Clear Sky Science · tr
Hata-toleranslı sık öğe kümelerini çıkarmada örüntü-büyüme yaklaşımı
Dağınık Veride Güvenilir Örüntüleri Bulmak
Alışveriş kayıtları, tıbbi günlükler ve sensör okumaları nadiren kusursuzdur. Barkodlar kaçırılır, sensörler arızalanır ve tıklamalar kaydedilmez. Buna rağmen işletmeler ve bilim insanları hâlâ hangi öğelerin birlikte güvenilir şekilde ortaya çıktığını bilmek ister—örneğin ürün paketleri, semptom kümeleri veya dolandırıcılık uyarıları. Bu makale, böyle gürültülü verilerden güçlü tekrarlayan birleşimleri ortaya çıkarmanın yeni bir yolunu sunar ve bildirilen örüntü sayısını küçük ve yönetilebilir tutar.
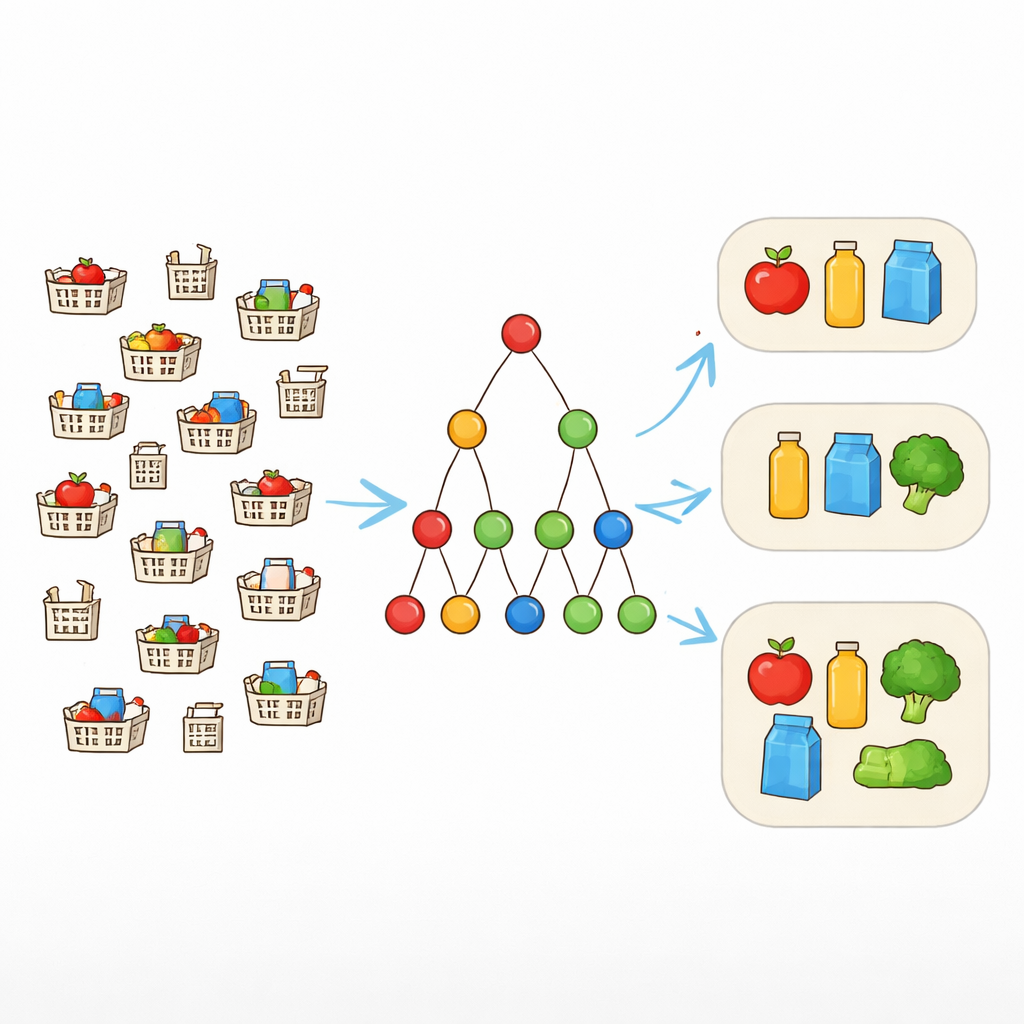
Kesin Eşleşmelerden Esnek Örüntülere
Geleneksel örüntü-madenciliği araçları, birçok kayıtta tam olarak aynı görünen öğe birleşimlerini arar. Bu ancak veriler temiz olduğunda iyi çalışır. Gerçek dünyada, aynı paketi “içermesi gereken” alışveriş sepetleri bir ya da iki öğe farklı olabilir. Bunu ele almak için araştırmacılar hata toleransı kavramını kullanır. Bir örüntüdeki her öğenin her seferinde bulunmasını şart koşmak yerine, seçilen sayıda eksik öğeye izin verilir. Örneğin örüntü {laptop, mouse, klavye, kulaklık} ise ve tolerans birse, bu dört öğeden en az üçünü içeren her işlem hâlâ örüntüyü destekliyor sayılır. Bu, algoritmanın hafifçe değişen biçimlerde ortaya çıkan gerçekçi paketleri tanımasını sağlar.
En Büyük Örüntülere Odaklanmanın Önemi
Eksik öğelere izin vermek, örüntülerin sık sayılmasını kolaylaştırır ama arama uzayını patlatır. Özellikle büyük perakende veya web veri kümelerinde, farklı boyutlarda birçok örtüşen örüntü mümkün hale gelir. Hepsini listelemek hem bilgisayarları hem de analistleri bunaltır. Bunun yerine yazar, genişletilemeyen—yani başka bir öğe eklenerek sık olmaktan çıkan—maksimal örüntülere odaklanır. Bu maksimal hata-toleranslı örüntüler özlü bir özet sağlar: her daha küçük sık birleşim en az birinin içinde yer alır ve gerekirse sonra yeniden oluşturulabilir.
Sıkıştırılmış Bir Ağaç İçinde Örüntüleri Büyütme
Önceki hata-toleranslı yöntemler büyük ölçüde aday örüntüleri seviye seviye üreten ve test eden klasik bir yaklaşımı genişletti. Bu strateji, tam veri kümesinin tekrar tekrar taranmasından ve çok sayıda adaydan muzdariptir. FT-MFI-PG adlı yeni algoritma, örüntü-büyüme ilhamı alarak farklı bir yol izler. Önce aynı başlangıç öğelerini paylaşan işlemleri birleştiren kompakt bir ağaç yapısı inşa eder. Bu ağacın her yolu birçok benzer kaydı temsil eder, böylece veriyi önemli ölçüde küçültürken hangi öğelerin birlikte görünme eğiliminde olduğunu korur. Bunun üzerine, bazı öğeler eksik olsa bile öğelerin ne sıklıkla birlikte ortaya çıktığını kaydeden küçük tablolar eklenir, böylece hata toleransı orijinal veriye yeniden bakmadan yerel olarak değerlendirilebilir.
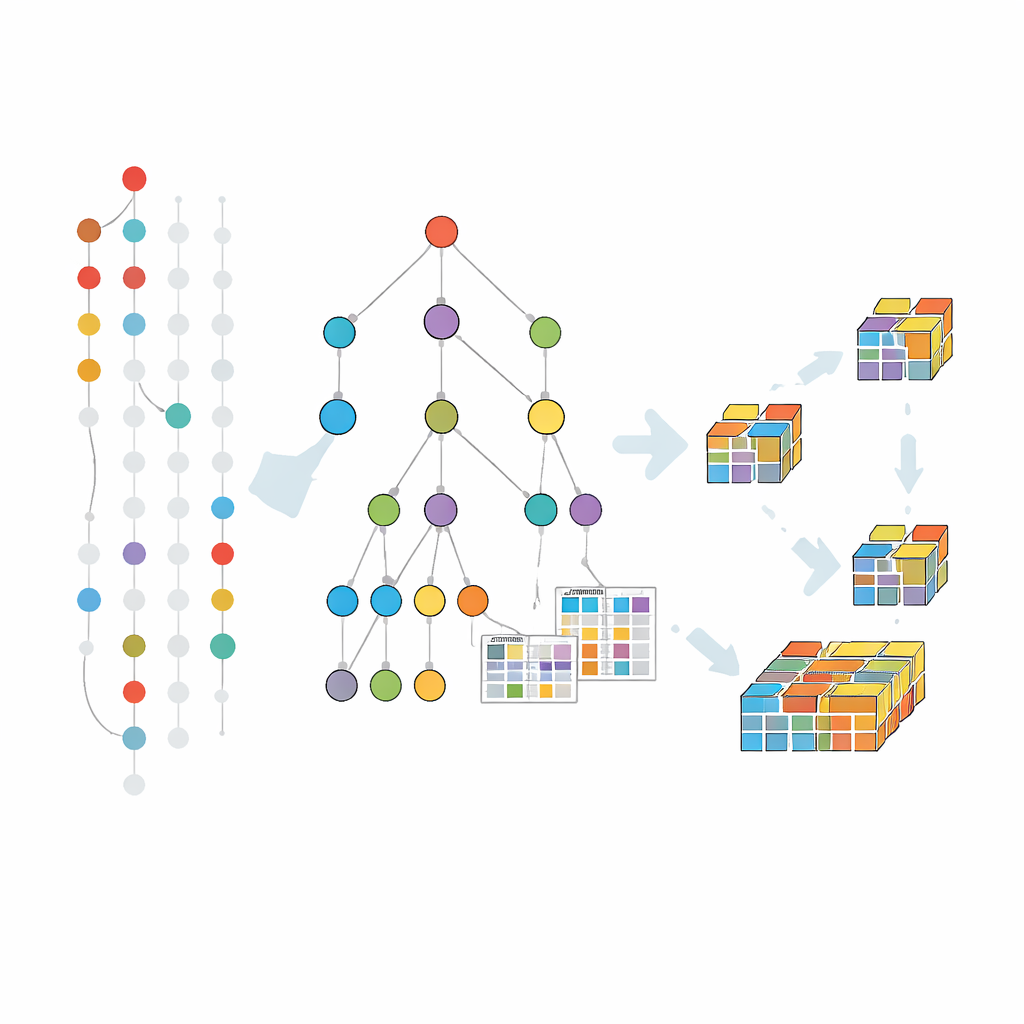
Yöntemin Nasıl Çalıştığına Yakından Bakış
Madencilik, ağacı küçükten büyüğe doğru keşfederek ilerler, ancak yalnızca verilerin anlamlı genişletmelerin varlığını gösterdiği yerlerde. Her umut verici öğe grubuyla, algoritma onları destekleyen işlem alt kümesini toplar—seçilen toleransa göre eksik öğelere izin vererek—ve sonra o gruba odaklanan daha küçük bir ağaç kurar. Bu böl ve yönet süreci tekrarlanır, örüntüler adım adım büyütülür ve sık, hata-toleranslı birleşimlere götürmesi mümkün olmayan dallar budanır. Ek budama hileleri, zaten bilinen maksimal örüntüler tarafından kapsanan arama alanlarını atlamaya yardımcı olur; bu da zaman ve bellek tasarrufu sağlar.
Deneyler Ne Gösteriyor
Yazar, yeni yöntemi perakende, web tarama ve sentetik işlem verilerinden alınmış birkaç standart kıyas veri kümesinde test etti. Farklı tolerans seviyeleri ve sıklık eşiklerinde, örüntü-büyüme algoritması rakip tekniklere göre tutarlı biçimde tüm maksimal hata-toleranslı örüntüleri daha hızlı buldu; çoğu durumda farklar büyük oldu. Ayrıca birden çok ağaç kuran önceki örüntü-büyüme yaklaşımlarından daha az bellek kullandı, ancak çok sıkıştırılmış bit-temelli bir yöntem hız pahasına bellek açısından en az yer kaplayan olarak kaldı. Yararlar, veriler yoğun, gürültülü veya potansiyel olarak sık öğe içeren durumlarda özellikle belirgindi.
İleriye Dönük Önemi
Uygulayıcılar için temel mesaj, kusurlu verilerde tekrarlanan, insan anlamlı örüntüleri ölümüne fazla tekrarlarla boğulmadan keşfetmenin artık daha pratik olduğudur. Hata toleransını, işlemleri sıkıştıran bir ağaçla birleştirip örüntüleri yalnızca kanıtlar desteklediğinde büyüterek önerilen yöntem, perakende sepetleri, sensör günlükleri, web tıklamaları veya tıbbi kayıtlar gibi kaynaklardan kararlı paketler çıkarmak için ölçeklenebilir bir yol sunar. Çok yüksek boyutluluk gibi aşırı durumlar hâlâ belleği zorlayabilse de, bu çalışma örüntü-büyümenin akış verileriyle başa çıkan, paralel donanımı kullanan veya gerçek dünya veri gürültüsüne göre tolerans düzeyini otomatik ayarlayan gelecekteki araçlar için sağlam bir temel olduğunu gösteriyor.
Atıf: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Anahtar kelimeler: sık öğe kümesi madenciliği, hata-toleranslı örüntüler, gürültülü işlem verileri, örüntü-büyüme algoritmaları, FP-ağacı