Clear Sky Science · es
TamilSTARNet: segmentación mediante una arquitectura de tres fases y reconocimiento basado en atención para caracteres manuscritos en tamil
Llevando la escritura tamil antigua a la era digital
En el sur de la India y más allá, historias, poemas y registros valiosos escritos en tamil permanecen encerrados en papeles, hojas de palma y cuadernos que se desvanecen. Como gran parte de este material está manuscrito, los ordenadores tienen dificultades para leerlo, lo que hace que grandes porciones de la cultura tamil sean difíciles de buscar, compartir o estudiar. Este artículo presenta TamilSTARNet, un nuevo sistema de visión por ordenador diseñado específicamente para leer manuscritos en tamil, de modo que siglos de patrimonio puedan preservarse y accederse en formato digital.
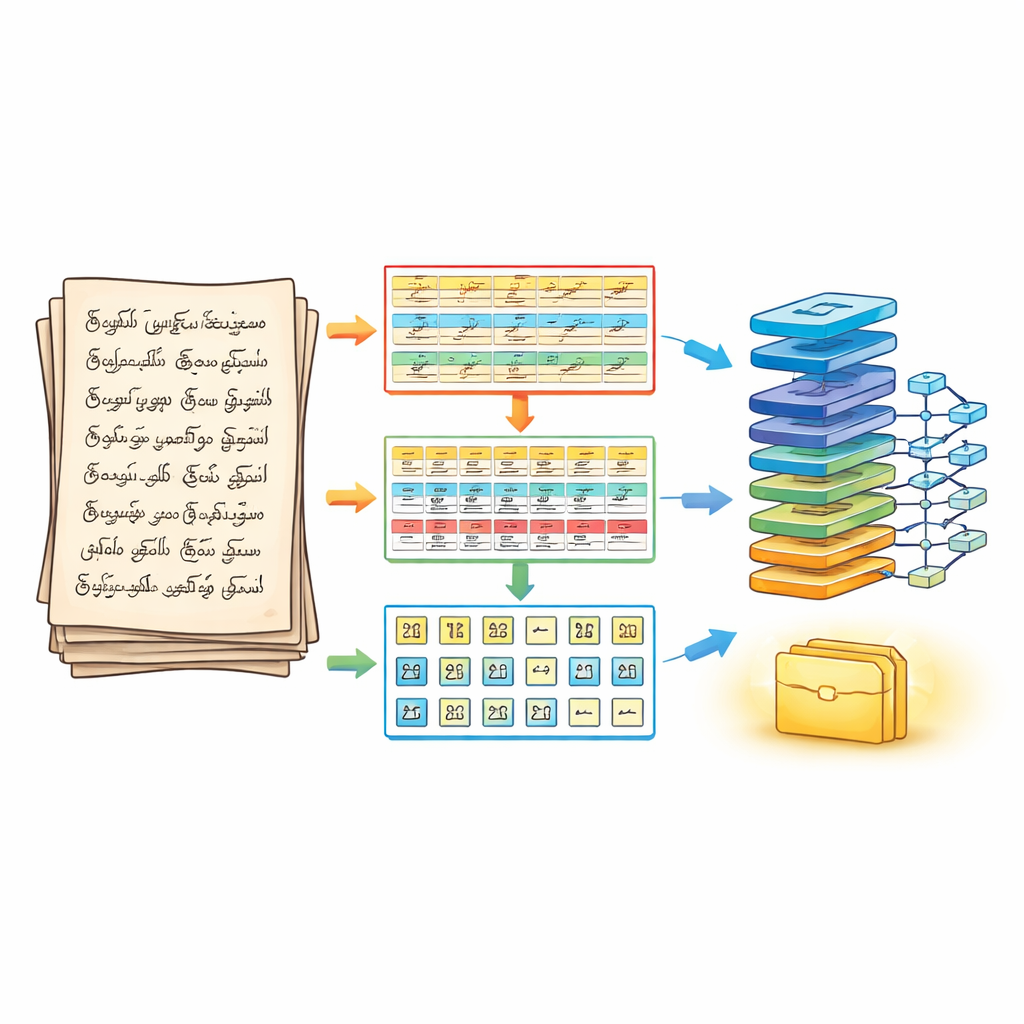
Por qué el tamil manuscrito es difícil para los ordenadores
La escritura tamil es rica y expresiva: un pequeño conjunto de vocales y consonantes básicas se combinan en más de 300 caracteres compuestos. En la página, estas letras fluyen juntas con bucles, curvas y pequeñas marcas encima, debajo y al lado de los trazos principales. Las personas las escriben con muchos estilos personales, con trazos que se unen, se solapan o varían en grosor. Las herramientas estándar de reconocimiento óptico de caracteres (OCR), que funcionan bien con texto impreso y ordenado en inglés, suelen fallar aquí. Confunden letras unidas, pasan por alto marcas diminutas que cambian el significado y tropiezan cuando la tinta está desvanecida o el espaciado es irregular. La investigación existente sobre tamil ha avanzado usando reglas hechas a mano o redes neuronales genéricas, pero la mayoría de los métodos o bien suponen caracteres limpios recortados uno a uno, o se descomponen cuando los caracteres se tocan y se apiñan.
Una forma en tres pasos de dividir la página
Para abordar esto, los autores rediseñan primero cómo se segmenta una página antes de cualquier reconocimiento. Su canal de segmentación en tres fases trata el documento manuscrito como un rompecabezas por capas. En la primera fase, la página se limpia y afila usando pasos estándar de procesamiento de imagen, y luego se divide en líneas horizontales de texto. En la segunda fase, cada línea se descompone en palabras separadas, ajustando con cuidado cuánto se fusionan los trazos vecinos para que no se pierdan las pequeñas marcas vocálicas. En la tercera fase, cada palabra se subdivide en caracteres individuales usando contornos y cuadros delimitadores que siguen los trazos reales de tinta. El resultado es una matriz tridimensional estructurada—línea, palabra, carácter—que preserva el orden de lectura a la vez que entrega caracteres claramente aislados al motor de reconocimiento.
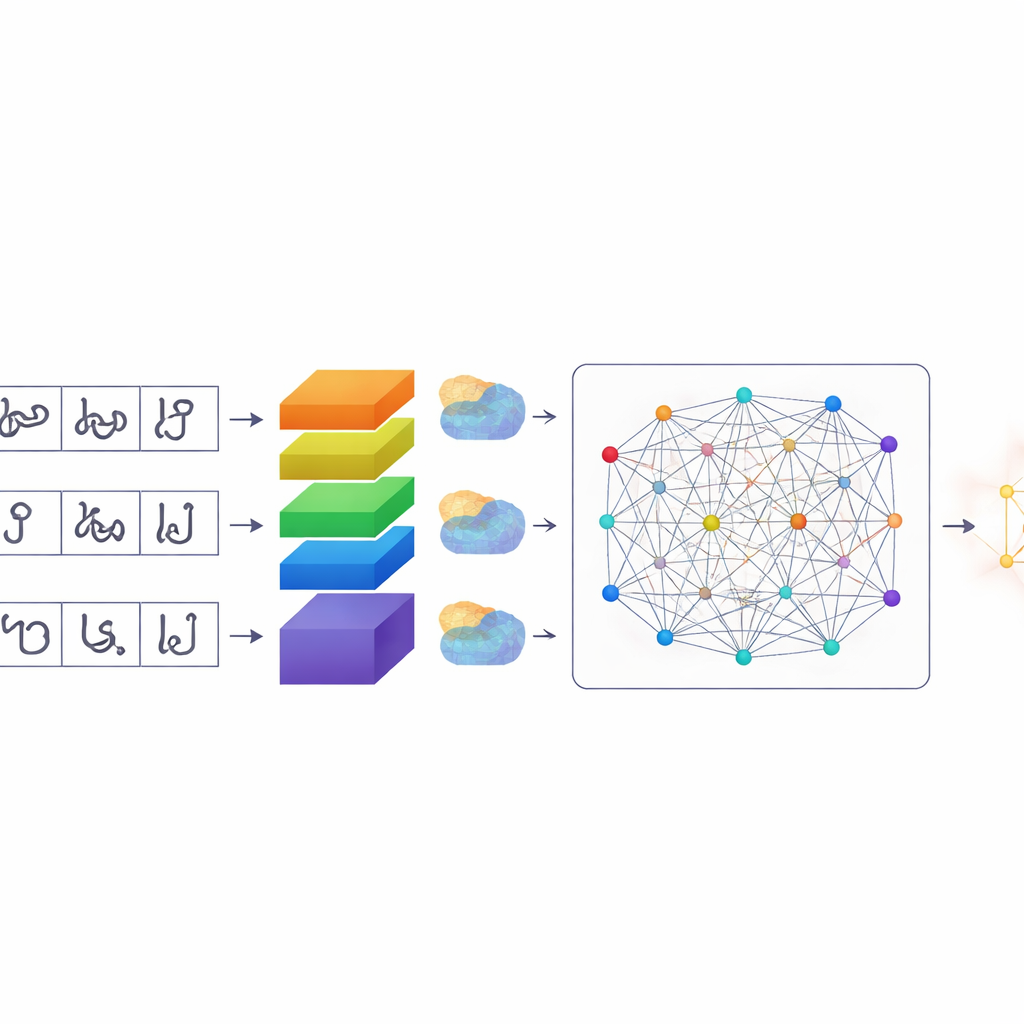
Una forma más inteligente para que los ordenadores presten atención
Una vez segmentados los caracteres, TamilSTARNet utiliza un modelo de aprendizaje profundo adaptado para determinar qué es cada uno. En su núcleo hay una pila de capas convolucionales que aprenden patrones visuales a partir de las imágenes. Encima de esto, los autores añaden varios tipos de mecanismos de “atención”. Estos módulos ayudan a la red a decidir qué partes de la imagen y qué características internas son las más relevantes. Un componente resalta canales específicos que capturan diferencias sutiles en los trazos—exactamente los pequeños ganchos y bucles que distinguen letras tamil similares. Otro componente se centra en dónde se encuentran los trazos importantes sobre la superficie del carácter. Una capa final de autoatención observa todo el carácter a la vez, vinculando trazos distantes que en conjunto definen su forma. Al combinar estas formas de atención, el sistema mejora en distinguir caracteres que difieren solo por una marca o curva minúscula.
Qué tan bien funciona el sistema
Los investigadores probaron TamilSTARNet en dos grandes conjuntos de datos públicos que en conjunto contienen más de 160.000 ejemplos abarcando 156 clases de caracteres procedentes de cientos de escritores. Tras el entrenamiento, el modelo reconoció correctamente alrededor del 96% de los caracteres de prueba, superando a alternativas conocidas como Tesseract OCR y varias arquitecturas neuronales profundas de referencia. La segmentación en tres fases también demostró ser importante: cuando el mismo modelo de reconocimiento se usó sin esta cuidadosa división línea–palabra–carácter, la precisión y la fiabilidad cayeron. El equipo además evaluó su enfoque en desafiantes manuscritos en hojas de palma, donde la tinta es tenue y las superficies son irregulares. El rendimiento fue naturalmente menor en este entorno adverso, pero aún lo bastante sólido como para mostrar que el método puede extenderse a materiales históricos reales.
Qué significa esto para la preservación del patrimonio tamil
En términos simples, TamilSTARNet ofrece a los ordenadores una forma más cuidadosa de mirar el tamil manuscrito: primero organiza la página desordenada en piezas bien separadas y luego estudia cada carácter con atención focalizada en los trazos que importan. Esta combinación permite que el sistema lea caligrafías complejas con mucha más fiabilidad que las herramientas anteriores. Aunque siguen existiendo casos difíciles—como escrituras altamente estilizadas o páginas gravemente dañadas—el enfoque supone un paso práctico hacia la digitalización a gran escala de textos en tamil. A medida que estos sistemas mejoren y se generalicen, cuadernos, cartas y manuscritos antiguos podrán convertirse en bibliotecas digitales buscables, ayudando a asegurar que el patrimonio literario del tamil no solo se salve del deterioro físico, sino que también resulte más accesible para las generaciones futuras.
Cita: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Palabras clave: OCR manuscrito en tamil, digitalización de documentos, redes neuronales basadas en atención, preservación del patrimonio cultural, reconocimiento de escritura