Clear Sky Science · fr
Une approche par croissance de motifs pour extraire des itemsets fréquents maximaux tolérants aux fautes
Trouver des motifs fiables dans des données désordonnées
Les relevés d'achats, les dossiers médicaux et les mesures de capteurs sont rarement parfaits. Des codes-barres sont manqués, des capteurs tombent en panne et des clics ne sont pas enregistrés. Pourtant, entreprises et chercheurs veulent savoir quelles entités apparaissent de façon fiable ensemble — par exemple des ensembles de produits, des regroupements de symptômes ou des signes avant-coureurs de fraude. Cet article présente une nouvelle méthode pour découvrir des combinaisons récurrentes fortes dans de telles données bruyantes, tout en gardant le nombre de motifs signalés réduit et exploitable.
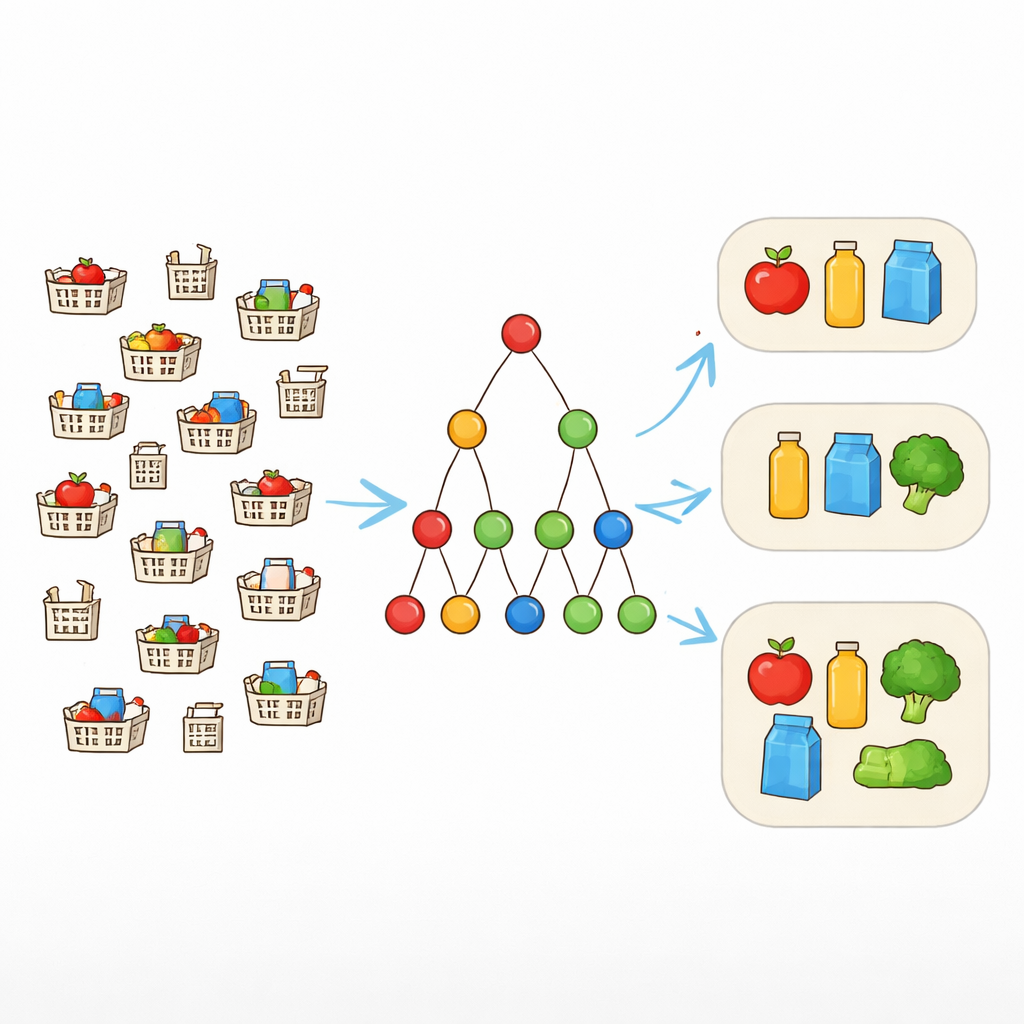
Des correspondances exactes à des motifs flexibles
Les outils traditionnels de fouille de motifs recherchent des combinaisons d'items qui apparaissent exactement de la même manière dans de nombreux enregistrements. Cela fonctionne bien seulement lorsque les données sont propres. Dans la réalité, cependant, des paniers d'achat qui « devraient » contenir le même lot peuvent différer d'un ou deux articles. Pour traiter cela, les chercheurs utilisent la notion de tolérance aux fautes. Plutôt que d'exiger que chaque item d'un motif soit présent à chaque occurrence, ils autorisent un nombre choisi d'items manquants. Si un motif est {ordinateur portable, souris, clavier, casque} et que la tolérance est de un, alors toute transaction contenant au moins trois de ces éléments compte encore comme soutenant le motif. Cela permet à l'algorithme de reconnaître des lots réalistes qui apparaissent sous des formes légèrement variées.
Pourquoi se concentrer sur les plus grands motifs est important
Autoriser des items manquants facilite la qualification des motifs comme fréquents, mais cela explose aussi l'espace de recherche. De nombreux motifs se chevauchant de tailles différentes deviennent possibles, surtout dans de grands jeux de données de vente au détail ou web. Les lister tous submergerait aussi bien les ordinateurs que les analystes. L'auteur se concentre donc sur les motifs maximaux — ceux qui ne peuvent pas être étendus en ajoutant un autre item sans devenir infrequents. Ces motifs maximaux tolérants aux fautes fournissent un résumé concis : toute combinaison fréquente plus petite est contenue dans au moins l'un d'eux et peut être reconstruite ultérieurement si nécessaire.
Cultiver les motifs dans un arbre compressé
Les méthodes antérieures tolérantes aux fautes prolongeaient en grande partie une approche classique qui génère et teste des motifs candidats niveau par niveau. Cette stratégie souffre de balayages répétés du jeu de données complet et d'un grand nombre de candidats. Le nouvel algorithme, appelé FT-MFI-PG, emprunte une autre voie inspirée par la croissance de motifs. Il construit d'abord une structure arborescente compacte qui fusionne les transactions partageant les mêmes items initiaux. Chaque chemin dans cet arbre représente de nombreux enregistrements similaires, réduisant fortement les données tout en préservant quels items ont tendance à apparaître ensemble. Par-dessus cela, l'algorithme attache de petits tableaux qui enregistrent la fréquence de cooccurrence des items, même lorsque certains manquent, de sorte que la tolérance aux fautes puisse être évaluée localement sans revisiter les données originales.
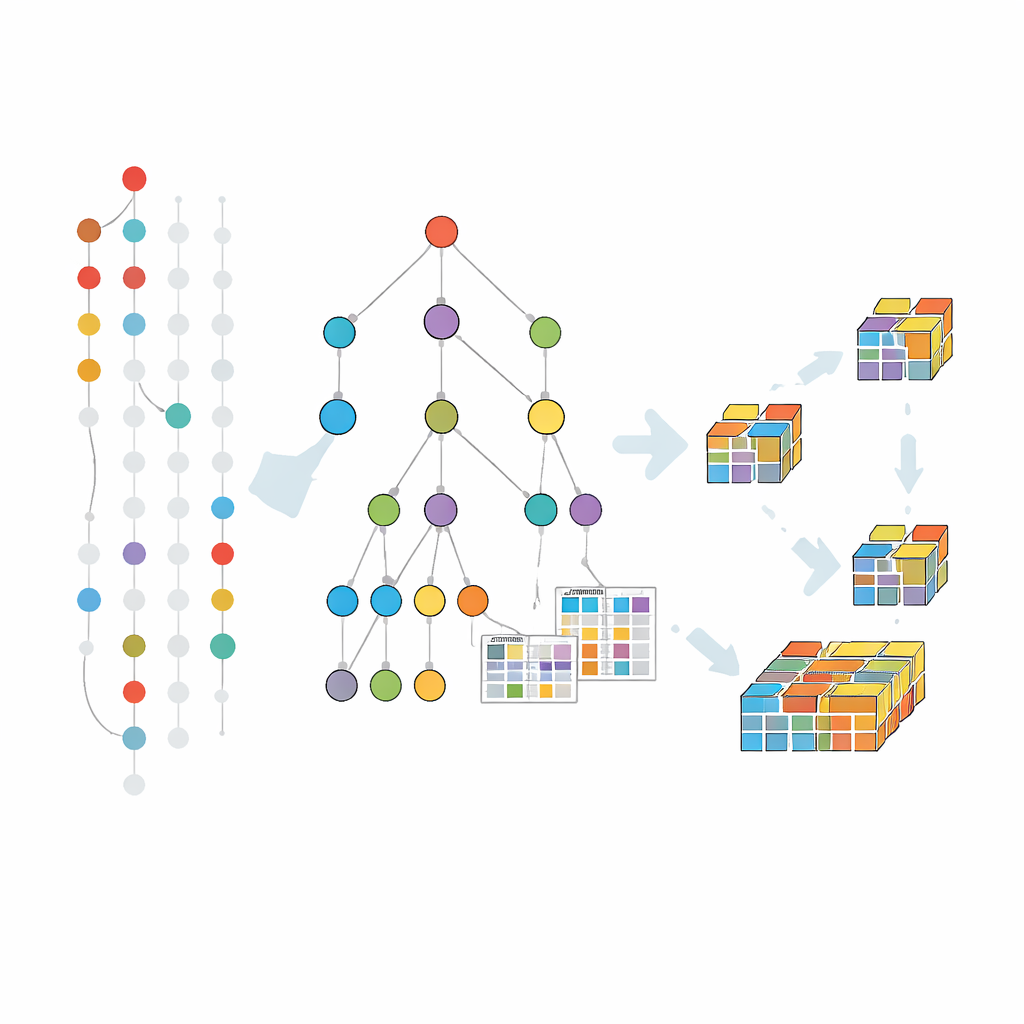
Approfondir le fonctionnement de la méthode
L'extraction progresse en explorant cet arbre des combinaisons plus petites vers les plus grandes, mais uniquement là où les données suggèrent que des extensions significatives existent. Pour chaque groupe d'items prometteur, l'algorithme collecte le sous-ensemble de transactions qui les soutiennent — en autorisant des éléments manquants selon la tolérance choisie — puis construit un arbre plus petit centré sur ce groupe. Ce processus diviser-pour-régner se répète, faisant croître les motifs étape par étape et élaguant les branches qui ne peuvent pas conduire à des combinaisons fréquentes et tolérantes aux fautes. Des astuces supplémentaires d'élagage aident à sauter des zones de recherche déjà couvertes par des motifs maximaux connus, économisant ainsi temps et mémoire.
Ce que montrent les expériences
L'auteur a testé la nouvelle méthode sur plusieurs jeux de données de référence standard issus du commerce de détail, de la navigation web et de données transactionnelles synthétiques. Sur une large gamme de niveaux de tolérance et de seuils de fréquence, l'algorithme par croissance de motifs a systématiquement trouvé tous les motifs maximaux tolérants aux fautes plus rapidement que les techniques concurrentes, souvent avec des marges importantes. Il a également utilisé moins de mémoire que des approches antérieures de croissance de motifs qui construisaient plusieurs arbres, bien qu'une méthode très compacte basée sur des bits soit restée la plus économe en mémoire au prix d'une perte de vitesse. Les bénéfices étaient particulièrement prononcés lorsque les données étaient denses, bruyantes ou contenaient de nombreux items potentiellement fréquents.
Pourquoi cela compte pour la suite
Pour les praticiens, le message clé est qu'il est désormais plus pratique de découvrir des motifs robustes et significatifs pour l'humain dans des données imparfaites sans se noyer dans des résultats redondants. En combinant la tolérance aux fautes avec un arbre qui compresse les transactions et fait croître les motifs uniquement là où les preuves les soutiennent, la méthode proposée offre une voie évolutive pour extraire des lots stables de paniers de vente, de journaux de capteurs, de clics web ou de dossiers médicaux. Bien que des cas extrêmes de très haute dimensionnalité puissent encore solliciter la mémoire, ce travail montre que la croissance de motifs est une base solide pour des outils futurs traitant des flux de données, exploitant du matériel parallèle ou adaptant automatiquement le niveau de tolérance au bruit présent dans les jeux de données réels.
Citation: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Mots-clés: extraction d'itemsets fréquents, motifs tolérants aux fautes, données transactionnelles bruyantes, algorithmes de croissance de motifs, FP-tree