Clear Sky Science · de
TamilSTARNet: Segmentierung mittels dreiphasiger Architektur und auf Aufmerksamkeit basierender Erkennung für handgeschriebene tamilische Zeichen
Alte tamilische Schriften ins digitale Zeitalter bringen
In ganz Südindien und darüber hinaus liegen wertvolle Geschichten, Gedichte und Aufzeichnungen in Tamil verborgen in ausbleichendem Papier, Palmblättern und Notizbüchern. Da viele dieser Materialien handschriftlich sind, tun sich Computer schwer, sie zu lesen; große Teile der tamilischen Kultur bleiben dadurch nur schwer durchsuchbar, teilbar oder erforschbar. Dieses Papier stellt TamilSTARNet vor, ein neues Computer-Visionsystem, das speziell dafür entwickelt wurde, handgeschriebenes Tamil zu lesen, damit Jahrhunderte des Erbes digital bewahrt und zugänglich gemacht werden können.
Warum handgeschriebenes Tamil für Computer schwierig ist
Die tamilische Schrift ist reich und ausdrucksvoll: eine kleine Anzahl grundlegender Vokale und Konsonanten verbindet sich zu mehr als 300 zusammengesetzten Zeichen. Auf der Seite fließen diese Buchstaben mit Schleifen, Kurven und kleinen Zeichen über, unter und neben den Hauptstrichen zusammen. Menschen schreiben sie in vielen persönlichen Stilen, mit Strichen, die sich verbinden, überlappen oder in der Dicke variieren. Standard-Optische-Zeichenerkennung (OCR)-Werkzeuge, die bei ordentlich gedrucktem englischem Text gut funktionieren, versagen hier oft. Sie lesen verbundene Zeichen falsch, übersehen winzige Markierungen, die die Bedeutung ändern, und stolpern bei verblasster Tinte oder unregelmäßigem Abstand. Die bestehende Forschung zu Tamil hat Fortschritte gemacht, etwa durch handgefertigte Regeln oder allgemeine neuronale Netze, aber die meisten Methoden gehen entweder von sauber ausgeschnittenen Zeichen aus oder scheitern, wenn Zeichen sich berühren und dicht beieinander stehen.
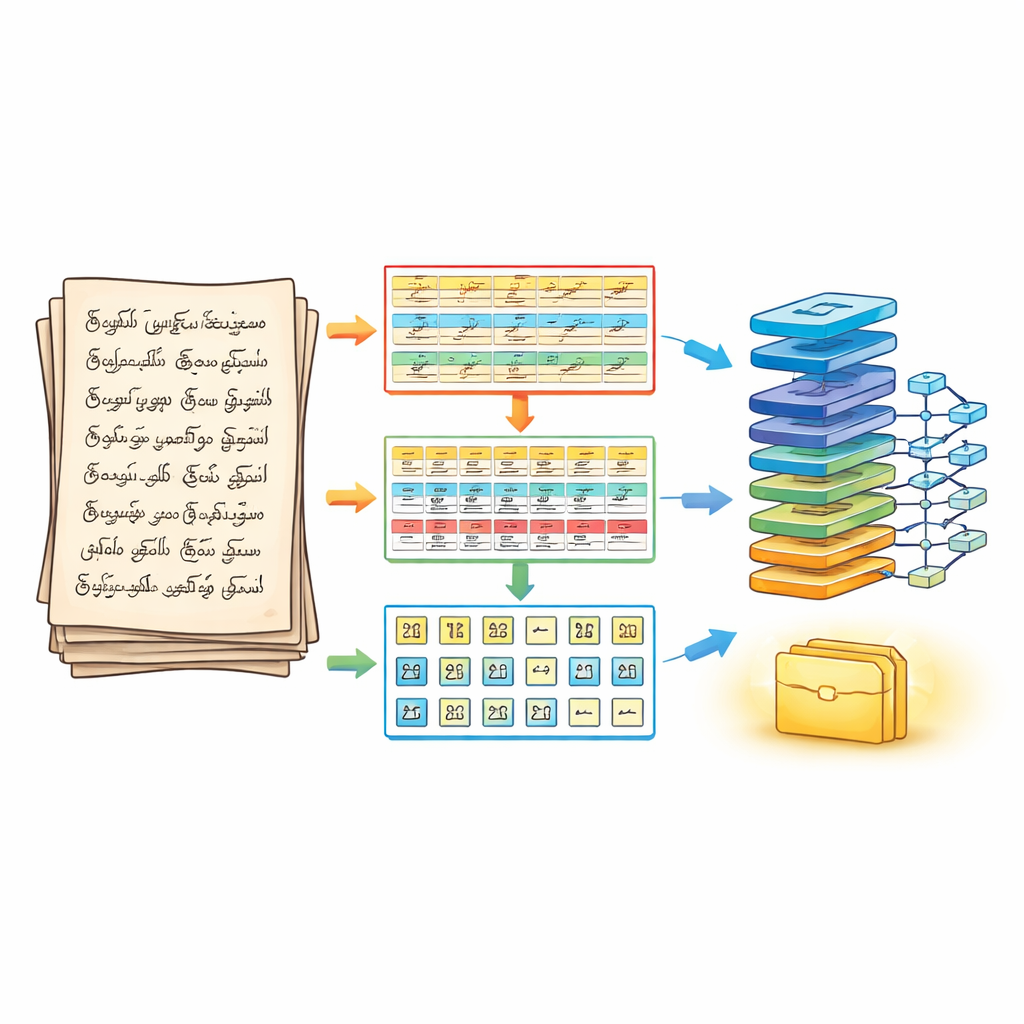
Ein dreistufiger Ansatz, die Seite aufzuteilen
Um dem zu begegnen, überarbeiten die Autorinnen und Autoren zunächst, wie eine Seite vor der Erkennung segmentiert wird. Ihre dreiphasige Segmentierungspipeline behandelt ein handschriftliches Dokument wie ein geschichtetes Puzzle. In der ersten Phase wird die Seite mit gängigen Bildverarbeitungsstufen bereinigt und geschärft und dann in horizontale Textzeilen unterteilt. In der zweiten Phase wird jede Zeile in einzelne Wörter zerlegt, wobei sorgfältig angepasst wird, wie stark benachbarte Striche zusammengeführt werden, damit winzige Vokalzeichen nicht verloren gehen. In der dritten Phase wird jedes Wort weiter in einzelne Zeichen aufgespalten, wobei Konturen und Begrenzungsrahmen verwendet werden, die den tatsächlichen Tintenstrichen folgen. Das Ergebnis ist ein strukturiertes dreidimensionales Array — Zeile, Wort, Zeichen — das die Leserichtung bewahrt und zugleich klar isolierte Zeichen an die Erkennungsmaschine liefert.
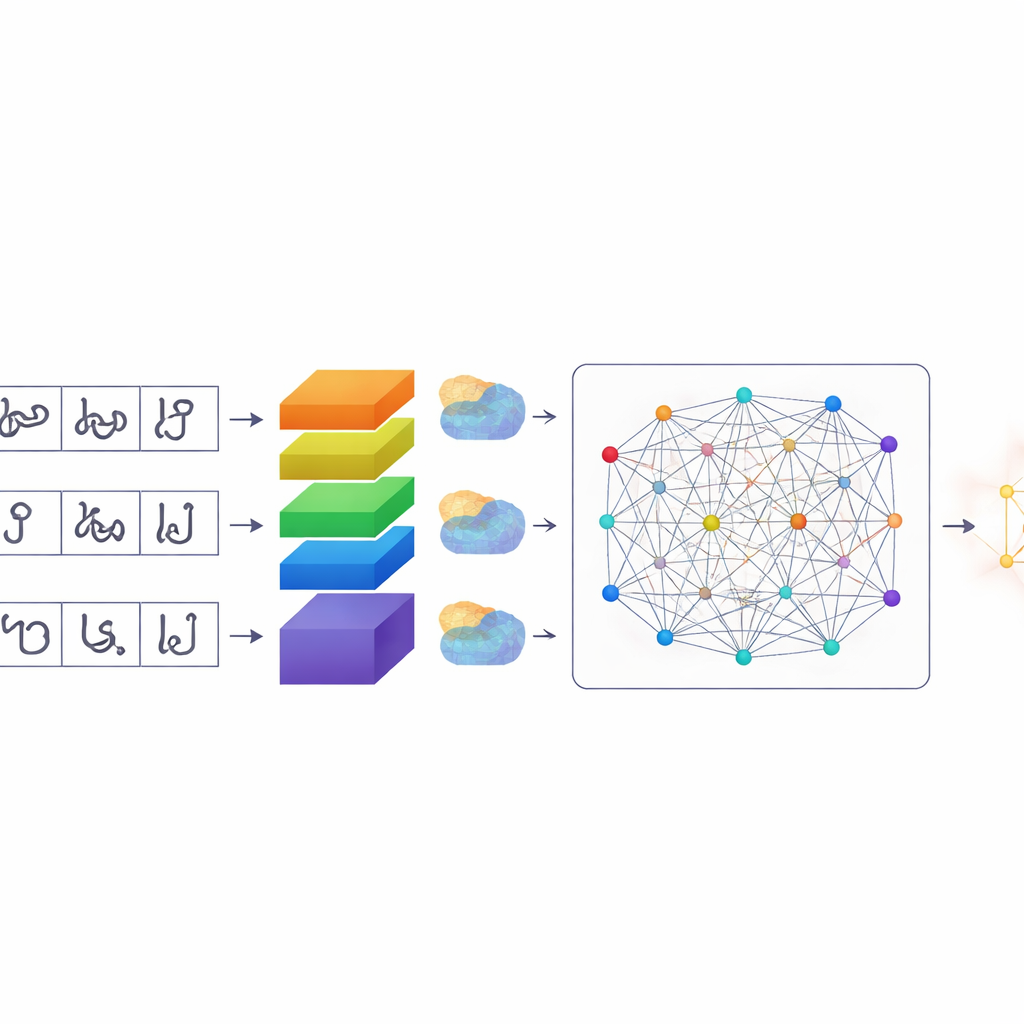
Eine intelligentere Art, wie Computer Aufmerksamkeit verteilen
Sobald die Zeichen segmentiert sind, nutzt TamilSTARNet ein zugeschnittenes Deep-Learning-Modell, um festzustellen, welches Zeichen jeweils vorliegt. Im Kern steht ein Stapel von Faltungs- (Convolutional-) Schichten, die visuelle Muster aus den Bildern lernen. Darauf aufbauend fügen die Autorinnen und Autoren mehrere Arten von „Attention“-Mechanismen hinzu. Diese Module helfen dem Netzwerk zu entscheiden, welche Bildbereiche und internen Merkmale am wichtigsten sind. Ein Baustein hebt bestimmte Kanäle hervor, die subtile Strichunterschiede erfassen — genau die kleinen Haken und Schleifen, die ähnliche tamilische Zeichen unterscheiden. Ein anderes Modul konzentriert sich darauf, wo sich wichtige Striche auf der Oberfläche des Zeichens befinden. Eine abschließende Selbstaufmerksamkeits-Schicht betrachtet das gesamte Zeichen auf einmal und verbindet entfernte Striche, die gemeinsam seine Form definieren. Durch die Kombination dieser Aufmerksamkeitsformen wird das System besser darin, Zeichen auseinanderzuhalten, die sich nur durch eine winzige Markierung oder Kurve unterscheiden.
Wie gut das System arbeitet
Die Forschenden testeten TamilSTARNet an zwei großen öffentlichen Datensätzen, die zusammen mehr als 160.000 Beispiele mit 156 Zeichenklassen von Hunderten Schreibenden enthalten. Nach dem Training erkannte das Modell etwa 96 % der Testzeichen korrekt und übertraf damit bekannte Alternativen wie Tesseract OCR und mehrere tiefe neuronale Netzwerk-Benchmarks. Die dreiphasige Segmentierung erwies sich ebenfalls als wichtig: Als dasselbe Erkennungsmodell ohne diese sorgfältige Zeilen–Wort–Zeichen-Aufteilung eingesetzt wurde, gingen Genauigkeit und Zuverlässigkeit zurück. Das Team evaluierte seinen Ansatz zudem an herausfordernden Palmblattmanuskripten, bei denen die Tinte schwach ist und die Oberflächen unregelmäßig sind. Die Leistung war in diesem rauen Umfeld erwartungsgemäß niedriger, aber weiterhin stark genug, um zu zeigen, dass die Methode auf reale historische Materialien übertragbar ist.
Was das für die Bewahrung des tamilischen Erbes bedeutet
Kurz gefasst gibt TamilSTARNet Computern eine sorgfältigere Methode, handgeschriebenes Tamil zu betrachten: Zuerst organisiert es die unordentliche Seite in gut getrennte Teile, dann untersucht es jedes Zeichen mit fokussierter Aufmerksamkeit auf die relevanten Striche. Diese Kombination ermöglicht dem System, komplexe Handschriften deutlich zuverlässiger zu lesen als frühere Werkzeuge. Obwohl schwierige Fälle bleiben — etwa sehr stilisierte Handschriften oder stark beschädigte Seiten — stellt der Ansatz einen praktischen Schritt in Richtung großangelegter Digitalisierung tamilischer Texte dar. Wenn sich solche Systeme weiter verbessern und verbreiten, können alte Notizbücher, Briefe und Manuskripte in durchsuchbare digitale Bibliotheken verwandelt werden, wodurch das literarische Erbe des Tamil nicht nur vor physischem Verfall bewahrt, sondern auch für künftige Generationen leichter zugänglich gemacht wird.
Zitation: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Schlüsselwörter: handgeschriebenes Tamil OCR, Dokumentendigitalisierung, auf Aufmerksamkeit basierende neuronale Netze, Erhalt des kulturellen Erbes, Schrifterkennung