Clear Sky Science · nl
TamilSTARNet: segmentatie via driefasige architectuur en aandacht-gebaseerde herkenning voor handgeschreven Tamil-tekens
Oud Tamil-schrift naar het digitale tijdperk brengen
In heel Zuid-India en daarbuiten liggen kostbare verhalen, gedichten en registers in het Tamil opgesloten op verblekend papier, palmbladeren en notitieboekjes. Omdat veel van dit materiaal met de hand is geschreven, hebben computers er moeite mee om het te lezen, waardoor grote delen van de Tamil-cultuur moeilijk doorzoekbaar, deelbaar of bestudeerbaar zijn. Dit artikel introduceert TamilSTARNet, een nieuw computer vision-systeem dat specifiek is ontworpen om handgeschreven Tamil te lezen, zodat eeuwen aan erfgoed bewaard en digitaal toegankelijk gemaakt kunnen worden.
Waarom handgeschreven Tamil moeilijk is voor computers
Het Tamil-schrift is rijk en expressief: een kleine set basisklinkers en -medeklinkers combineert tot meer dan 300 samengestelde tekens. Op de pagina vloeien deze letters samen met lussen, krommingen en kleine tekens boven, onder en naast de hoofdstrepen. Mensen schrijven ze in vele persoonlijke stijlen, met streken die samenkomen, overlappen of in dikte variëren. Standaard Optical Character Recognition (OCR)-tools, die goed werken op netjes gedrukt Engels, falen hier vaak. Ze lezen samengevoegde letters verkeerd, missen kleine tekens die de betekenis veranderen en struikelen bij vervaagde inkt of onregelmatige spatiëring. Bestaand onderzoek naar Tamil heeft vooruitgang geboekt met handgemaakte regels of generieke neurale netwerken, maar de meeste methoden veronderstellen ofwel schone tekens die één voor één zijn uitgesneden, of falen wanneer tekens elkaar raken en dicht op elkaar staan.
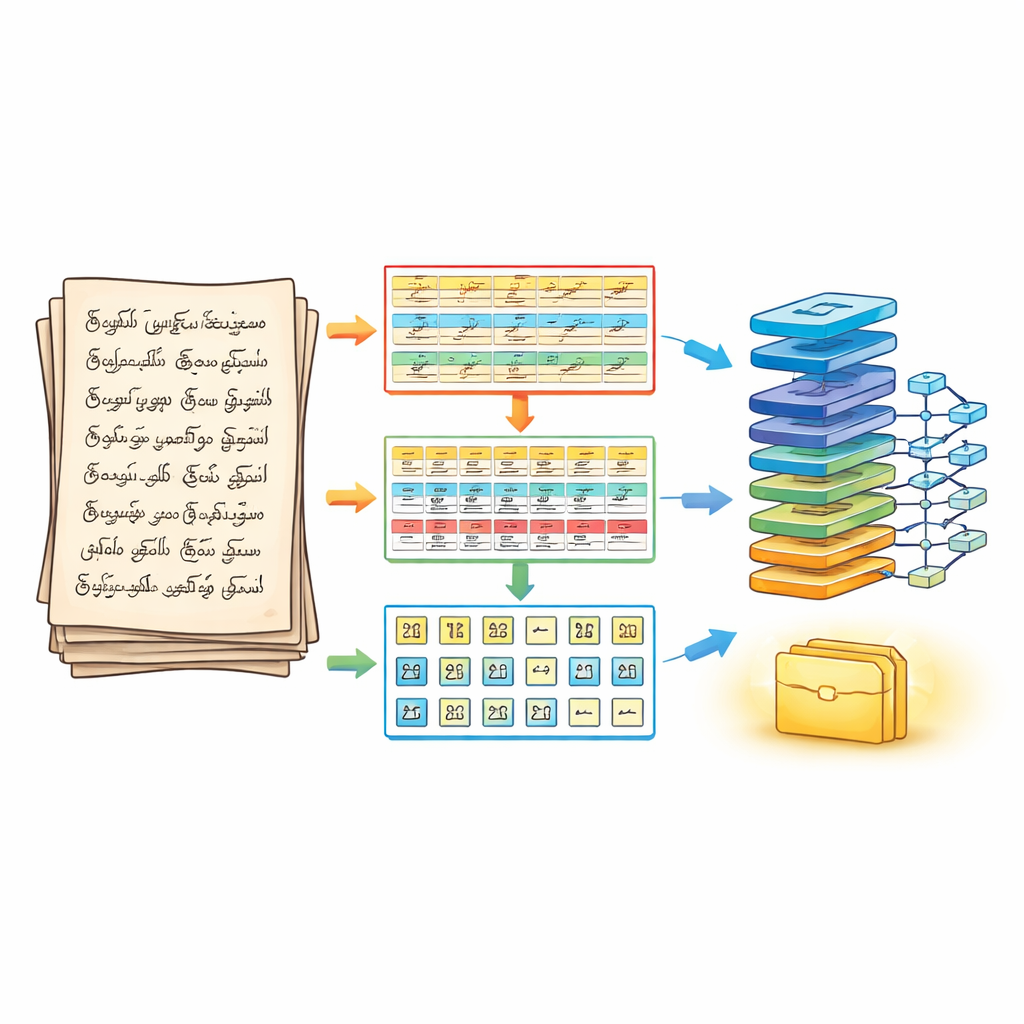
Een driedelige methode om de pagina op te delen
Om dit aan te pakken, herontwerpen de auteurs eerst hoe een pagina wordt opgesplitst voordat enige herkenning plaatsvindt. Hun driefasige segmentatie-pijplijn behandelt een handgeschreven document als een gelaagde puzzel. In de eerste fase wordt de pagina schoongemaakt en verscherpt met standaard beeldverwerkingstechnieken en vervolgens verdeeld in horizontale tekstregels. In de tweede fase wordt elke regel opgesplitst in afzonderlijke woorden, waarbij zorgvuldig wordt bijgesteld hoeveel aangrenzende streken samensmelten zodat kleine klinkertekens niet verloren gaan. In de derde fase wordt elk woord verder opgesplitst in individuele tekens met behulp van contouren en begrenzingskaders die de werkelijke inktstreken volgen. Het resultaat is een gestructureerde driedimensionale array—regel, woord, teken—die de leesvolgorde behoudt en tegelijk duidelijk geïsoleerde tekens aan de herkenningsmotor levert.
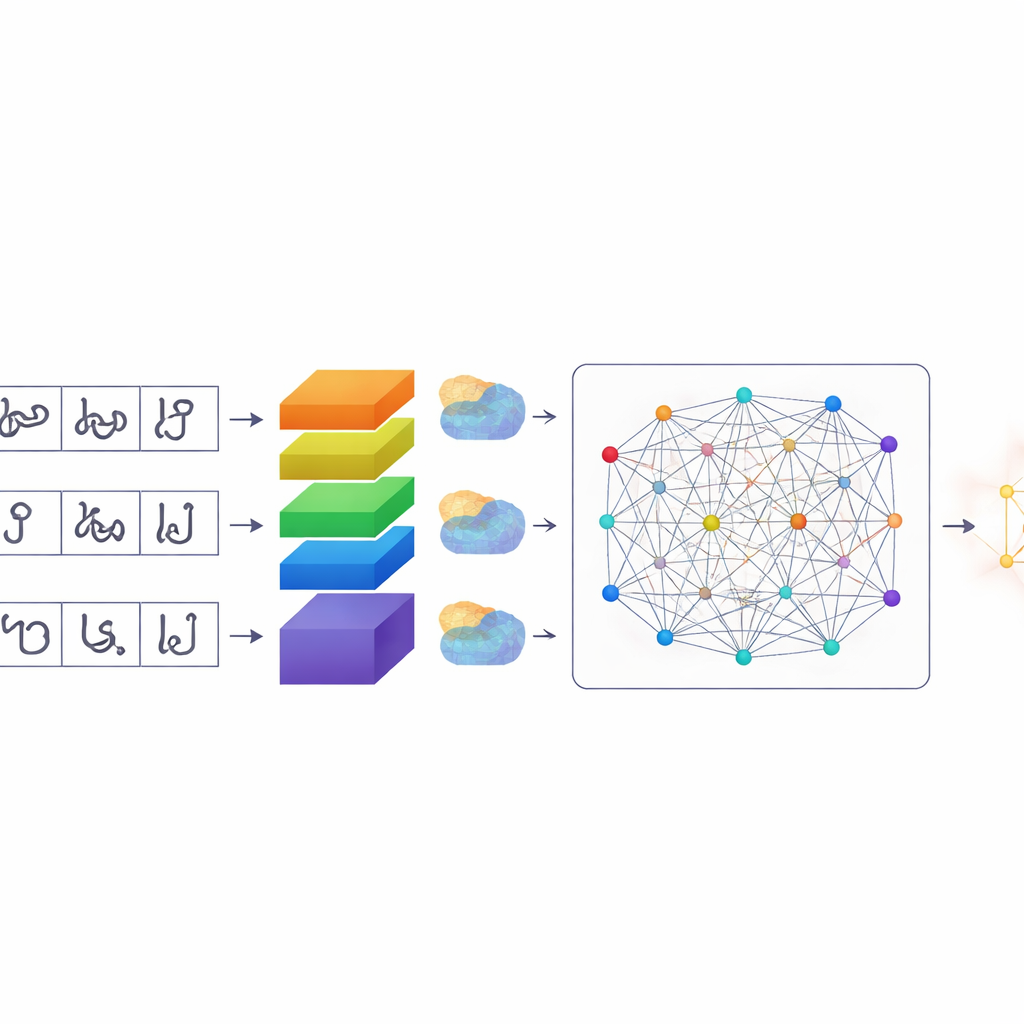
Een slimmer mechanisme zodat computers aandachtig kijken
Zodra de tekens zijn gesegmenteerd, gebruikt TamilSTARNet een op maat gemaakt deep-learningmodel om te bepalen welk teken elk exemplaar is. Centraal staat een stapel convolutionele lagen die visuele patronen uit de beelden leren. Daarbovenop voegen de auteurs meerdere soorten "attention"-mechanismen toe. Deze modules helpen het netwerk beslissen welke delen van het beeld en welke interne kenmerken het meest relevant zijn. Een component benadrukt specifieke kanalen die subtiele stroke-verschillen vastleggen—precies die kleine haken en lussen die vergelijkbare Tamil-letters van elkaar onderscheiden. Een andere component richt zich op waar belangrijke streken op het oppervlak van het teken liggen. Een laatste self-attention-laag kijkt tegelijk naar het hele teken en koppelt verre streken die samen de vorm bepalen. Door deze vormen van aandacht te combineren, wordt het systeem beter in het uit elkaar houden van tekens die alleen door een klein teken of een kromming verschillen.
Hoe goed het systeem presteert
De onderzoekers testten TamilSTARNet op twee grote publieke datasets die samen meer dan 160.000 voorbeelden bevatten, verspreid over 156 tekenklassen van honderden schrijvers. Na training herkende het model ongeveer 96% van de testtekens correct, en overtrof daarmee bekende alternatieven zoals Tesseract OCR en verschillende diepe neurale-netwerk-baselines. De driefasige segmentatie bleek ook van belang: wanneer hetzelfde herkenningsmodel zonder deze zorgvuldige regel–woord–teken opsplitsing werd gebruikt, daalden nauwkeurigheid en betrouwbaarheid. Het team evalueerde de aanpak ook op uitdagende palmbladdocumenten, waar de inkt zwak is en de oppervlakken onregelmatig. De prestaties waren in deze zware omstandigheden uiteraard lager, maar nog steeds sterk genoeg om te laten zien dat de methode toepasbaar is op echte historische materialen.
Wat dit betekent voor het behoud van Tamil-erfgoed
In eenvoudige bewoordingen geeft TamilSTARNet computers een zorgvuldiger manier om handgeschreven Tamil te bekijken: het organiseert eerst de rommelige pagina in goed gescheiden onderdelen en bestudeert vervolgens elk teken met gerichte aandacht voor de streken die ertoe doen. Deze combinatie maakt dat het systeem complex handschrift veel betrouwbaarder kan lezen dan eerdere tools. Hoewel moeilijke gevallen blijven bestaan—zoals sterk gestileerd schrijven of ernstig beschadigde pagina’s—markeert de aanpak een praktische stap richting grootschalige digitalisering van Tamil-teksten. Naarmate dergelijke systemen verbeteren en zich verspreiden, kunnen oude notitieboekjes, brieven en manuscripten worden omgezet in doorzoekbare digitale bibliotheken, wat helpt om het literaire erfgoed van het Tamil niet alleen tegen fysieke verval te beschermen, maar ook gemakkelijker toegankelijk te maken voor toekomstige generaties.
Bronvermelding: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Trefwoorden: Tamil handgeschreven OCR, documentendigitalisatie, aandacht-gebaseerde neurale netwerken, behoud van cultureel erfgoed, schriftherkenning