Clear Sky Science · ru
TamilSTARNet: сегментация через трифазную архитектуру и распознавание на основе внимания для рукописных тамильских символов
Переход древнего тамильского письма в цифровую эпоху
По всей Южной Индии и за её пределами драгоценные рассказы, поэмы и записи на тамильском языке заперты в угасающей бумаге, пальмовых листьях и тетрадях. Поскольку большая часть этих материалов рукописная, компьютеры затрудняются с их чтением, поэтому большие пласты тамильской культуры остаются труднодоступными для поиска, обмена и изучения. В этой статье представлена TamilSTARNet — новая система компьютерного зрения, разработанная специально для чтения рукописного тамильского, чтобы столетия наследия можно было сохранять и делать доступными в цифровом виде.
Почему рукописный тамиль сложен для компьютеров
Тамильское письмо богато и выразительно: небольшой набор базовых гласных и согласных комбинируется в более чем 300 составных знаков. На странице эти буквы сливаются в потоке с петлями, кривыми и мелкими метками над, под и рядом с основными штрихами. Люди пишут их в самых разных индивидуальных стилях, со штрихами, которые соединяются, перекрываются или меняют толщину. Стандартные средства оптического распознавания символов (OCR), которые хорошо работают на аккуратно напечатанном английском тексте, часто не справляются здесь. Они неправильно читают соединённые буквы, теряют крошечные метки, меняющие смысл, и ошибаются при выцветании чернил или нерегулярном интервале. Существующие исследования по тамилу достигли прогресса, используя вручную разработанные правила или универсальные нейросети, но большинство методов либо предполагают чистые символы, вырезанные поодиночке, либо ломаются, когда знаки соприкасаются и тесно расположены.
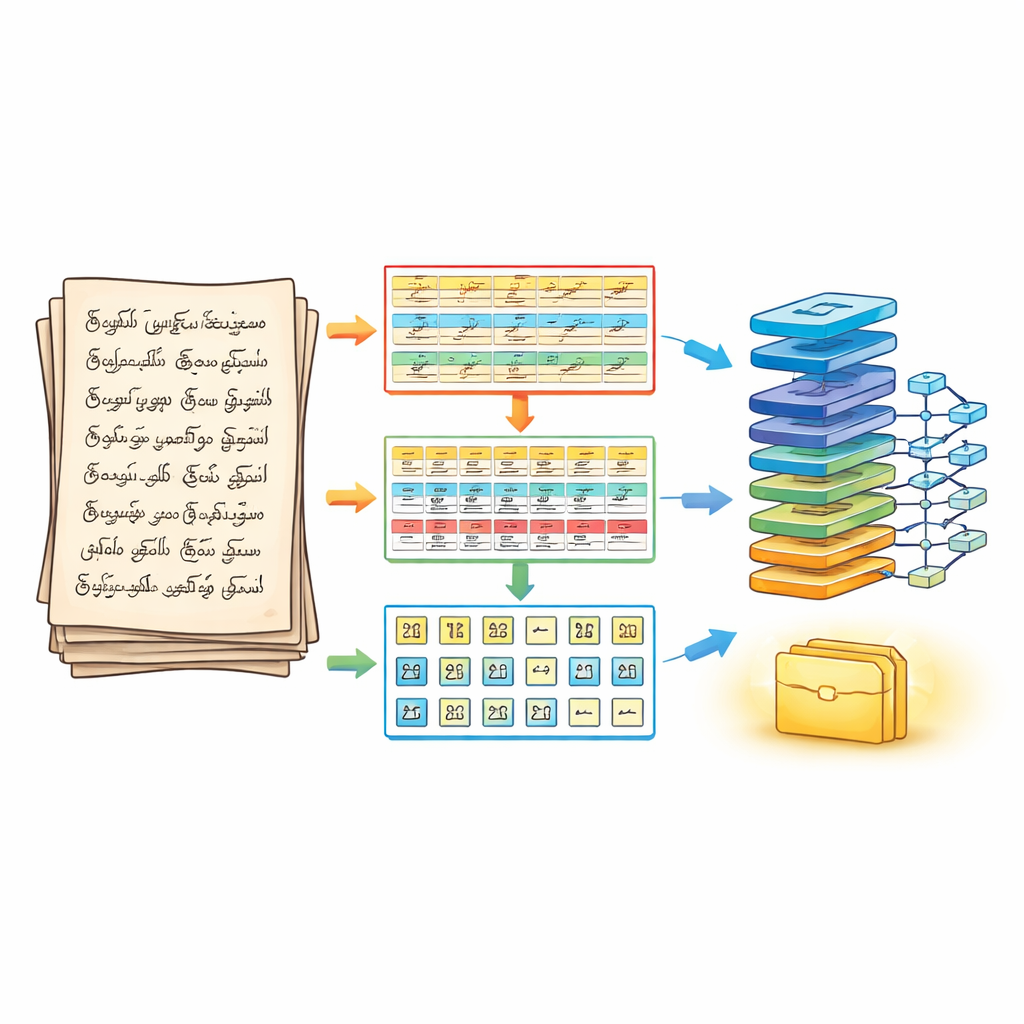
Трифазный подход к разбиению страницы
Чтобы решить эту проблему, авторы сначала переработали способ разбиения страницы до этапа распознавания. Их трифазный конвейер сегментации рассматривает рукописный документ как многослойную головоломку. На первой фазе страница очищается и усиливается с помощью стандартных приёмов обработки изображений, затем делится на горизонтальные строки текста. На второй фазе каждая строка разбивается на отдельные слова с аккуратной настройкой степени слияния соседних штрихов, чтобы не потерялись крошечные гласные метки. На третьей фазе каждое слово дополнительно разделяется на отдельные символы с использованием контуров и ограничивающих рамок, которые следуют реальным штрихам чернил. В результате получается структурированный трёхмерный массив — строка, слово, символ — который сохраняет порядок чтения и при этом предоставляет движку распознавания чётко изолированные символы.
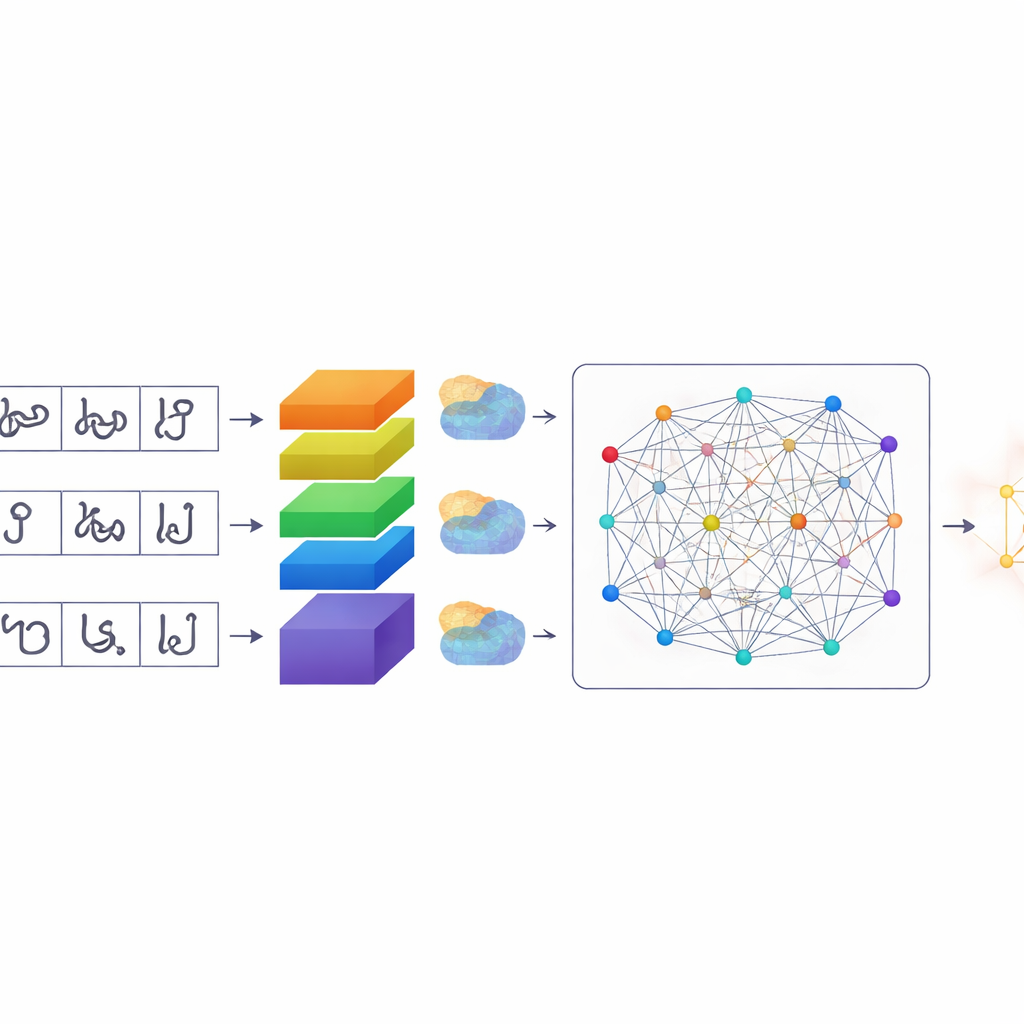
Более продуманный способ привлечь внимание компьютера
После сегментации символов TamilSTARNet использует специально адаптированную модель глубокого обучения, чтобы определить, что представляет собой каждый символ. В её основе лежит стек сверточных слоёв, которые изучают визуальные паттерны на изображениях. Поверх этого авторы добавляют несколько видов механизмов «внимания». Эти модули помогают сети решить, какие части изображения и какие внутренние признаки наиболее важны. Один компонент выделяет определённые каналы, захватывающие тонкие различия штрихов — именно те маленькие крючки и петли, которые отличают похожие тамильские символы. Другой компонент фокусируется на том, где на поверхности символа расположены важные штрихи. Финальный слой самовнимания смотрит на весь символ целиком, связывая удалённые штрихи, которые вместе формируют его форму. Комбинируя эти виды внимания, система становится лучше в разделении символов, отличающихся лишь крошечной меткой или изломом.
Насколько хорошо работает система
Исследователи протестировали TamilSTARNet на двух больших публичных наборах данных, которые вместе содержат более 160 000 примеров, охватывающих 156 классов символов от сотен писавших. После обучения модель правильно распознавала около 96% тестовых символов, превосходя известные альтернативы, такие как Tesseract OCR, и несколько базовых глубоких нейросетевых подходов. Трифазная сегментация также оказалась важной: когда ту же модель распознавания использовали без тщательного разбиения на строки–слова–символы, точность и надёжность снижались. Команда дополнительно оценила свой подход на сложных рукописях на пальмовых листьях, где чернила слабы, а поверхности неровны. В таких суровых условиях производительность естественно была ниже, но всё ещё достаточно высокой, чтобы показать, что метод применим к реальным историческим материалам.
Что это значит для сохранения тамильского наследия
Проще говоря, TamilSTARNet даёт компьютерам более аккуратный способ смотреть на рукописный тамиль: сначала система организует беспорядочную страницу в хорошо разделённые фрагменты, затем изучает каждый символ с фокусировкой на штрихах, которые имеют значение. Такое сочетание позволяет системе читать сложные рукописи гораздо надёжнее по сравнению с предыдущими инструментами. Хотя остаются трудные случаи — например, сильно стилизованное письмо или сильно повреждённые страницы — этот подход представляет практический шаг к масштабной оцифровке тамильских текстов. По мере улучшения и распространения таких систем старые тетради, письма и рукописи смогут превращаться в поисковые цифровые библиотеки, помогая обеспечить сохранность литературного наследия тамильского языка и облегчая его изучение будущими поколениями.
Цитирование: Anbalagan, S., Krishna, H., Raju, J.S. et al. TamilSTARNet: segmentation via tri-phase architecture and attention-based recognition for handwritten Tamil characters. npj Herit. Sci. 14, 258 (2026). https://doi.org/10.1038/s40494-026-02335-8
Ключевые слова: распознавание рукописного тамильского текста, оцифровка документов, нейросети с механизмом внимания, сохранение культурного наследия, распознавание письма