Clear Sky Science · de
Ein musterwachstumsbasiertes Verfahren zum Auffinden maximal fehlertoleranter häufiger Itemsets
Zuverlässige Muster in unordentlichen Daten finden
Einkaufsaufzeichnungen, medizinische Protokolle und Sensordaten sind selten perfekt. Barcodes werden übersehen, Sensoren versagen und Klicks werden nicht protokolliert. Dennoch möchten Unternehmen und Forscher wissen, welche Elemente verlässlich zusammen auftreten – etwa Produktpakete, Symptommuster oder Warnsignale für Betrug. Dieses Papier stellt eine neue Methode vor, um aus solchen verrauschten Daten robuste wiederkehrende Kombinationen zu entdecken und gleichzeitig die Anzahl gemeldeter Muster klein und überschaubar zu halten.
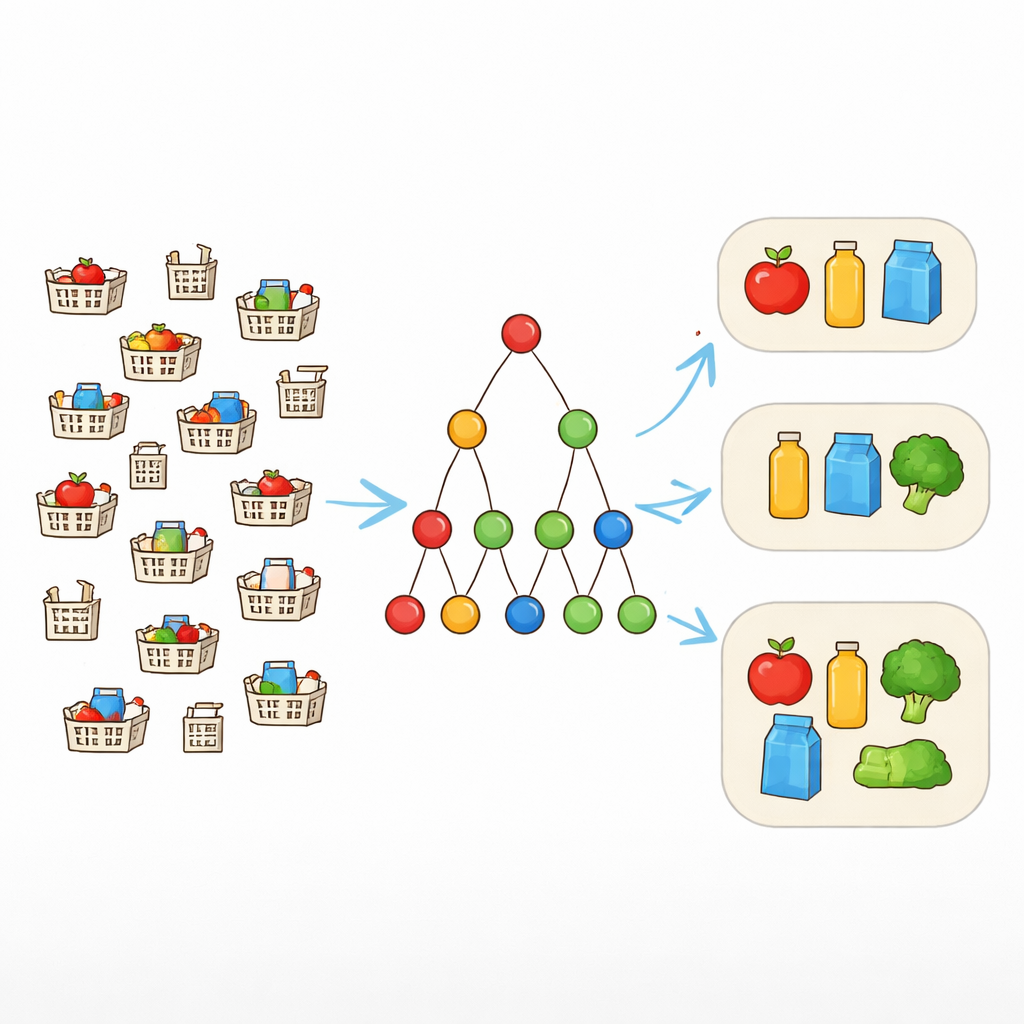
Von exakten Übereinstimmungen zu flexiblen Mustern
Traditionelle Mustererkennungswerkzeuge suchen nach Itemkombinationen, die in vielen Datensätzen exakt gleich auftreten. Das funktioniert gut, wenn die Daten sauber sind. In der Praxis können Einkaufskörbe, die dasselbe Paket enthalten sollten, jedoch um ein oder zwei Artikel variieren. Um dem gerecht zu werden, verwenden Forschende das Konzept der Fehlertoleranz. Anstatt zu verlangen, dass jedes Element eines Musters jedes Mal vorhanden ist, erlauben sie bis zu eine festgelegte Anzahl fehlender Items. Ist ein Muster {Laptop, Maus, Tastatur, Kopfhörer} und die Toleranz eins, zählt jede Transaktion, die mindestens drei dieser Elemente enthält, als Unterstützung für das Muster. So erkennt der Algorithmus realistische Pakete, die in leicht veränderter Form auftreten.
Warum der Fokus auf den größten Mustern wichtig ist
Das Zulassen fehlender Items erleichtert es, dass Muster als häufig gelten, vergrößert aber auch drastisch den Suchraum. Viele sich überschneidende Muster verschiedener Größe werden möglich, insbesondere in großen Einzelhandels- oder Web-Datensätzen. Alle aufzulisten würde sowohl Rechner als auch Analysten überfordern. Stattdessen konzentriert sich der Autor auf maximale Muster – solche, die sich nicht durch Hinzufügen eines weiteren Items erweitern lassen, ohne unhäufig zu werden. Diese maximalen fehlertoleranten Muster liefern eine knappe Zusammenfassung: Jede kleinere häufige Kombination ist in mindestens einem von ihnen enthalten und kann bei Bedarf später rekonstruiert werden.
Musterwachstum in einem komprimierten Baum
Frühere fehlertolerante Methoden bauten meist auf einem klassischen Ansatz auf, der Kandidaten schrittweise generiert und testet. Diese Strategie erfordert wiederholte Scans der gesamten Datenmenge und erzeugt eine enorme Anzahl von Kandidaten. Der neue Algorithmus, FT-MFI-PG genannt, schlägt einen anderen Weg im Sinne des Musterwachstums ein. Zuerst wird eine kompakte Baumstruktur aufgebaut, die Transaktionen zusammenführt, die dieselben Anfangselemente teilen. Jeder Pfad durch diesen Baum repräsentiert viele ähnliche Datensätze, wodurch die Daten stark geschrumpft werden, während erhalten bleibt, welche Items tendenziell zusammen auftreten. Zusätzlich hängt der Algorithmus kleine Tabellen an, die speichern, wie oft Items gemeinsam vorkommen – selbst wenn einige fehlen –, sodass die Fehlertoleranz lokal bewertet werden kann, ohne die Originaldaten erneut zu durchlaufen.
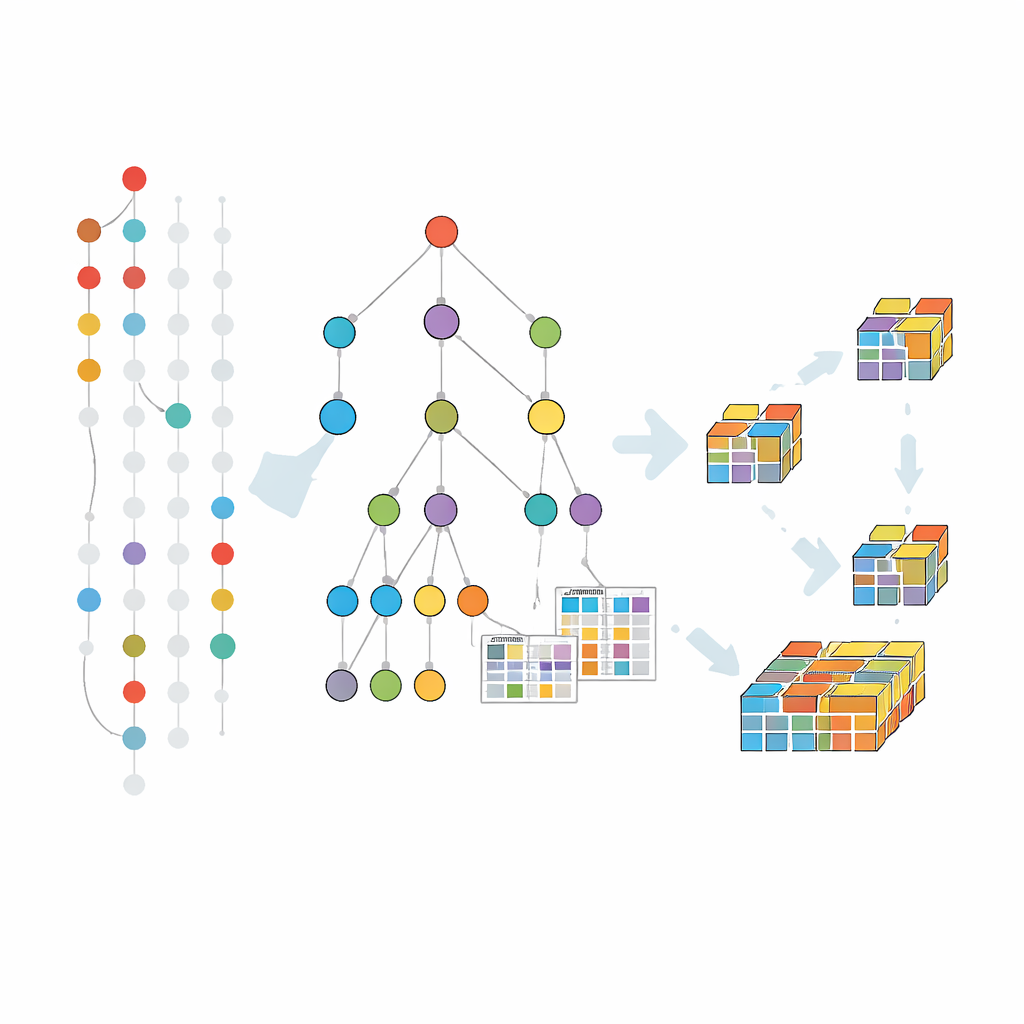
Ein genauerer Blick auf die Funktionsweise
Das Mining erfolgt durch Exploration dieses Baums von kleineren zu größeren Kombinationen, jedoch nur dort, wo die Daten sinnvolle Erweiterungen nahelegen. Für jede vielversprechende Itemgruppe sammelt der Algorithmus die Teilmenge von Transaktionen, die sie unterstützen – wobei fehlende Elemente gemäß der gewählten Toleranz zugelassen werden – und baut dann einen kleineren, auf diese Gruppe fokussierten Baum. Dieser Divide-and-Conquer-Prozess wiederholt sich, wächst Muster schrittweise und beschneidet Zweige, die unmöglich zu häufigen, fehlertoleranten Kombinationen führen können. Zusätzliche Pruning-Tricks helfen, Bereiche der Suche zu überspringen, die bereits durch bekannte maximale Muster abgedeckt sind, und sparen so weitere Zeit und Speicher.
Was die Experimente zeigen
Der Autor testete die neue Methode an mehreren standardisierten Benchmark-Datensätzen aus Einzelhandel, Web-Browsing und synthetischen Transaktionsdaten. Über ein breites Spektrum von Toleranzstufen und Häufigkeitsschwellen fand der Musterwachstumsalgorithmus konsistent alle maximalen fehlertoleranten Muster schneller als konkurrierende Techniken, oft mit deutlichen Vorsprüngen. Er benötigte auch weniger Speicher als frühere Musterwachstumsansätze, die mehrere Bäume aufbauten, obwohl eine sehr komprimierte bitbasierte Methode in Sachen Speicherverbrauch noch sparsamer war – auf Kosten der Geschwindigkeit. Die Vorteile zeigten sich besonders deutlich, wenn die Daten dicht, verrauscht oder mit vielen potenziell häufigen Items gespickt waren.
Warum das zukünftig wichtig ist
Für Praktiker lautet die zentrale Botschaft, dass es nun praktikabler ist, robuste, für Menschen sinnvolle Muster in unvollkommenen Daten zu entdecken, ohne in redundanten Ergebnissen zu versinken. Indem Fehlertoleranz mit einem Baum kombiniert wird, der Transaktionen komprimiert und Muster nur dort wachsen lässt, wo die Evidenz dies stützt, bietet die vorgeschlagene Methode einen skalierbaren Weg, stabile Pakete aus Einkaufsbaskets, Sensordaten, Web-Klicks oder medizinischen Aufzeichnungen zu extrahieren. Während Extreme mit sehr hoher Dimensionalität weiterhin den Speicher belasten können, zeigt diese Arbeit, dass Musterwachstum eine robuste Grundlage für künftige Werkzeuge bildet, die mit Streaming-Daten umgehen, parallele Hardware nutzen oder das Toleranzniveau automatisch an das Rauschen realer Datensätze anpassen.
Zitation: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Schlüsselwörter: häufiges Itemset-Mining, fehlertolerante Muster, rauschende Transaktionsdaten, Musterwachstumsalgorithmen, FP-Baum