Clear Sky Science · it
TamilSTARNet: segmentazione tramite architettura in tre fasi e riconoscimento basato sull’attenzione per caratteri Tamil manoscritti
Portare la scrittura Tamil antica nell’era digitale
In tutto il Sud dell’India e oltre, storie, poesie e registri preziosi scritti in Tamil restano rinchiusi su carta che sbiadisce, foglie di palma e quaderni. Poiché gran parte di questo materiale è manoscritto, i computer fanno fatica a leggerlo, perciò vaste porzioni della cultura Tamil rimangono difficili da cercare, condividere o studiare. Questo articolo presenta TamilSTARNet, un nuovo sistema di visione artificiale progettato specificamente per leggere il Tamil manoscritto, in modo che secoli di patrimonio possano essere preservati e resi accessibili in forma digitale.
Perché il Tamil manoscritto è difficile per i computer
Il sistema di scrittura Tamil è ricco ed espressivo: un piccolo insieme di vocali e consonanti di base si combina in oltre 300 caratteri composti. Sulla pagina queste lettere scorrono insieme con anse, curve e segnini piccoli sopra, sotto e accanto ai tratti principali. Le persone li scrivono in molti stili personali, con tratti che si uniscono, si sovrappongono o variano nello spessore. Gli strumenti standard di riconoscimento ottico dei caratteri (OCR), che funzionano bene sul testo inglese stampato in modo ordinato, spesso falliscono qui. Interpretano male lettere unite, perdono piccoli segni che cambiano il significato e incontrano difficoltà quando l’inchiostro è sbiadito o gli spazi sono irregolari. Le ricerche esistenti sul Tamil hanno fatto progressi usando regole fatte a mano o reti neurali generiche, ma la maggior parte dei metodi assume caratteri puliti ritagliati uno per uno o fallisce quando i caratteri si toccano e si affollano.
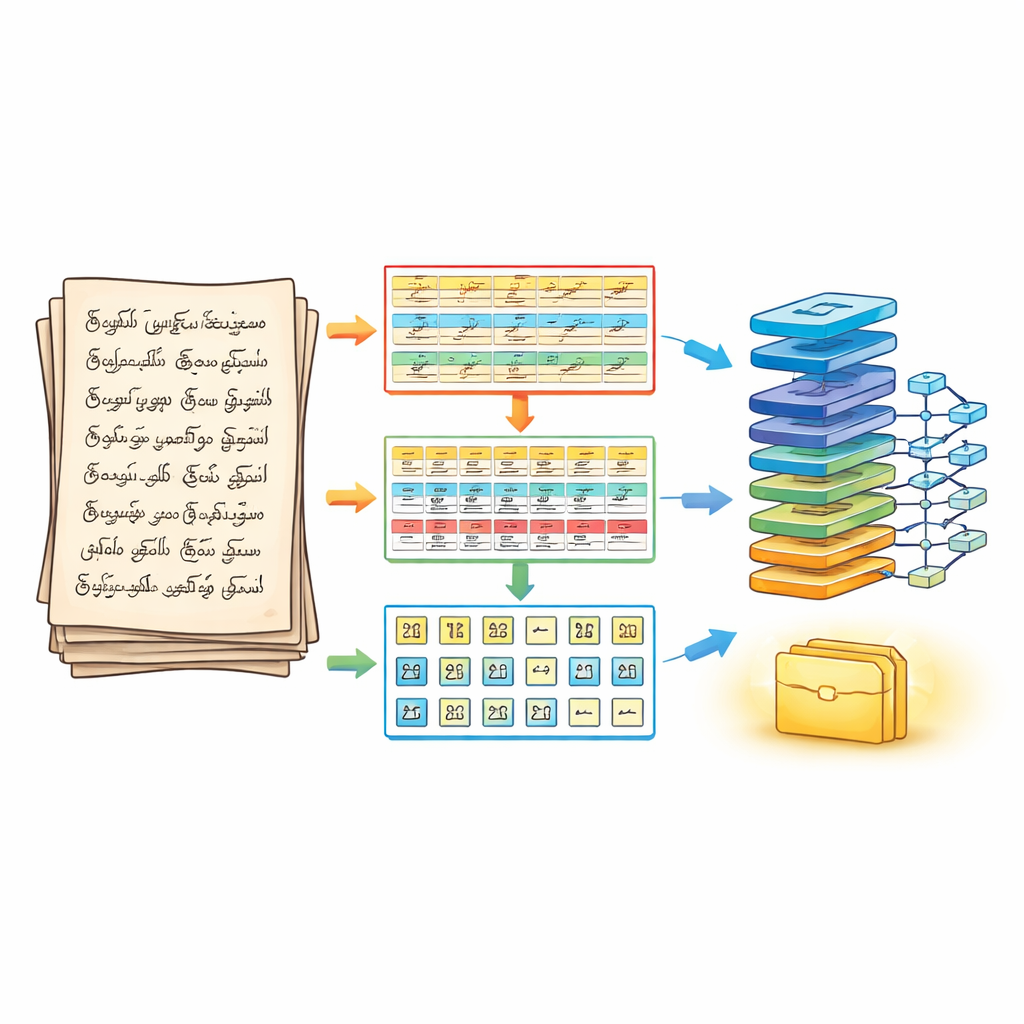
Un modo in tre fasi per segmentare la pagina
Per affrontare il problema, gli autori riprogettano innanzitutto come una pagina viene suddivisa prima di qualsiasi riconoscimento. La loro pipeline di segmentazione in tre fasi tratta un documento manoscritto come un puzzle stratificato. Nella prima fase la pagina viene pulita e messa a fuoco con passaggi standard di elaborazione delle immagini, poi divisa in linee orizzontali di testo. Nella seconda fase ogni riga viene spezzata in parole separate, regolando con cura quanto unire i tratti vicini in modo che i piccoli segni vocalici non vadano persi. Nella terza fase ogni parola viene ulteriormente suddivisa in caratteri individuali usando contorni e riquadri di delimitazione che seguono i tratti effettivi dell’inchiostro. Il risultato è un array strutturato tridimensionale—riga, parola, carattere—che preserva l’ordine di lettura fornendo al motore di riconoscimento caratteri chiaramente isolati.
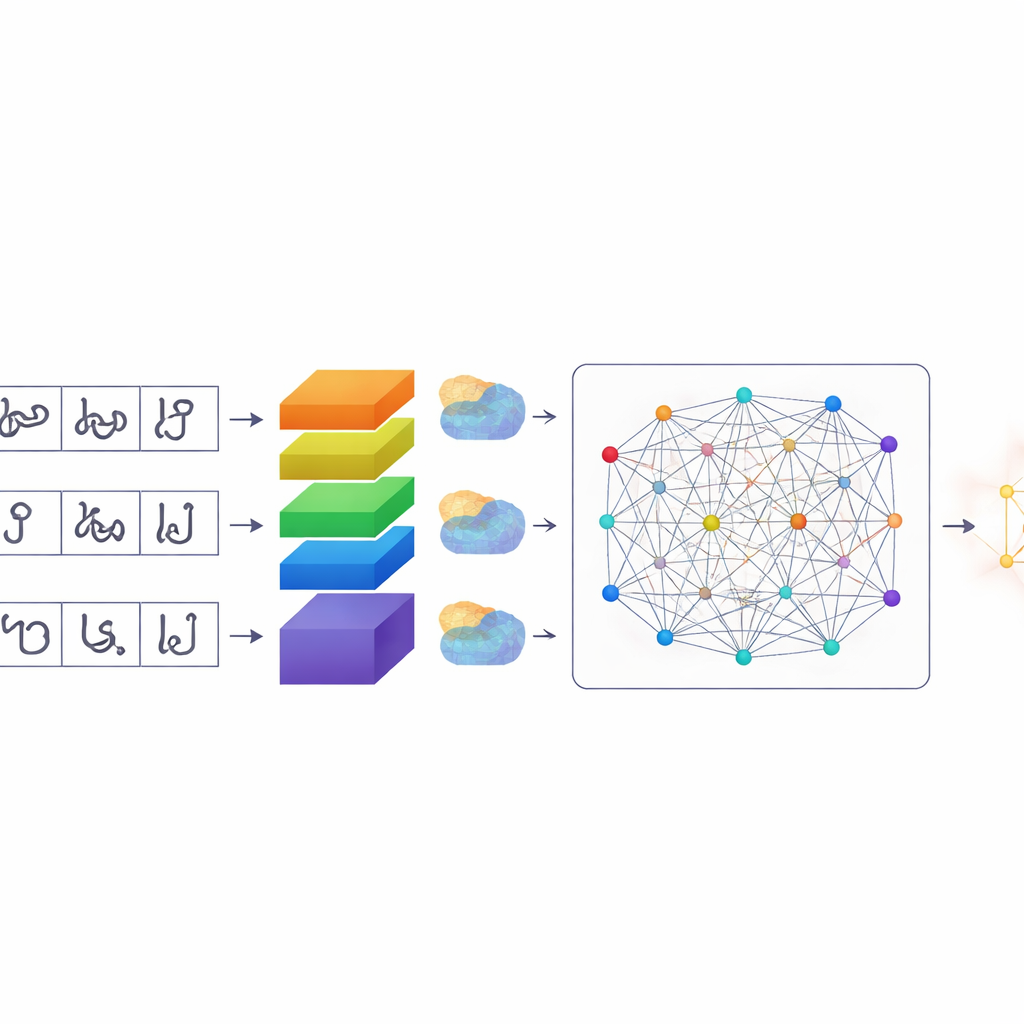
Un modo più intelligente per far «prestare attenzione» ai computer
Una volta segmentati i caratteri, TamilSTARNet utilizza un modello di deep learning su misura per determinare quale carattere sia ciascuno. Al suo centro c’è un insieme di layer convoluzionali che apprendono pattern visivi dalle immagini. Sulla cima di questi, gli autori aggiungono diversi tipi di meccanismi di «attenzione». Questi moduli aiutano la rete a decidere quali parti dell’immagine e quali caratteristiche interne sono più rilevanti. Un componente mette in luce canali specifici che catturano sottili differenze nei tratti—esattamente quei piccoli uncini e anse che distinguono lettere Tamil simili. Un altro componente si concentra su dove si trovano i tratti importanti sulla superficie del carattere. Uno strato finale di self-attention osserva l’intero carattere contemporaneamente, collegando tratti distanti che insieme definiscono la forma. Combinando queste forme di attenzione, il sistema migliora nel separare caratteri che differiscono solo per un piccolo segno o una curva.
Quanto bene funziona il sistema
I ricercatori hanno testato TamilSTARNet su due grandi dataset pubblici che insieme contengono più di 160.000 esempi distribuiti su 156 classi di caratteri provenienti da centinaia di scrittori. Dopo l’addestramento, il modello ha riconosciuto correttamente circa il 96% dei caratteri del test, superando alternative note come Tesseract OCR e diversi baselines di reti neurali profonde. Anche la segmentazione in tre fasi si è dimostrata importante: quando lo stesso modello di riconoscimento è stato usato senza questa precisa suddivisione riga–parola–carattere, accuratezza e affidabilità sono diminuite. Il team ha inoltre valutato l’approccio su manoscritti su foglie di palma, dove l’inchiostro è tenue e le superfici irregolari. Le prestazioni sono naturalmente state inferiori in questo contesto severo, ma comunque sufficientemente solide da dimostrare che il metodo può estendersi a materiali storici reali.
Cosa significa per la conservazione del patrimonio Tamil
In termini semplici, TamilSTARNet offre ai computer un modo più accurato di guardare il Tamil manoscritto: prima organizza la pagina disordinata in pezzi ben separati, poi esamina ogni carattere con un’attenzione mirata ai tratti che contano. Questa combinazione permette al sistema di leggere la scrittura complessa molto più affidabilmente rispetto agli strumenti precedenti. Sebbene rimangano casi difficili—come scritture molto stilizzate o pagine gravemente danneggiate—l’approccio rappresenta un passo pratico verso la digitalizzazione su larga scala dei testi in Tamil. Con il miglioramento e la diffusione di sistemi simili, vecchi quaderni, lettere e manoscritti potranno essere trasformati in biblioteche digitali ricercabili, aiutando a garantire che il patrimonio letterario Tamil non solo venga salvato dal decadimento fisico ma sia anche più facilmente esplorabile dalle generazioni future.
Citazione: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Parole chiave: OCR Tamil manoscritto, digitalizzazione dei documenti, reti neurali basate sull’attenzione, conservazione del patrimonio culturale, riconoscimento della scrittura