Clear Sky Science · sv
TamilSTARNet: segmentering via trefasarkitektur och uppmärksamhetsbaserad igenkänning för handskrivna tamilska tecken
Att föra gammal tamilsk skrift in i den digitala tidsåldern
I hela södra Indien och bortom dess gränser finns värdefulla berättelser, dikter och handlingar skrivna på tamil som ligger inlåsta i bleknande papper, palmblad och anteckningsböcker. Eftersom mycket av detta material är handskrivet har datorer svårt att läsa det, vilket gör att stora delar av den tamilska kulturen förblir svåra att söka, dela eller studera. Denna artikel presenterar TamilSTARNet, ett nytt datorsynsystem särskilt utformat för att läsa handskriven tamil, så att århundraden av arv kan bevaras och göras åtkomliga i digital form.
Varför handskriven tamil är svår för datorer
Tamilskt skriftsystem är rikt och uttrycksfullt: en liten uppsättning grundläggande vokaler och konsonanter kombineras till mer än 300 sammansatta tecken. På sidan flyter dessa bokstäver ihop med slingor, kurvor och små märken ovanför, under och vid sidan av huvudstrecken. Människor skriver dem i många personliga stilar, med streck som förenas, överlappar eller varierar i tjocklek. Standardverktyg för optisk teckenigenkänning (OCR), som fungerar bra på prydligt tryckt engelska text, misslyckas ofta här. De feltolkar sammansatta tecken, förlorar små märken som ändrar betydelsen, och snubblar när bläcket är utblänt eller mellanrummen är oregelbundna. Befintlig forskning för tamil har gjort framsteg med handgjorda regler eller generiska neurala nätverk, men de flesta metoder förutsätter antingen rena tecken som är utskurna ett och ett eller fallerar när tecken rör vid och trängs ihop.
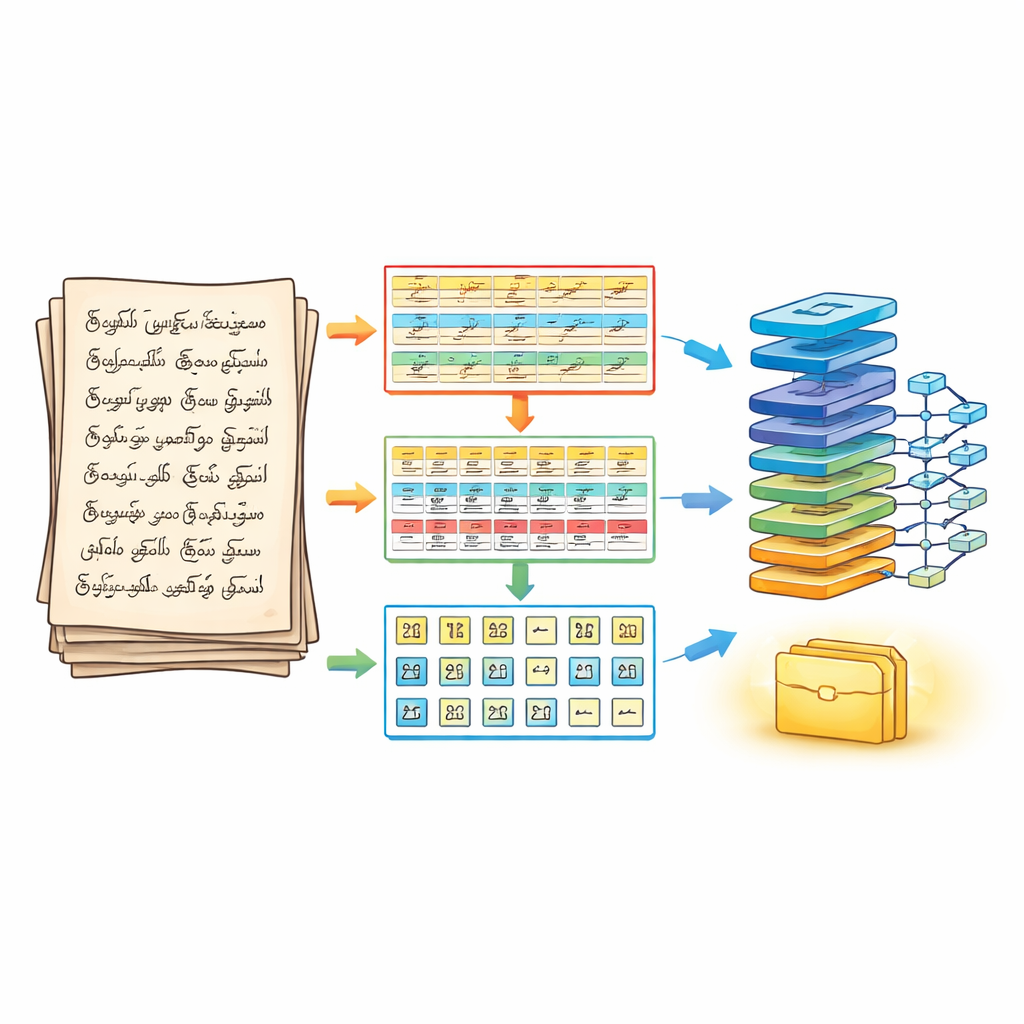
En trefasmetod för att skära upp sidan
För att tackla detta omarbetar författarna först hur en sida delas upp innan någon igenkänning sker. Deras trefasiga segmenteringspipeline behandlar ett handskrivet dokument som ett lager-på-lager-pussel. I första fasen rengörs och skärps bilden med standard bildbehandlingssteg och delas därefter in i horisontella textlinjer. I andra fasen bryts varje rad upp i separata ord, med noggrann justering av hur mycket intilliggande streck sammanslås så att små vokalmärken inte går förlorade. I tredje fasen delas varje ord ytterligare upp i individuella tecken med hjälp av konturer och avgränsningsboxar som följer de faktiska bläckstrecken. Resultatet är en strukturerad tredimensionell matris—rad, ord, tecken—som bevarar läsordningen samtidigt som klart isolerade tecken levereras till igenkänningsmotorn.
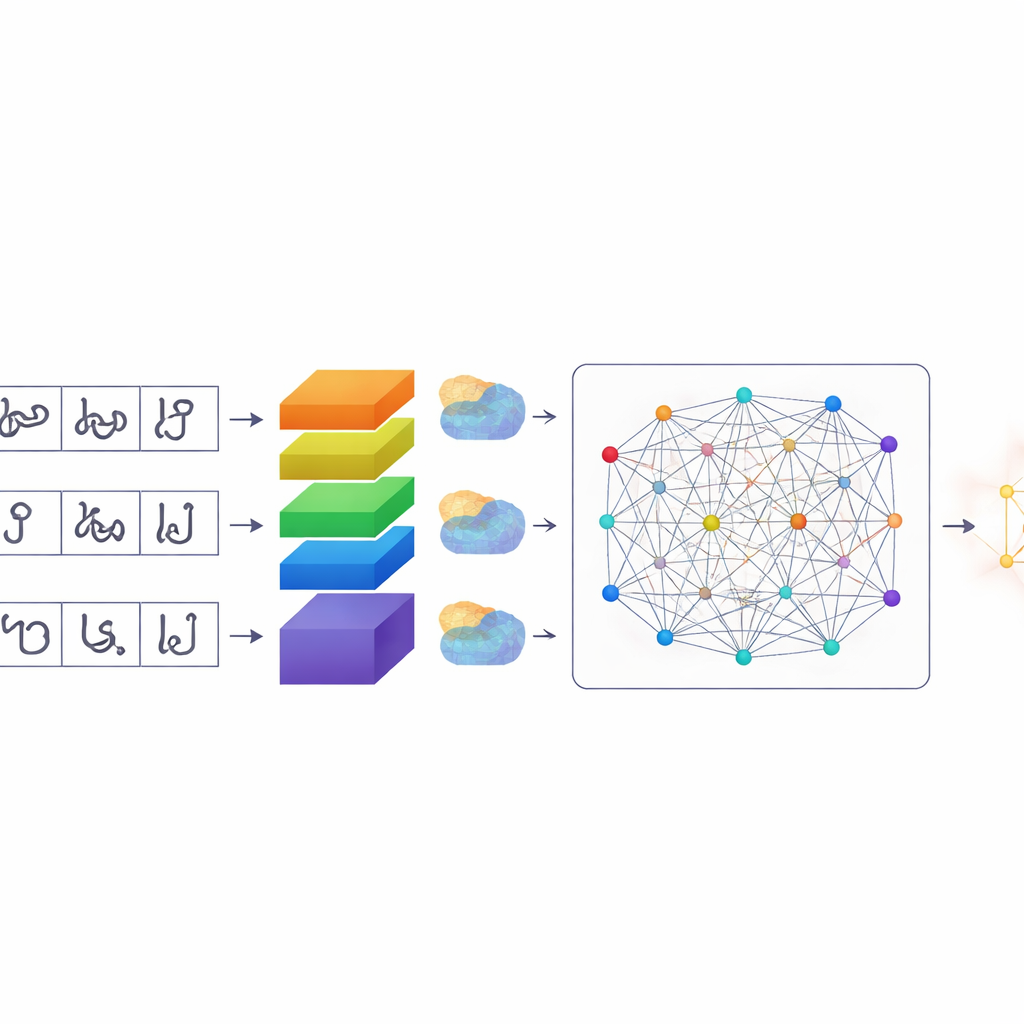
Ett smartare sätt för datorer att rikta uppmärksamhet
När tecknen har segmenterats använder TamilSTARNet en skräddarsydd djupinlärningsmodell för att avgöra vad varje tecken är. I kärnan finns en stapel av konvolutionella lager som lär sig visuella mönster från bilderna. Ovanpå detta lägger författarna flera typer av ”uppmärksamhets”mekanismer. Dessa moduler hjälper nätverket att avgöra vilka delar av bilden och vilka interna funktioner som är viktigast. En komponent framhäver specifika kanaler som fångar subtila skillnader i streck—precis de små krokarna och slingorna som skiljer liknande tamilska bokstäver åt. En annan komponent fokuserar på var viktiga streck ligger på tecknets yta. Ett slutligt självuppmärksamhetslager ser över hela tecknet på en gång och kopplar samman avlägsna streck som tillsammans definierar dess form. Genom att kombinera dessa former av uppmärksamhet blir systemet bättre på att skilja åt tecken som endast skiljer sig åt genom ett litet märke eller en kurva.
Hur väl systemet presterar
Forskarna testade TamilSTARNet på två stora publika dataset som tillsammans innehåller mer än 160 000 exempel fördelade på 156 teckenkategorier från hundratals skribenter. Efter träning kände modellen igen ungefär 96 % av testtecknen korrekt, vilket överträffade välkända alternativ som Tesseract OCR och flera djupa neurala nätverksbaslinjer. Den trefasiga segmenteringen visade sig också vara viktig: när samma igenkänningsmodell användes utan denna noggranna rad–ord–tecken-uppdelning sjönk noggrannheten och tillförlitligheten. Gruppen utvärderade vidare sin metod på utmanande palmbladsmanuskript, där bläcket är svagt och ytorna oregelbundna. Prestandan var naturligtvis lägre i denna krävande miljö men ändå tillräckligt stark för att visa att metoden kan tillämpas på verkligt historiskt material.
Vad detta betyder för bevarandet av tamilsk kultur
Förenklat ger TamilSTARNet datorer ett mer omsorgsfullt sätt att betrakta handskriven tamil: det organiserar först den stökiga sidan i välavgränsade delar, och studerar sedan varje tecken med fokuserad uppmärksamhet på de streck som är viktiga. Denna kombination gör att systemet kan läsa komplex handstil mycket mer tillförlitligt än tidigare verktyg. Medan svåra fall kvarstår—såsom mycket stiliserad skrift eller kraftigt skadade sidor—är tillvägagångssättet ett praktiskt steg mot storskalig digitalisering av tamilska texter. När sådana system förbättras och sprids kan gamla anteckningsböcker, brev och manuskript omvandlas till sökbara digitala bibliotek, vilket hjälper till att säkerställa att tamilskt litterärt arv inte bara räddas från fysisk förfall utan också blir lättare för framtida generationer att utforska.
Citering: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Nyckelord: Tamilskt handskrivet OCR, dokumentdigitalisering, uppmärksamhetsbaserade neurala nätverk, bevarande av kulturarv, skriptigenkänning