Clear Sky Science · tr
TamilSTARNet: el yazısı Tamil karakterleri için üç aşamalı mimariyle segmentasyon ve dikkat tabanlı tanıma
Eski Tamil Yazılarını Dijital Çağa Taşımak
Güney Hindistan ve ötesinde, değerli hikâyeler, şiirler ve kayıtlar solmaya yüz tutmuş kâğıtlar, palmiye yaprakları ve defterlerin içinde kilitli duruyor. Bu materyalin çoğu el yazısı olduğu için bilgisayarlar bunları okumakta zorlanıyor; bu da geniş bir Tamil kültürü kesitinin aranması, paylaşılması veya incelenmesini güçleştiriyor. Bu makale, el yazısı Tamil’i okumak üzere özel olarak tasarlanmış yeni bir bilgisayar görüşü sistemi olan TamilSTARNet’i tanıtıyor; böylece yüzyıllık miras dijital biçimde korunup erişilebilir hâle getirilebilsin.
Bilgisayarlar İçin El Yazısı Tamil Neden Zordur
Tamil yazısı zengin ve ifadeli bir yapıya sahiptir: az sayıdaki temel ünlü ve ünsüz, 300’ün üzerinde bileşik karakter oluşturmak üzere birleşir. Sayfada bu harfler döngüler, kıvrımlar ve ana vuruşların üstünde, altında ya da yanında bulunan küçük işaretlerle birbirine akışkan biçimde bağlanır. İnsanlar bunları birçok kişisel üslupta yazar; vuruşlar birleşebilir, üst üste binip kalınlık değiştirebilir. Neat basılmış İngilizce metinlerde iyi çalışan standart Optik Karakter Tanıma (OCR) araçları burada sık sık başarısız olur. Birleşmiş harfleri yanlış okur, anlamı değiştiren küçük işaretleri kaçırır ve mürekkep soluk veya aralıklar düzensiz olduğunda aksar. Tamil’e yönelik mevcut araştırmalar el işçiliği kurallar veya genel sinir ağları kullanarak ilerleme kaydetti, ancak yöntemlerin çoğu ya temiz, tek tek kesilmiş karakterler varsayar ya da karakterler temas edip sıkıştığında çöker.
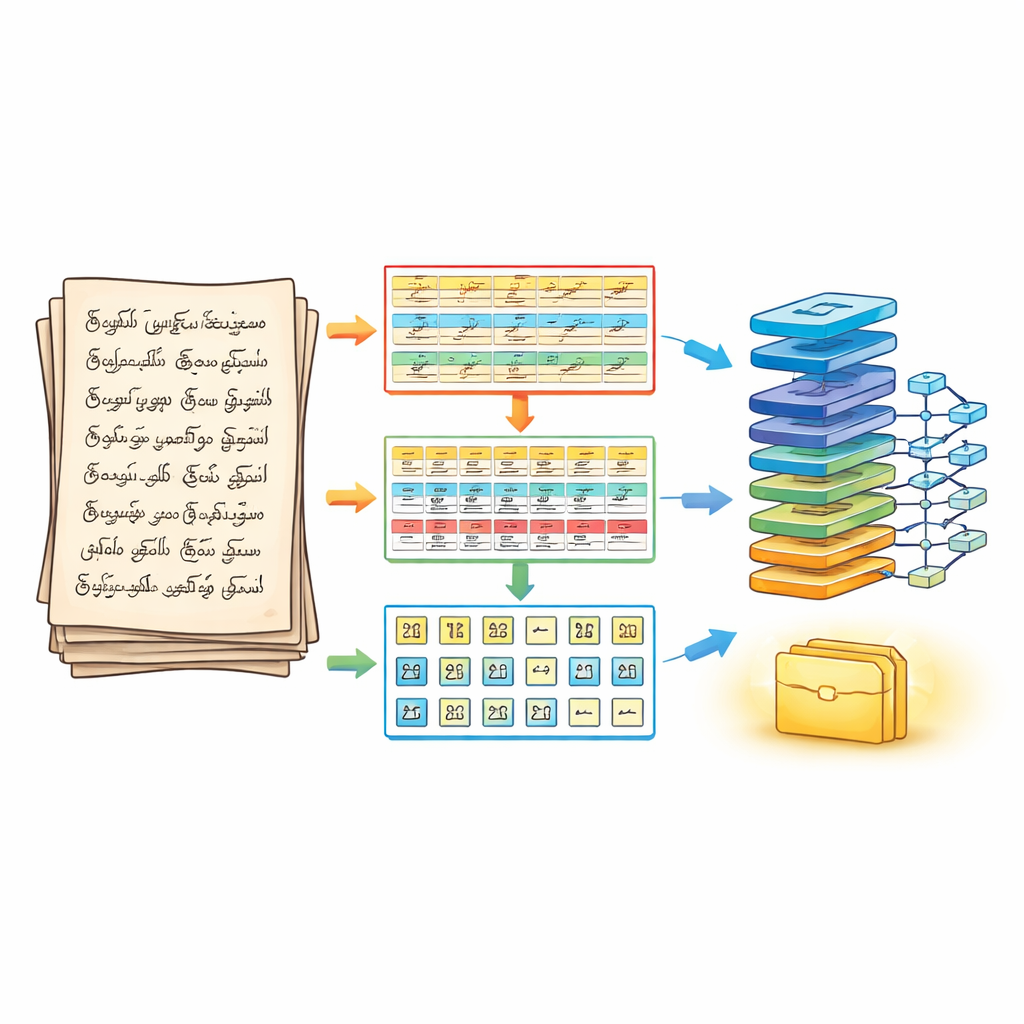
Sayfayı Üç Adımda Bölme Yöntemi
Buna çözüm olarak yazarlar önce tanımadan önce sayfanın nasıl bölüneceğini yeniden tasarlıyor. Üç aşamalı segmentasyon hattı, el yazısı bir belgeyi katmanlı bir bulmaca gibi ele alıyor. Birinci aşamada sayfa, standart görüntü işleme adımlarıyla temizlenip keskinleştirilir ve daha sonra yatay metin satırlarına ayrılır. İkinci aşamada her satır ayrı kelimelere bölünür; komşu vuruşların ne kadar birleştirileceği dikkatle ayarlanır, böylece küçük ünlü işaretleri kaybolmaz. Üçüncü aşamada ise her kelime, mürekkep vuruşlarını izleyen konturlar ve sınırlayıcı kutular kullanılarak bireysel karakterlere ayrılır. Sonuç, okuma sırasını koruyan ve tanıma motoruna net şekilde izole edilmiş karakterler sağlayan satır–kelime–karakter üç boyutlu düzenli bir dizi olur.
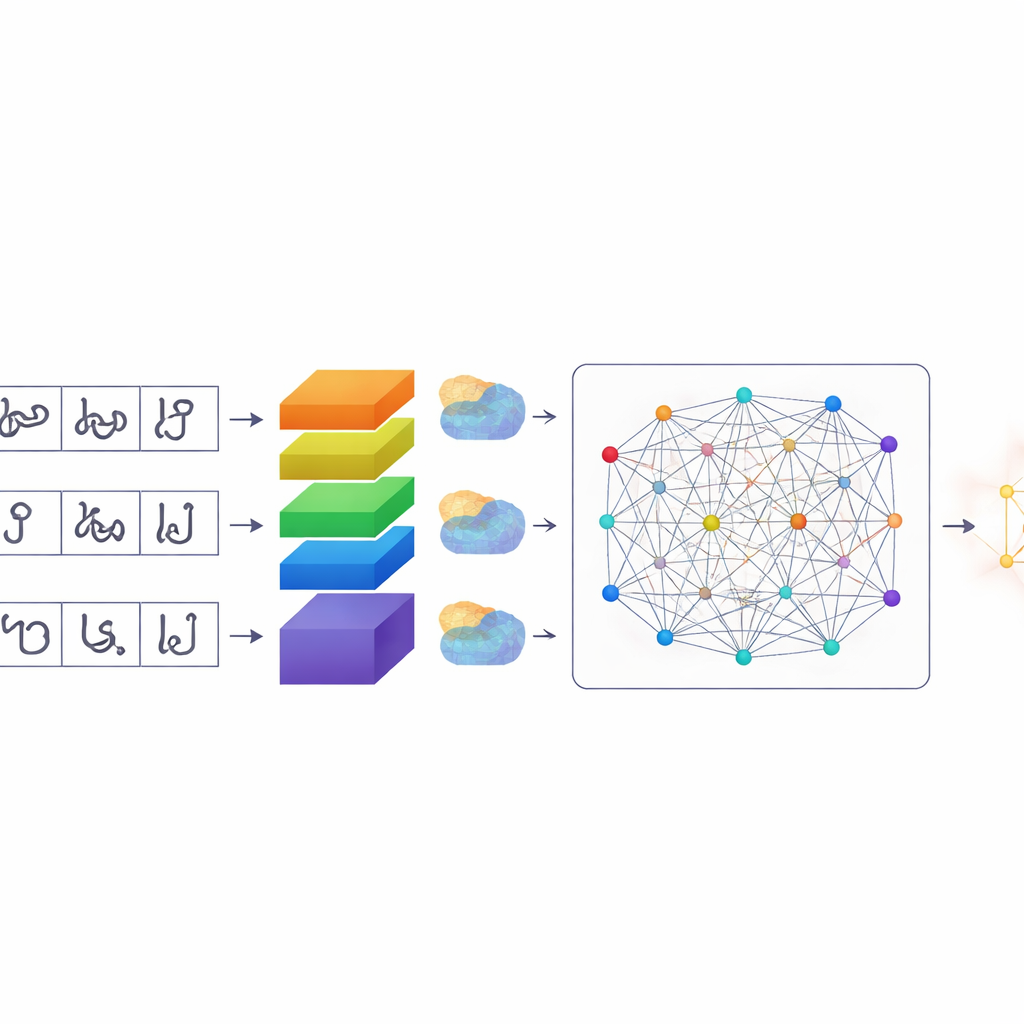
Bilgisayarların Dikkatini Toplamanın Daha Akıllı Bir Yolu
Karakterler segmentlendikten sonra TamilSTARNet her birinin ne olduğunu çözmek için uyarlanmış bir derin öğrenme modeli kullanır. Çekirdeğinde görüntülerden görsel desenleri öğrenen bir dizi konvolüsyon katmanı bulunur. Bunun üzerine yazarlar birkaç tür “dikkat” mekanizması ekler. Bu modüller, ağın görüntünün hangi bölümlerine ve hangi iç özelliklere özellikle önem vereceğine karar vermesine yardımcı olur. Bir bileşen, benzer Tamil harflerini ayırt eden küçük kanca ve döngüler gibi ince vuruş farklılıklarını yakalayan belirli kanalları vurgular. Diğer bir bileşen, önemli vuruşların karakter yüzeyinde nerede yer aldığını öne çıkarır. Son bir kendine dikkat (self-attention) katmanı ise karakterin tamamına birden bakarak birlikte şekil oluşturan uzak vuruşları ilişkilendirir. Bu dikkat biçimlerini birleştirerek sistem, yalnızca küçük bir işaret veya kıvrımla birbirinden ayrılan karakterleri ayırt etmede daha iyi olur.
Sistemin Performansı Ne Kadar İyi
Araştırmacılar TamilSTARNet’i birlikte 156 karakter sınıfını ve yüzlerce yazarı kapsayan 160.000’den fazla örnek içeren iki büyük açık veri kümesi üzerinde test etti. Eğitimden sonra model test karakterlerinin yaklaşık %96’sını doğru tanıdı ve Tesseract OCR ile birkaç derin sinir ağı tabanlı alternatiften daha iyi performans gösterdi. Üç aşamalı segmentasyon da önemli olduğunu kanıtladı: aynı tanıma modeli dikkatli bu satır–kelime–karakter ayrımı olmadan kullanıldığında doğruluk ve güvenilirlik düştü. Ekip yaklaşımını mürekkebin soluk ve yüzeylerin düzensiz olduğu zorlu palmiye yaprağı el yazmalarında da değerlendirdi. Bu sert ortamda performans doğal olarak daha düşük olsa da yöntem gerçek tarihî materyallere uzatılabileceğini gösterecek kadar güçlü kaldı.
Bu Tamil Mirasının Korunması İçin Ne Anlama Geliyor
Basitçe söylemek gerekirse, TamilSTARNet bilgisayarlara el yazısı Tamil’e daha dikkatli bakmanın bir yolunu veriyor: önce düzensiz sayfayı iyi ayrılmış parçalara organize ediyor, sonra her karakteri önemli vuruşlara odaklanan bir dikkatle inceliyor. Bu birleşim, sistemin karmaşık el yazılarını önceki araçlardan çok daha güvenilir şekilde okumasına olanak tanıyor. Oldukça stilize yazılar veya ağır hasarlı sayfalar gibi zorlu durumlar sürse de, bu yaklaşım Tamil metinlerinin büyük ölçekli dijitalleştirilmesi yönünde pratik bir adım teşkil ediyor. Bu tür sistemler geliştikçe ve yayıldıkça, eski defterler, mektuplar ve el yazmaları aranabilir dijital kütüphanelere dönüştürülebilecek; böylece Tamil’in edebî mirası yalnızca fiziksel çürümeye karşı korunmakla kalmayıp gelecekteki nesillerin erişimine de açılmış olacak.
Atıf: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Anahtar kelimeler: Tamil el yazısı OCR, belge dijitalleştirme, dikkat tabanlı sinir ağları, kültürel miras koruma, yazı tanıma