturalmente menor nesse cenário severo, mas ainda assim forte o suficiente para mostrar que o método pode ser estendido a materiais históricos reais.
O que isso significa para a preservação do patrimônio tâmil
Em termos simples, o TamilSTARNet oferece aos computadores uma maneira mais cuidadosa de olhar para o tâmil manuscrito: primeiro organiza a página desordenada em pedaços bem separados e, em seguida, estuda cada caractere com atenção focada nos traços que importam. Essa combinação permite que o sistema leia caligrafias complexas com muito mais confiabilidade do que ferramentas anteriores. Embora casos difíceis permaneçam — como escrita altamente estilizada ou páginas severamente danificadas — a abordagem representa um passo prático rumo à digitalização em larga escala de textos tâmil. À medida que tais sistemas melhorarem e se disseminarem, antigos cadernos, cartas e manuscritos poderão ser transformados em bibliotecas digitais pesquisáveis, ajudando a garantir que o patrimônio literário tâmil não apenas seja salvo da degradação física, mas também fique mais acessível para as gerações futuras explorarem.
Citação: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Palavras-chave: OCR manuscrita em tâmil, digitalização de documentos, redes neurais com atenção, preservação do patrimônio cultural, reconhecimento de escrita