Clear Sky Science · en
TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters
Bringing Old Tamil Writing into the Digital Age
All over South India and beyond, precious stories, poems, and records written in Tamil sit locked inside fading paper, palm leaves, and notebooks. Because much of this material is handwritten, computers struggle to read it, which means large parts of Tamil culture remain hard to search, share, or study. This paper introduces TamilSTARNet, a new computer vision system designed specifically to read handwritten Tamil, so that centuries of heritage can be preserved and accessed in digital form.
Why Handwritten Tamil Is Hard for Computers
Tamil script is rich and expressive: a small set of basic vowels and consonants combine into more than 300 compound characters. On the page, these letters flow together with loops, curves, and small marks above, below, and beside the main strokes. People write them in many personal styles, with strokes that join, overlap, or vary in thickness. Standard Optical Character Recognition (OCR) tools, which work well on neatly printed English text, often fail here. They misread joined letters, lose tiny marks that change meanings, and stumble when ink is faded or spacing is irregular. Existing research for Tamil has made progress using handcrafted rules or generic neural networks, but most methods either assume clean characters cut out one by one, or break down when characters touch and crowd together.
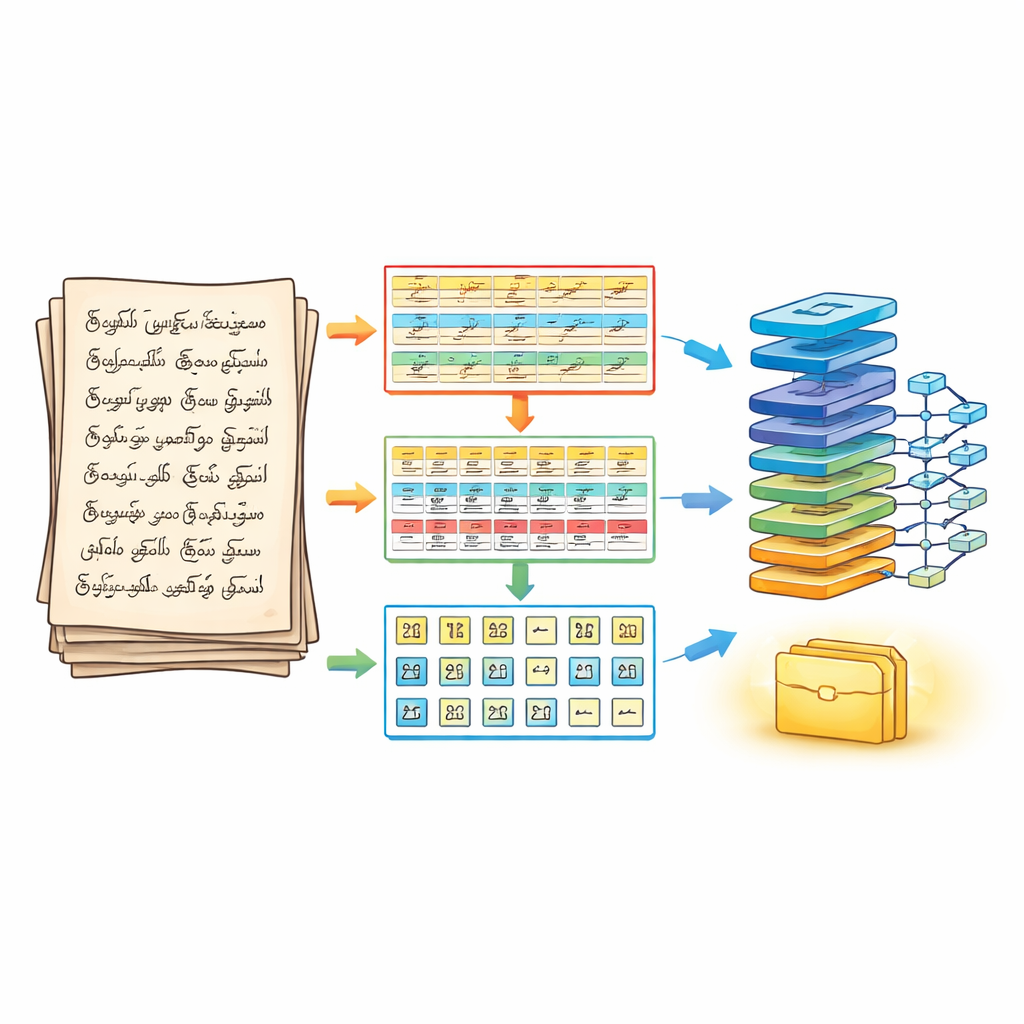
A Three-Step Way to Slice Up the Page
To tackle this, the authors first redesign how a page is split before any recognition happens. Their tri-phase segmentation pipeline treats a handwritten document like a layered puzzle. In the first phase, the page is cleaned and sharpened using standard image-processing steps, then divided into horizontal lines of text. In the second phase, each line is broken into separate words, carefully adjusting how much neighboring strokes are merged so that tiny vowel marks are not lost. In the third phase, every word is further split into individual characters using contours and bounding boxes that follow the actual ink strokes. The result is a structured three-dimensional array—line, word, character—that preserves reading order while delivering clearly isolated characters to the recognition engine.
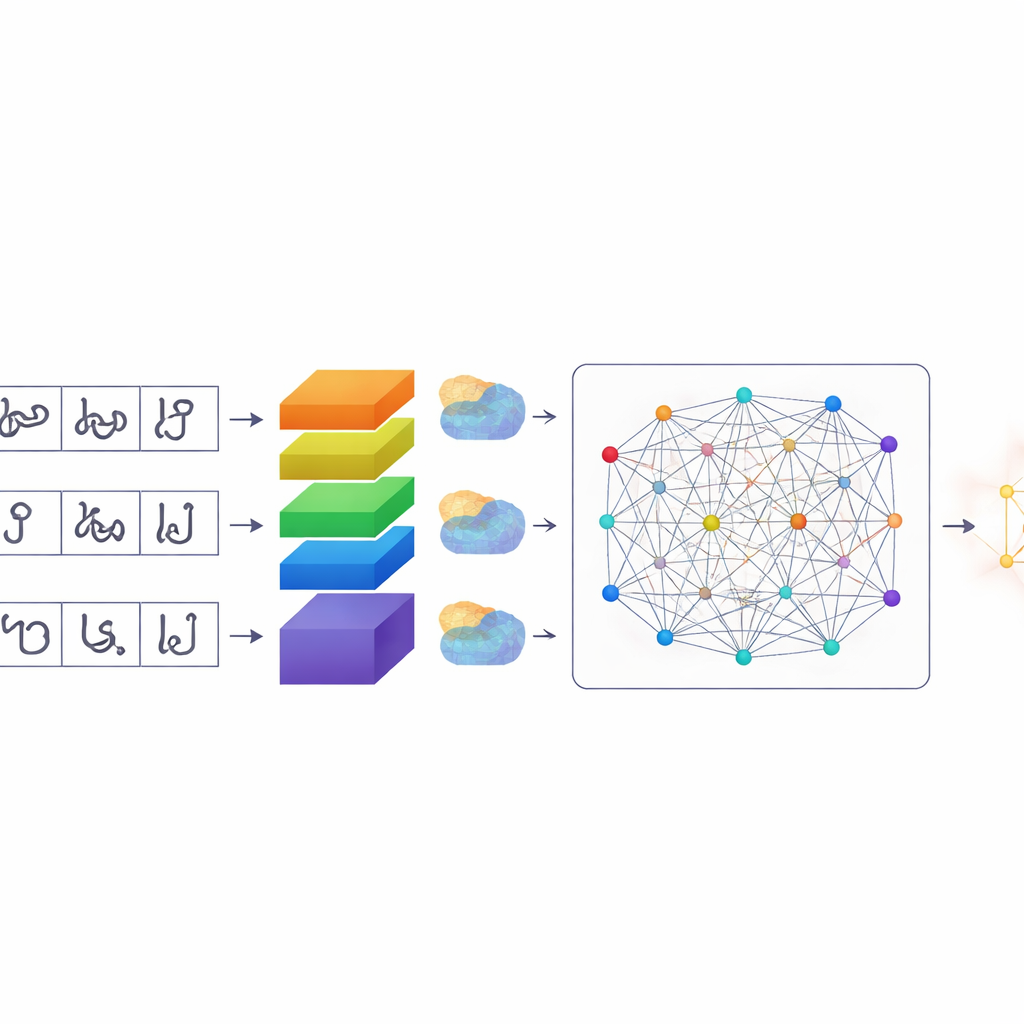
A Smarter Way for Computers to Pay Attention
Once the characters are segmented, TamilSTARNet uses a tailored deep-learning model to figure out what each one is. At its core is a stack of convolutional layers that learn visual patterns from the images. On top of this, the authors add several kinds of “attention” mechanisms. These modules help the network decide which parts of the image and which internal features matter most. One component highlights specific channels that capture subtle stroke differences—exactly the small hooks and loops that distinguish similar Tamil letters. Another component focuses on where important strokes lie on the character’s surface. A final self-attention layer looks across the whole character at once, linking distant strokes that together define its shape. By combining these forms of attention, the system becomes better at teasing apart characters that differ only by a tiny mark or curve.
How Well the System Performs
The researchers tested TamilSTARNet on two large public datasets that together contain more than 160,000 examples spanning 156 character classes from hundreds of writers. After training, the model correctly recognized about 96% of test characters, outperforming well-known alternatives such as Tesseract OCR and several deep neural network baselines. The tri-phase segmentation also proved important: when the same recognition model was used without this careful line–word–character splitting, accuracy and reliability dropped. The team further evaluated their approach on challenging palm-leaf manuscripts, where ink is faint and surfaces are irregular. Performance was naturally lower in this harsh setting but still strong enough to show that the method can extend to real historical materials.
What This Means for Preserving Tamil Heritage
In simple terms, TamilSTARNet gives computers a more careful way to look at handwritten Tamil: it first organizes the messy page into well-separated pieces, then studies each character with focused attention on the strokes that matter. This combination lets the system read complex handwriting far more reliably than previous tools. While difficult cases remain—such as highly stylized writing or severely damaged pages—the approach marks a practical step toward large-scale digitization of Tamil texts. As such systems improve and spread, old notebooks, letters, and manuscripts can be turned into searchable digital libraries, helping ensure that Tamil’s literary heritage is not only saved from physical decay but also made easier for future generations to explore.
Citation: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Keywords: Tamil handwritten OCR, document digitization, attention-based neural networks, cultural heritage preservation, script recognition