Clear Sky Science · pl
TamilSTARNet: segmentacja za pomocą trójfazowej architektury i rozpoznawanie oparte na mechanizmach uwagi dla pisma ręcznego w języku tamilski
Wprowadzenie starożytnego pisma tamilskiego w erę cyfrową
W całym południowych Indiach i poza nimi znajdują się bezcenne opowieści, wiersze i zapisy napisane po tamilski, uwięzione na blaknącym papierze, liściach palmowych i w zeszytach. Ponieważ wiele z tych materiałów jest pisanych ręcznie, komputery mają z nimi trudności, co sprawia, że duże fragmenty kultury tamilskiej są trudne do wyszukania, udostępniania czy badania. Artykuł przedstawia TamilSTARNet, nowy system widzenia komputerowego zaprojektowany specjalnie do odczytu ręcznego pisma tamilskiego, aby wieki dziedzictwa mogły zostać zachowane i udostępnione w formie cyfrowej.
Dlaczego ręczne pismo tamilskie jest trudne dla komputerów
Skrypt tamilский jest bogaty i ekspresyjny: niewielki zestaw podstawowych samogłosek i spółgłosek łączy się w ponad 300 znaków złożonych. Na stronie litery płynnie łączą się w pętle, krzywe i drobne znaki nad, pod i obok głównych kresk. Ludzie piszą je w wielu osobistych stylach, ze kreskami łączącymi się, nakładającymi lub o zmiennej grubości. Standardowe narzędzia OCR, które dobrze działają na schludnie drukowanym tekście angielskim, często zawodzą tutaj. Błędnie odczytują połączone litery, pomijają maleńkie znaki zmieniające znaczenie i mają problemy przy wyblakłym tuszu lub nieregularnych odstępach. Dotychczasowe badania nad tamilskim poczyniły postęp, stosując reguły ręcznie opracowane lub ogólne sieci neuronowe, lecz większość metod albo zakłada czyste, pojedynczo wycięte znaki, albo zawodzi, gdy znaki stykają się i tłoczą.
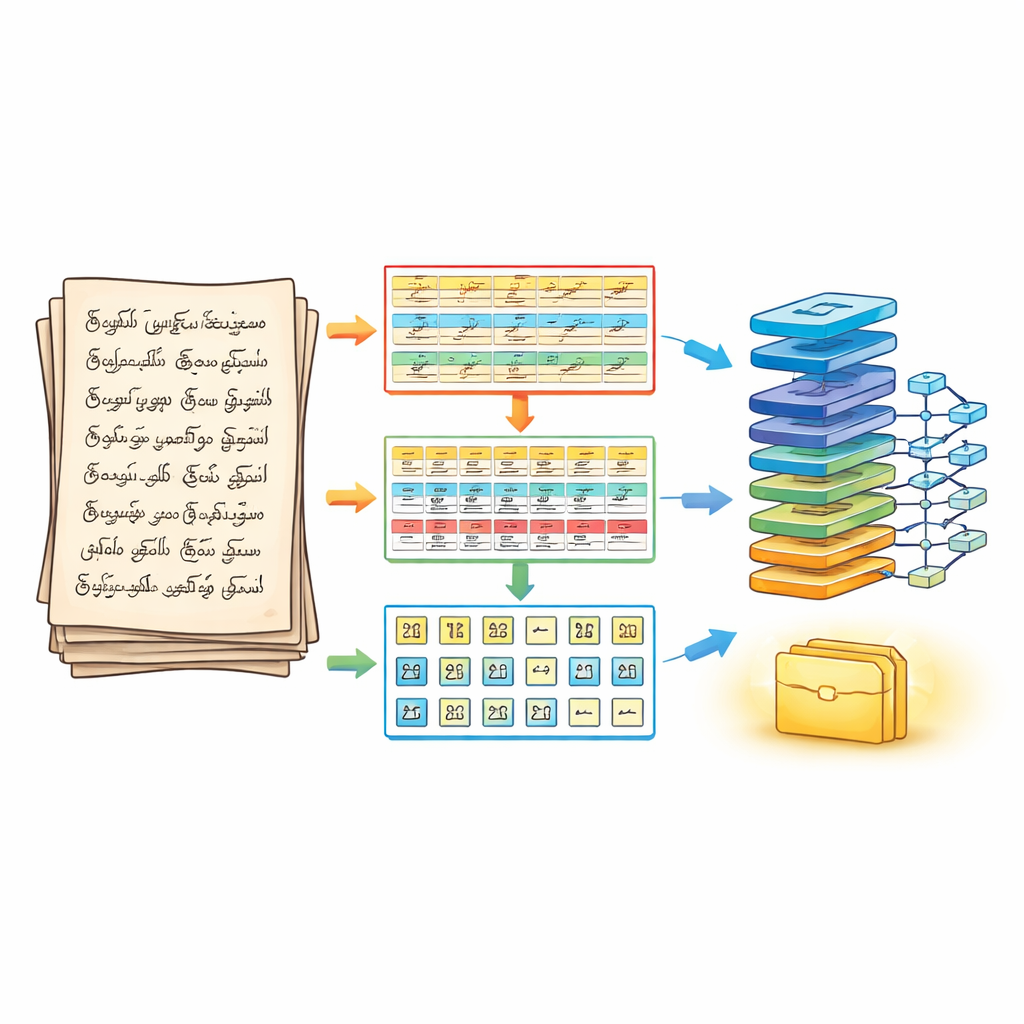
Trzystopniowy sposób dzielenia strony
Aby poradzić sobie z tym problemem, autorzy najpierw przeprojektowali sposób, w jaki strona jest dzielona przed jakimkolwiek rozpoznawaniem. Ich trójfazowy pipeline segmentacji traktuje ręcznie pisany dokument jak warstwową układankę. W pierwszej fazie strona jest oczyszczana i wyostrzana przy użyciu standardowych kroków przetwarzania obrazu, a następnie dzielona na poziome linie tekstu. W drugiej fazie każda linia jest rozbijana na oddzielne słowa, z ostrożnym dostosowaniem stopnia łączenia sąsiednich kresek, tak aby drobne znaki samogłoskowe nie zostały utracone. W trzeciej fazie każde słowo jest dalej dzielone na pojedyncze znaki przy użyciu konturów i ram ograniczających, które podążają za rzeczywistymi śladami atramentu. Efektem jest uporządkowana trójwymiarowa tablica — linia, słowo, znak — która zachowuje kolejność czytania, dostarczając jednocześnie wyraźnie wyizolowane znaki do modułu rozpoznawania.
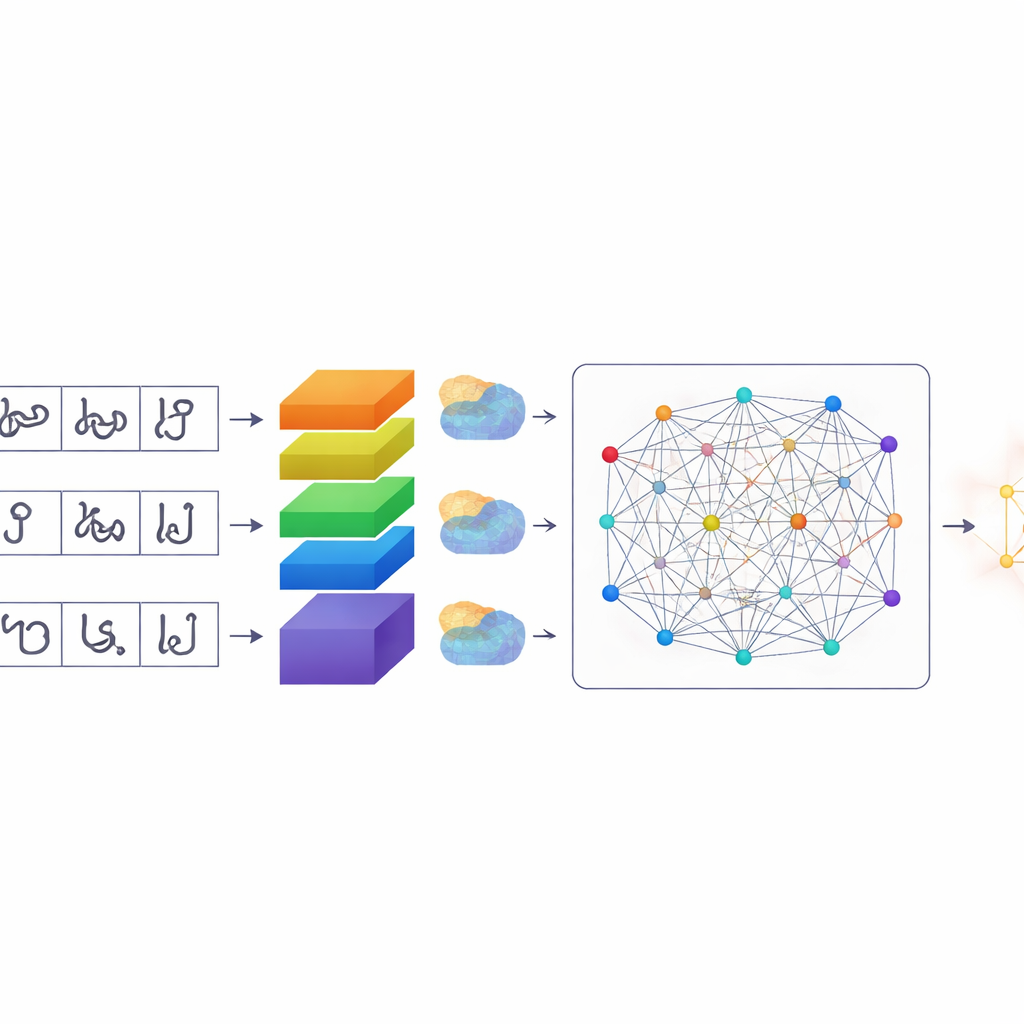
Inteligentniejszy sposób, w jaki komputery zwracają uwagę
Gdy znaki są już zsegmentowane, TamilSTARNet używa dostosowanego modelu głębokiego uczenia, by ustalić, czym jest każdy z nich. W rdzeniu modelu znajduje się stos warstw konwolucyjnych, które uczą się wzorców wizualnych z obrazów. Na jego szczycie autorzy dodają kilka rodzajów mechanizmów „uwagi”. Moduły te pomagają sieci zdecydować, które części obrazu i które wewnętrzne cechy są najistotniejsze. Jeden składnik uwydatnia konkretne kanały przechwytujące subtelne różnice w kreskach — dokładnie te małe haczyki i pętle, które rozróżniają podobne litery tamilski. Inny składnik koncentruje się na lokalizacji ważnych kresek na powierzchni znaku. Ostateczna warstwa samouwagi przygląda się całemu znakowi naraz, łącząc odległe kreski, które razem definiują jego kształt. Łącząc te formy uwagi, system staje się lepszy w rozróżnianiu znaków różniących się jedynie minimalnym znakiem lub krzywizną.
Jak dobrze działa system
Badacze przetestowali TamilSTARNet na dwóch dużych publicznych zbiorach danych, które łącznie zawierają ponad 160 000 przykładów obejmujących 156 klas znaków odsetek setek pism. Po treningu model poprawnie rozpoznawał około 96% znaków testowych, przewyższając znane alternatywy, takie jak Tesseract OCR, oraz kilka bazowych modeli głębokich sieci neuronowych. Trójfazowa segmentacja okazała się również istotna: gdy ten sam model rozpoznawania zastosowano bez ostrożnego podziału linia–słowo–znak, dokładność i niezawodność spadły. Zespół dodatkowo ocenił podejście na wymagających manuskryptach na liściach palmowych, gdzie tusz jest słaby, a powierzchnie nieregularne. W trudniejszych warunkach wydajność naturalnie była niższa, lecz nadal wystarczająco wysoka, by pokazać, że metoda może być stosowana w pracy z rzeczywistymi materiałami historycznymi.
Co to oznacza dla zachowania dziedzictwa tamilskiego
Mówiąc prosto, TamilSTARNet daje komputerom bardziej starannie przemyślany sposób patrzenia na ręczne pismo tamilski: najpierw organizuje zabałaganioną stronę w dobrze rozdzielone fragmenty, a potem bada każdy znak z ukierunkowaną uwagą na kreski, które mają znaczenie. To połączenie pozwala systemowi czytać złożone pismo ręczne znacznie bardziej niezawodnie niż wcześniejsze narzędzia. Chociaż trudne przypadki nadal się zdarzają — takie jak wysoce stylizowane pismo czy silnie zniszczone strony — podejście to stanowi praktyczny krok w kierunku masowej digitalizacji tekstów tamilski. W miarę jak takie systemy będą się poprawiać i rozpowszechniać, stare zeszyty, listy i manuskrypty będą mogły zostać przekształcone w przeszukiwalne biblioteki cyfrowe, co pomoże zapewnić, że literackie dziedzictwo Tamilu nie tylko zostanie uchronione przed fizycznym rozkładem, ale także stanie się łatwiejsze do odkrywania dla przyszłych pokoleń.
Cytowanie: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Słowa kluczowe: ręczne OCR tamilski, digitalizacja dokumentów, sieci neuronowe oparte na uwadze, ochrona dziedzictwa kulturowego, rozpoznawanie pisma