Clear Sky Science · fr
TamilSTARNet : segmentation via une architecture triphasée et reconnaissance par attention pour les caractères manuscrits tamouls
Faire entrer l’écriture tamoule ancienne dans l’ère numérique
Partout dans le sud de l’Inde et au-delà, des récits, poèmes et registres précieux rédigés en tamoul restent enfermés dans des feuilles de papier, des feuilles de palmier et des carnets qui s’estompent. Comme une grande partie de ce corpus est manuscrite, les ordinateurs peinent à le lire, si bien que de larges pans de la culture tamoule restent difficiles à rechercher, partager ou étudier. Cet article présente TamilSTARNet, un nouveau système de vision par ordinateur conçu spécifiquement pour lire le tamoul manuscrit, afin que des siècles de patrimoine puissent être préservés et accessibles sous forme numérique.
Pourquoi le tamoul manuscrit est difficile pour les ordinateurs
L’écriture tamoule est riche et expressive : un petit ensemble de voyelles et de consonnes de base se combine en plus de 300 caractères composés. Sur la page, ces lettres se mêlent avec des boucles, des courbes et de petites marques au-dessus, en dessous et à côté des traits principaux. Les gens les écrivent dans de nombreux styles personnels, avec des traits qui se rejoignent, se chevauchent ou varient en épaisseur. Les outils standards de reconnaissance optique de caractères (OCR), efficaces sur du texte anglais imprimé propre, échouent souvent ici. Ils confondent des lettres jointes, perdent de minuscules marques qui changent le sens et butent lorsque l’encre est pâlie ou que l’espacement est irrégulier. Les recherches existantes sur le tamoul ont progressé via des règles conçues manuellement ou des réseaux neuronaux génériques, mais la plupart des méthodes supposent des caractères propres découpés un par un, ou s’effondrent lorsque des caractères se touchent et se densifient.
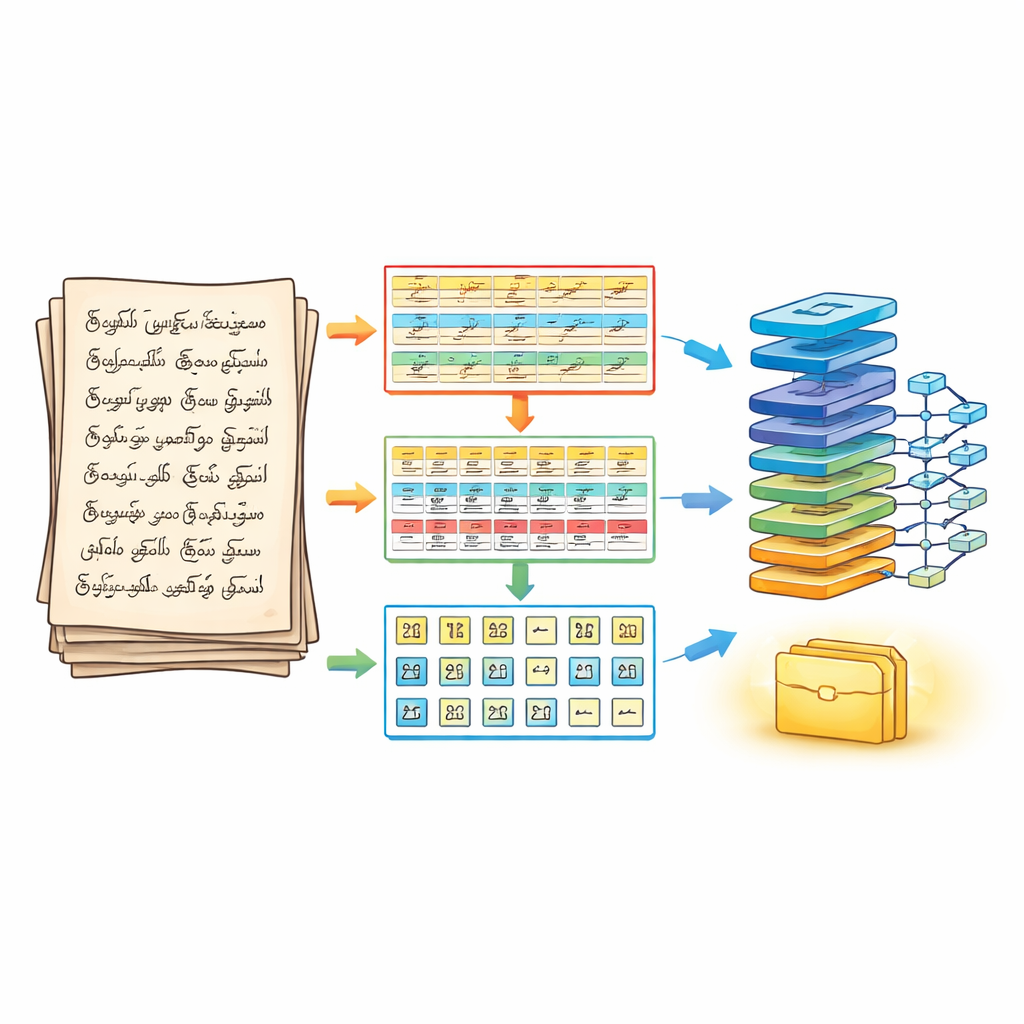
Une méthode en trois étapes pour découper la page
Pour répondre à ce défi, les auteurs repensent d’abord la manière dont une page est segmentée avant toute reconnaissance. Leur pipeline de segmentation triphasé traite un document manuscrit comme un puzzle en couches. Dans la première phase, la page est nettoyée et affinée à l’aide d’étapes classiques de traitement d’image, puis divisée en lignes de texte horizontales. Dans la deuxième phase, chaque ligne est découpée en mots séparés, en ajustant soigneusement la fusion des traits voisins afin que de petites marques vocaliques ne soient pas perdues. Dans la troisième phase, chaque mot est en outre scindé en caractères individuels à l’aide des contours et des boîtes englobantes qui suivent les véritables traits d’encre. Le résultat est un tableau tridimensionnel structuré — ligne, mot, caractère — qui préserve l’ordre de lecture tout en fournissant des caractères clairement isolés au moteur de reconnaissance.
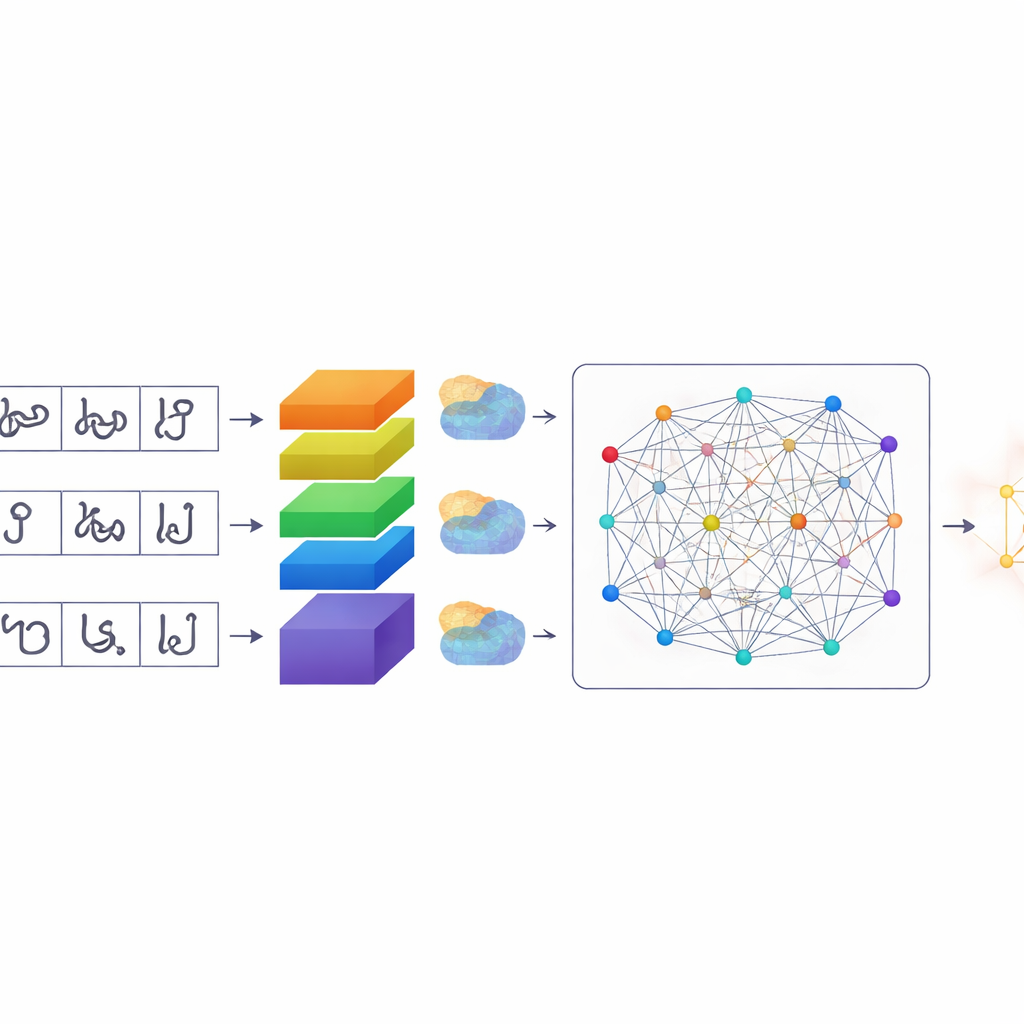
Une façon plus intelligente pour les ordinateurs de porter attention
Une fois les caractères segmentés, TamilSTARNet utilise un modèle d’apprentissage profond adapté pour déterminer l’identité de chacun. Au cœur se trouve une pile de couches convolutionnelles qui apprennent des motifs visuels à partir des images. Par-dessus cela, les auteurs ajoutent plusieurs types de mécanismes d’« attention ». Ces modules aident le réseau à décider quelles parties de l’image et quelles caractéristiques internes importent le plus. Un composant met en évidence des canaux spécifiques qui capturent des différences subtiles de trait — exactement les petits crochets et boucles qui distinguent des lettres tamoules similaires. Un autre composant se concentre sur l’emplacement des traits importants à la surface du caractère. Une dernière couche d’auto-attention regarde l’ensemble du caractère à la fois, reliant des traits distants qui définissent conjointement sa forme. En combinant ces formes d’attention, le système devient meilleur pour démêler des caractères qui ne diffèrent que par une marque ou une courbe minime.
Quelle est la performance du système
Les chercheurs ont testé TamilSTARNet sur deux grands ensembles de données publics contenant ensemble plus de 160 000 exemples couvrant 156 classes de caractères provenant de centaines d’écrivains. Après entraînement, le modèle a correctement reconnu environ 96 % des caractères de test, surpassant des alternatives bien connues telles que Tesseract OCR et plusieurs réseaux neuronaux profonds de référence. La segmentation triphasée s’est également révélée importante : lorsque le même modèle de reconnaissance était utilisé sans cette découpe soignée ligne–mot–caractère, la précision et la fiabilité diminuaient. L’équipe a en outre évalué son approche sur des manuscrits sur feuilles de palmier, où l’encre est pâle et les surfaces irrégulières. Les performances y étaient naturellement plus faibles dans ce contexte difficile, mais suffisamment fortes pour montrer que la méthode peut s’étendre à des matériaux historiques réels.
Ce que cela signifie pour la préservation du patrimoine tamoul
En termes simples, TamilSTARNet donne aux ordinateurs une manière plus attentive d’examiner le tamoul manuscrit : il organise d’abord la page désordonnée en éléments bien séparés, puis étudie chaque caractère avec une attention ciblée sur les traits qui comptent. Cette combinaison permet au système de lire des écritures complexes de façon bien plus fiable que les outils précédents. Si des cas difficiles subsistent — comme des écritures très stylisées ou des pages sévèrement endommagées — l’approche représente une avancée pratique vers la numérisation à grande échelle des textes tamouls. À mesure que ces systèmes s’amélioreront et se diffuseront, de vieux carnets, lettres et manuscrits pourront être transformés en bibliothèques numériques consultables, contribuant à ce que le patrimoine littéraire tamoul soit non seulement préservé de la dégradation physique, mais aussi rendu plus accessible aux générations futures.
Citation: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Mots-clés: OCR manuscrit tamoul, numérisation de documents, réseaux neuronaux à attention, préservation du patrimoine culturel, reconnaissance d’écriture