Clear Sky Science · en
A pattern-growth approach for mining maximal fault-tolerant frequent itemsets
Finding Reliable Patterns in Messy Data
Shopping records, medical logs, and sensor readings are rarely perfect. Barcodes are missed, sensors fail, and clicks go unrecorded. Yet businesses and scientists still want to know which things reliably occur together—such as product bundles, symptom clusters, or warning signs of fraud. This paper presents a new way to uncover strong recurring combinations from such noisy data, while keeping the number of reported patterns small and manageable.
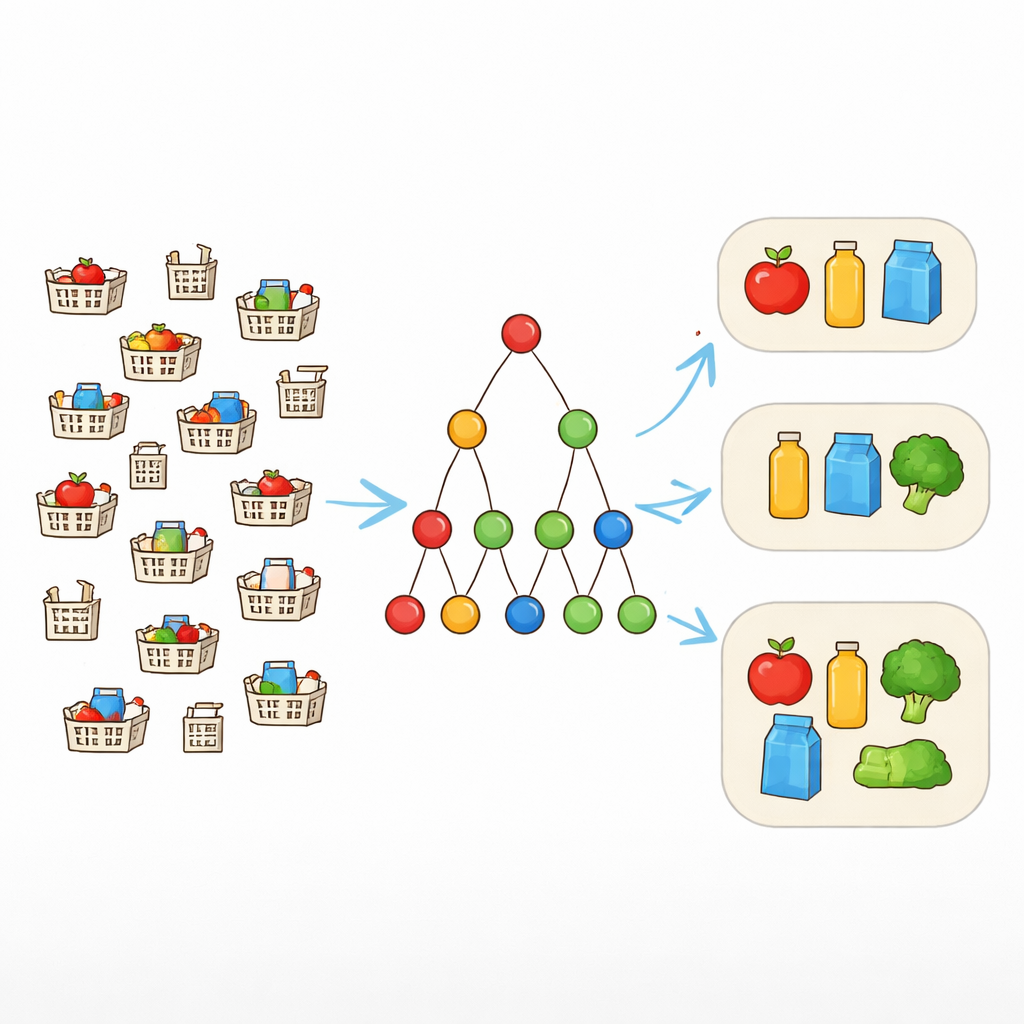
From Exact Matches to Flexible Patterns
Traditional pattern-mining tools look for item combinations that appear exactly the same across many records. That works well only when data are clean. In the real world, however, shopping carts that “should” contain the same bundle may differ by one or two items. To address this, researchers use a notion called fault tolerance. Instead of demanding that every item in a pattern be present every time, they allow up to a chosen number of missing items. If a pattern is {laptop, mouse, keyboard, headphones} and the tolerance is one, then any transaction containing at least three of these still counts as supporting the pattern. This lets the algorithm recognize realistic bundles that appear in slightly varied forms.
Why Focusing on the Biggest Patterns Matters
Allowing for missing items makes it easier for patterns to qualify as frequent, but it also explodes the search space. Many overlapping patterns of different sizes become possible, especially in large retail or web datasets. Listing them all would overwhelm both computers and analysts. Instead, the author concentrates on maximal patterns—those that cannot be extended by adding another item without becoming infrequent. These maximal fault-tolerant patterns provide a concise summary: every smaller frequent combination is contained in at least one of them and can be reconstructed later if needed.
Growing Patterns Inside a Compressed Tree
Earlier fault-tolerant methods largely extended a classic approach that generates and tests candidate patterns one level at a time. This strategy suffers from repeated scans of the full dataset and a huge number of candidates. The new algorithm, called FT-MFI-PG, takes a different route inspired by pattern growth. It first builds a compact tree structure that merges transactions sharing the same starting items. Each path through this tree represents many similar records, greatly shrinking the data while preserving which items tend to appear together. On top of this, the algorithm attaches small tables that record how often items co-occur, even when some are missing, so that fault tolerance can be evaluated locally without revisiting the original data.
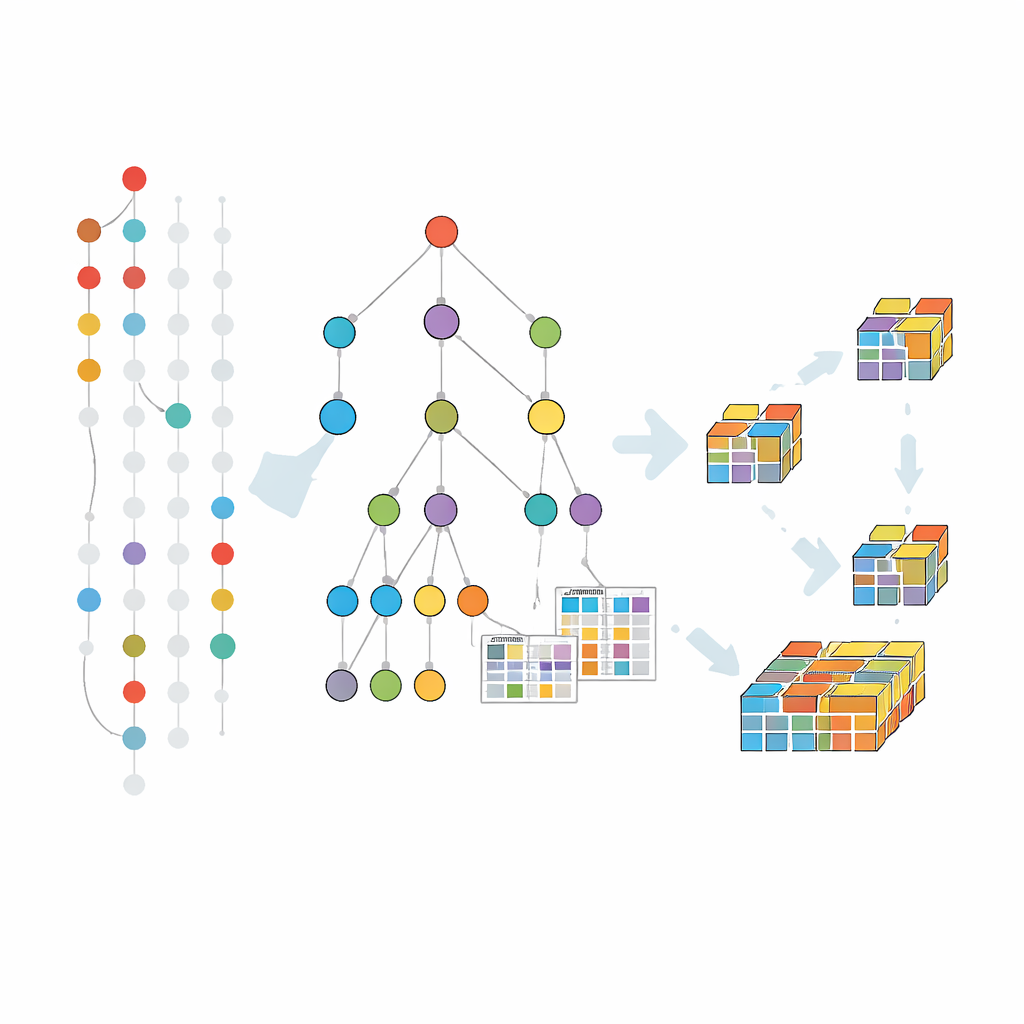
Zooming In on How the Method Works
Mining proceeds by exploring this tree from smaller to larger combinations, but only where the data suggest that meaningful extensions exist. For each promising group of items, the algorithm collects the subset of transactions that support them—allowing for missing elements according to the chosen tolerance—and then builds a smaller tree focused on that group. This divide-and-conquer process repeats, growing patterns step by step and pruning branches that cannot possibly lead to frequent, fault-tolerant combinations. Additional pruning tricks help skip areas of the search that are already covered by known maximal patterns, further saving time and memory.
What the Experiments Show
The author tested the new method on several standard benchmark datasets from retail, web browsing, and synthetic transaction data. Across a wide range of tolerance levels and frequency thresholds, the pattern-growth algorithm consistently found all maximal fault-tolerant patterns faster than competing techniques, often by large margins. It also used less memory than earlier pattern-growth approaches that built multiple trees, although a very compressed bit-based method remained the leanest in memory at the cost of speed. The benefits were especially pronounced when the data were dense, noisy, or contained many potentially frequent items.
Why This Matters Going Forward
For practitioners, the key message is that it is now more practical to discover robust, human-meaningful patterns in imperfect data without drowning in redundant results. By combining fault tolerance with a tree that compresses transactions and grows patterns only where the evidence supports them, the proposed method offers a scalable way to extract stable bundles from retail baskets, sensor logs, web clicks, or medical records. While extreme cases with very high dimensionality can still strain memory, this work shows that pattern growth is a strong foundation for future tools that handle streaming data, exploit parallel hardware, or adapt the tolerance level automatically to the noise present in real-world datasets.
Citation: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Keywords: frequent itemset mining, fault-tolerant patterns, noisy transaction data, pattern-growth algorithms, FP-tree