Clear Sky Science · nl
Een patroon-groeibenadering voor het opsporen van maximale fouttolerante frequente itemsets
Betrouwbare patronen vinden in rommelige data
Aankoopgegevens, medische logboeken en sensormetingen zijn zelden perfect. Barcodes worden gemist, sensoren falen en klikken worden niet vastgelegd. Toch willen bedrijven en wetenschappers steeds weten welke zaken betrouwbaar samen voorkomen — zoals productbundels, symptoomclusters of waarschuwingssignalen van fraude. Dit artikel presenteert een nieuwe manier om sterke terugkerende combinaties in zulke ruisachtige data te ontdekken, terwijl het aantal gerapporteerde patronen klein en beheersbaar blijft.
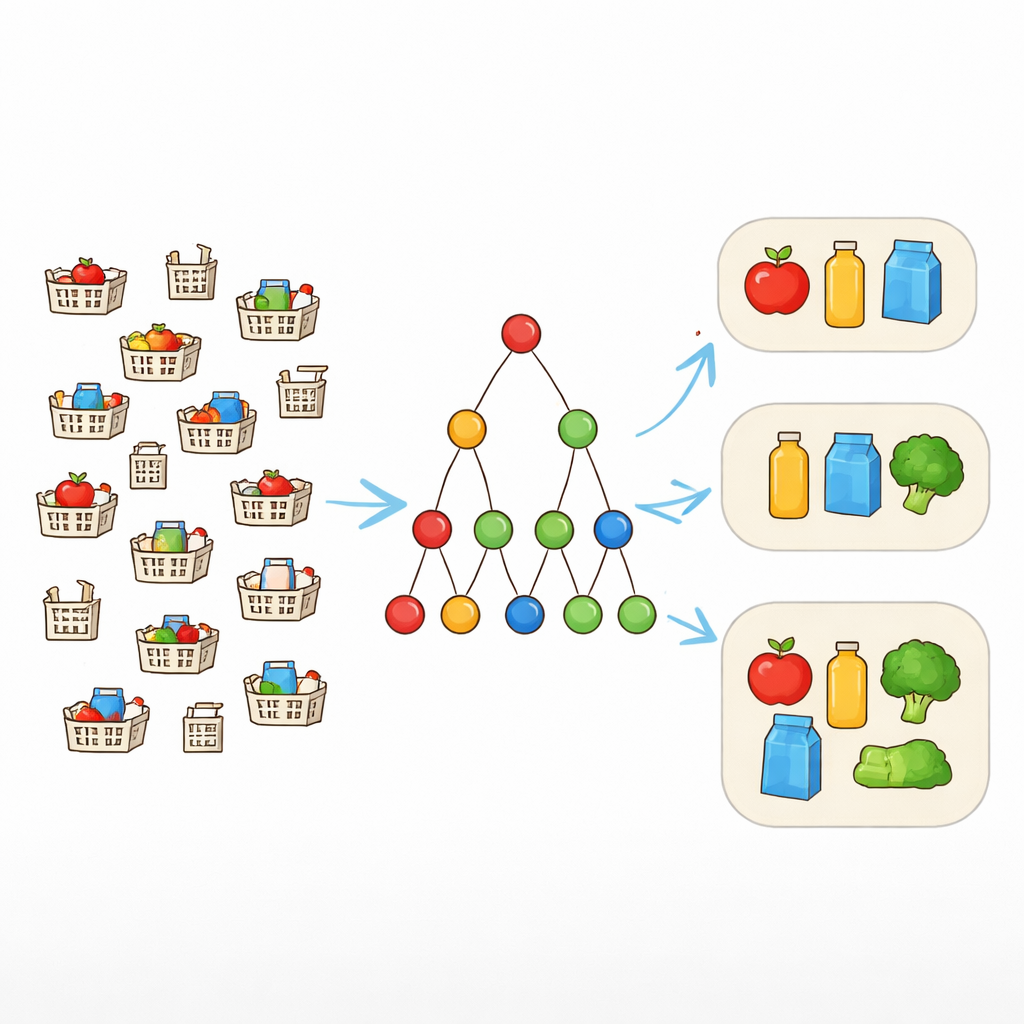
Van exacte overeenkomsten naar flexibele patronen
Traditionele patroon‑mining‑hulpmiddelen zoeken naar itemcombinaties die exact hetzelfde voorkomen in veel records. Dat werkt goed alleen wanneer data schoon zijn. In de praktijk kunnen winkelmandjes die “dezelfde” bundel zouden moeten bevatten, echter afwijken met één of twee items. Om dit aan te pakken gebruiken onderzoekers het begrip fouttolerantie. In plaats van te eisen dat elk item in een patroon elke keer aanwezig is, laten ze een gekozen aantal missende items toe. Als een patroon {laptop, muis, toetsenbord, koptelefoon} is en de tolerantie is één, dan telt elke transactie die ten minste drie van deze items bevat nog steeds als ondersteuning voor het patroon. Dit stelt het algoritme in staat realistische bundels te herkennen die in licht gevarieerde vormen voorkomen.
Waarom focussen op de grootste patronen belangrijk is
Het toestaan van missende items maakt het makkelijker voor patronen om frequent te zijn, maar het blaast ook de zoekruimte op. Veel overlappende patronen van verschillende groottes worden mogelijk, vooral in grote retail‑ of webdatasets. Ze allemaal opsommen zou zowel computers als analisten overweldigen. In plaats daarvan concentreert de auteur zich op maximale patronen — die niet kunnen worden uitgebreid door een ander item toe te voegen zonder onfrequent te worden. Deze maximale fouttolerante patronen bieden een beknopt overzicht: elke kleinere frequente combinatie is in elk geval in ten minste één daarvan opgenomen en kan later indien nodig worden gereconstrueerd.
Patronen laten groeien binnen een gecomprimeerde boom
Eerdere fouttolerante methoden bouwden grotendeels voort op een klassieke aanpak die kandidaatpatronen niveau voor niveau genereert en test. Deze strategie lijdt onder herhaalde scans van de volledige dataset en een enorm aantal kandidaten. Het nieuwe algoritme, FT-MFI-PG, kiest een andere route geïnspireerd door patroongroei. Het bouwt eerst een compacte boomstructuur die transacties samenvoegt die dezelfde beginitems delen. Elk pad door deze boom vertegenwoordigt veel vergelijkbare records, waardoor de data sterk krimpen terwijl wordt vastgehouden aan welke items de neiging hebben samen voor te komen. Daarboven hangt het algoritme kleine tabellen die bijhouden hoe vaak items samenvallen, zelfs wanneer sommige ontbreken, zodat fouttolerantie lokaal kan worden geëvalueerd zonder de originele data opnieuw te hoeven bekijken.
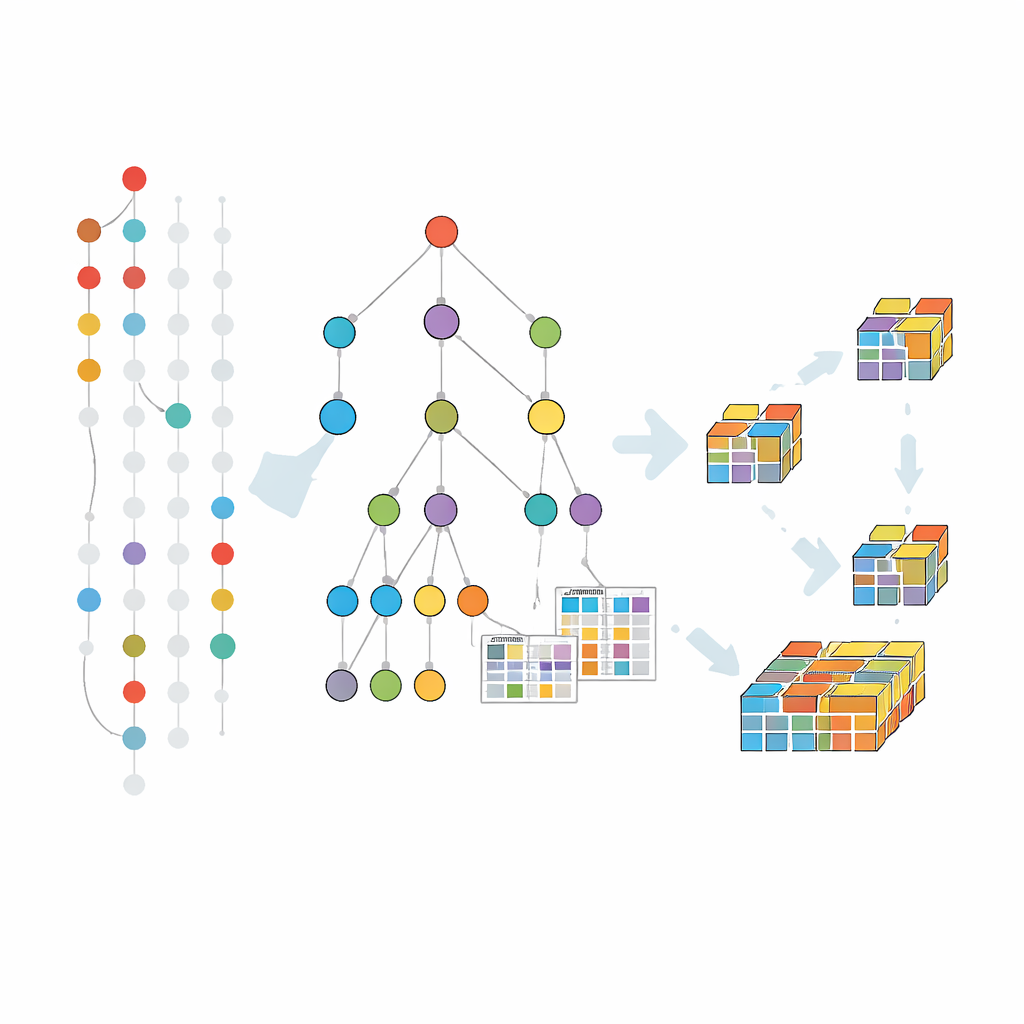
Inzoomen op hoe de methode werkt
Mining verloopt door deze boom te verkennen van kleinere naar grotere combinaties, maar alleen waar de data suggereren dat zinvolle uitbreidingen bestaan. Voor elke veelbelovende groep items verzamelt het algoritme de subset van transacties die ze ondersteunen — rekening houdend met missende elementen volgens de gekozen tolerantie — en bouwt dan een kleinere boom die op die groep is gefocust. Dit divide‑and‑conquer‑proces herhaalt zich, waarbij patronen stap voor stap groeien en takken worden afgesnoeid die onmogelijk tot frequente, fouttolerante combinaties kunnen leiden. Extra snoeitrucs helpen delen van de zoekruimte over te slaan die al worden bestreken door bekende maximale patronen, wat tijd en geheugen verder bespaart.
Wat de experimenten laten zien
De auteur testte de nieuwe methode op meerdere standaard benchmarkdatasets uit retail, webbrowsing en synthetische transactiedata. Over een breed scala aan tolerantieniveaus en frequentiedrempels vond het patroon‑groeialgoritme consequent alle maximale fouttolerante patronen sneller dan concurrerende technieken, vaak met aanzienlijke marges. Het gebruikte ook minder geheugen dan eerdere patroon‑groeiaanpakken die meerdere bomen bouwden, hoewel een zeer gecomprimeerde bitgebaseerde methode het zuinigst in geheugen bleef ten koste van snelheid. De voordelen waren vooral uitgesproken wanneer de data dicht, ruisig of rijk aan potentiële frequente items waren.
Waarom dit van belang is voor de toekomst
Voor praktijkmensen is de kernboodschap dat het nu praktischer is om robuuste, voor mensen betekenisvolle patronen in imperfecte data te ontdekken zonder te verdrinken in redundante resultaten. Door fouttolerantie te combineren met een boom die transacties comprimeert en patronen alleen te laten groeien waar het bewijs dat ondersteunt, biedt de voorgestelde methode een schaalbare manier om stabiele bundels te extraheren uit winkelmandjes, sensorlogs, webkliks of medische dossiers. Hoewel extreme gevallen met zeer hoge dimensionaliteit het geheugen nog altijd kunnen belasten, laat dit werk zien dat patroongroei een sterke basis is voor toekomstige tools die streamingdata verwerken, parallelle hardware benutten of het tolerantie‑niveau automatisch aanpassen aan de ruis in echte datasets.
Bronvermelding: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Trefwoorden: frequent itemset mining, fouttolerante patronen, ruisachtige transactiedata, patroon-groeialgoritmen, FP-tree