Clear Sky Science · pl
Podejście wzrostu wzorców do wydobywania maksymalnych odpornych na błędy częstych zbiorów przedmiotów
Odnajdywanie wiarygodnych wzorców w nieporządnym zbiorze danych
Zapisy zakupów, logi medyczne i odczyty czujników rzadko są idealne. Kody kreskowe bywają pomijane, czujniki zawodzą, a kliknięcia nie zawsze są rejestrowane. Mimo to firmy i naukowcy chcą wiedzieć, które elementy występują razem w sposób powtarzalny — na przykład zestawy produktów, skupiska objawów czy sygnały wskazujące na oszustwo. W artykule przedstawiono nowe podejście do odnajdywania silnych, powtarzających się kombinacji w takich zaszumionych danych, przy jednoczesnym utrzymaniu liczby zgłaszanych wzorców na niewielkim i przystępnym poziomie.
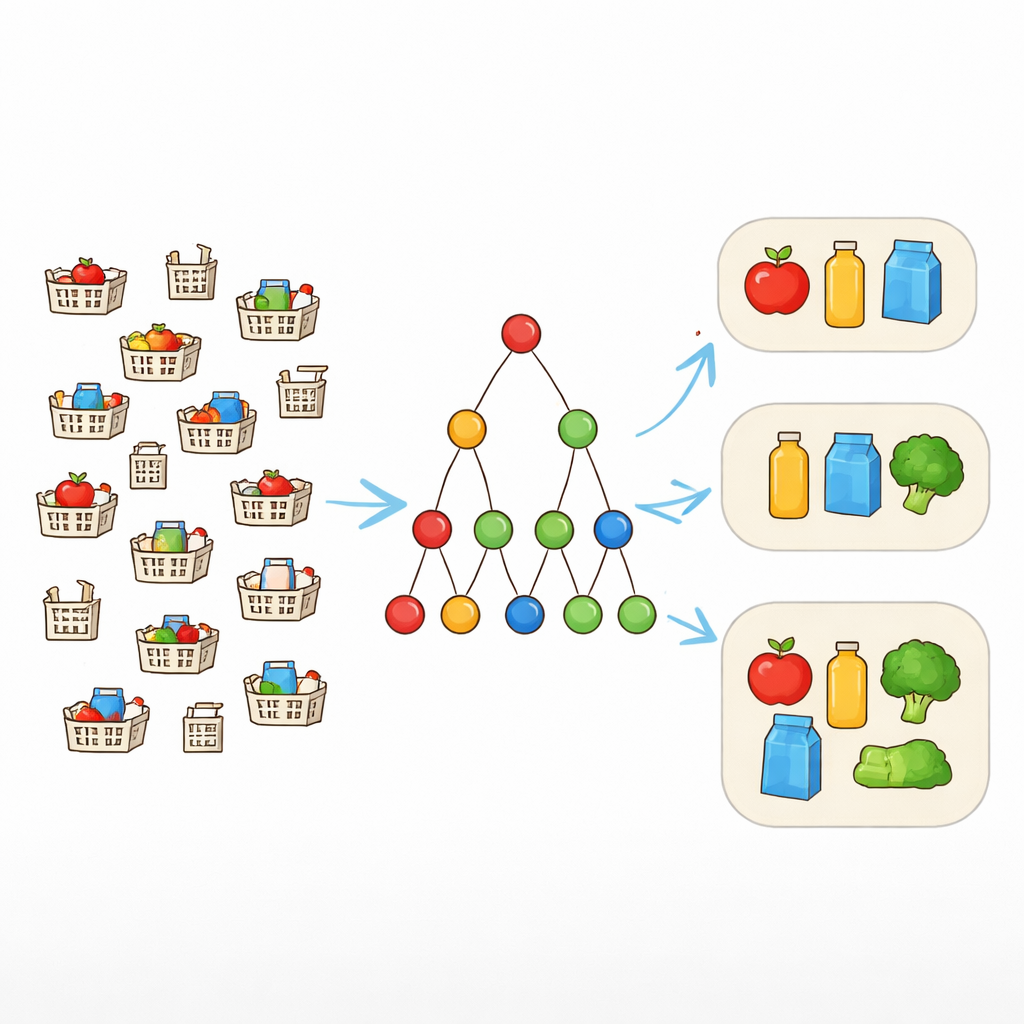
Od dokładnych dopasowań do elastycznych wzorców
Tradycyjne narzędzia do wydobywania wzorców szukają kombinacji przedmiotów, które pojawiają się dokładnie w tej samej postaci w wielu rekordach. To działa dobrze tylko wtedy, gdy dane są czyste. W rzeczywistości jednak koszyki zakupowe, które „powinny” zawierać ten sam zestaw, mogą różnić się jednym lub dwoma elementami. Aby temu sprostać, badacze stosują pojęcie odporności na błędy. Zamiast wymagać, by każdy element wzorca był obecny za każdym razem, pozwalają na pewną liczbę brakujących elementów. Jeśli wzorzec to {laptop, mysz, klawiatura, słuchawki} i tolerancja wynosi jeden, to każda transakcja zawierająca przynajmniej trzy z tych elementów nadal wspiera wzorzec. Pozwala to algorytmowi rozpoznać realistyczne zestawy pojawiające się w nieco zmienionych formach.
Dlaczego warto skupić się na największych wzorcach
Umożliwienie brakujących elementów sprawia, że wzorce łatwiej spełniają kryteria częstotliwości, ale jednocześnie eksploduje przestrzeń poszukiwań. Powstaje wiele nakładających się wzorców o różnych rozmiarach, szczególnie w dużych zbiorach detalicznych czy internetowych. Wypisanie ich wszystkich przytłoczyłoby zarówno komputery, jak i analityków. Zamiast tego autor koncentruje się na wzorcach maksymalnych — takich, których nie da się rozszerzyć o kolejny element bez utraty częstotliwości. Te maksymalne, odporne na błędy wzorce dostarczają zwięzłego podsumowania: każda mniejsza częsta kombinacja jest zawarta przynajmniej w jednym z nich i może być odtworzona później, jeśli zajdzie taka potrzeba.
Wzrost wzorców w skompresowanym drzewie
Wcześniejsze metody odporne na błędy w dużej mierze rozwijały klasyczne podejście generowania i testowania kandydatów poziom po poziomie. Ta strategia cierpi z powodu wielokrotnych skanów pełnego zbioru danych i ogromnej liczby kandydatów. Nowy algorytm, nazwany FT-MFI-PG, idzie inną drogą inspirowaną wzrostem wzorców. Najpierw buduje kompaktową strukturę drzewa, która scala transakcje zaczynające się od tych samych elementów. Każda ścieżka w tym drzewie reprezentuje wiele podobnych rekordów, znacznie zmniejszając ilość danych przy zachowaniu informacji o tym, które elementy mają tendencję do współwystępowania. Do tego algorytm dołącza małe tabele rejestrujące, jak często elementy współwystępują, nawet gdy niektóre z nich brakują, dzięki czemu odporność na błędy można ocenić lokalnie bez ponownego przetwarzania oryginalnych danych.
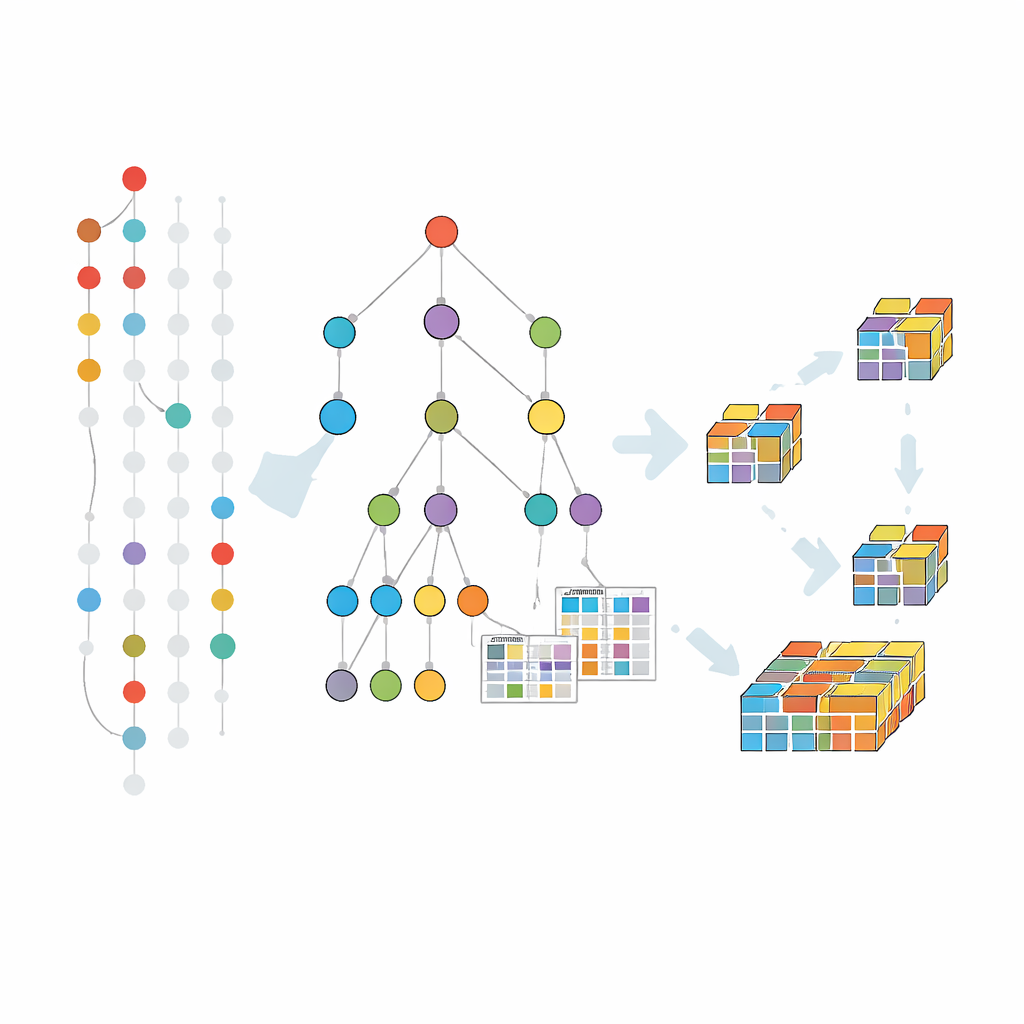
Przyjrzenie się działaniu metody
Wydobywanie przebiega przez eksplorację tego drzewa od mniejszych do większych kombinacji, ale tylko tam, gdzie dane sugerują, że istnieją znaczące rozszerzenia. Dla każdej obiecującej grupy elementów algorytm zbiera podzbiór transakcji, które je wspierają — z uwzględnieniem brakujących elementów zgodnie z wybraną tolerancją — a następnie buduje mniejsze drzewo skoncentrowane na tej grupie. Proces dzielenia i podboju powtarza się, rozwijając wzorce krok po kroku i przycinając gałęzie, które nie mogą doprowadzić do częstych, odpornych na błędy kombinacji. Dodatkowe techniki przycinania pomagają pominąć obszary poszukiwań już pokryte przez znane wzorce maksymalne, oszczędzając dalszy czas i pamięć.
Co pokazują eksperymenty
Autor przetestował nową metodę na kilku standardowych zbiorach benchmarkowych pochodzących ze sprzedaży detalicznej, przeglądania stron i syntetycznych danych transakcyjnych. W szerokim zakresie poziomów tolerancji i progów częstotliwości algorytm wzrostu wzorców konsekwentnie znajdował wszystkie maksymalne, odporne na błędy wzorce szybciej niż konkurencyjne techniki, często z dużą przewagą. Wykorzystywał też mniej pamięci niż wcześniejsze podejścia wzrostowe, które budowały wiele drzew, chociaż bardzo skompresowana metoda oparta na bitach pozostała najoszczędniejsza pamięciowo kosztem szybkości. Korzyści były szczególnie widoczne, gdy dane były gęste, zaszumione lub zawierały wiele potencjalnie częstych elementów.
Dlaczego ma to znaczenie w przyszłości
Dla praktyków kluczowe przesłanie jest takie, że odkrywanie odpornych, czytelnych dla człowieka wzorców w niedoskonałych danych stało się bardziej praktyczne bez zalewania wynikami. Łącząc odporność na błędy z drzewem kompresującym transakcje i rozwijającym wzorce tylko tam, gdzie istnieją na to dowody, proponowana metoda oferuje skalowalny sposób wydobywania stabilnych zestawów z koszyków zakupowych, logów czujników, kliknięć internetowych czy zapisów medycznych. Chociaż skrajne przypadki o bardzo dużej wymiarowości nadal mogą obciążać pamięć, praca ta pokazuje, że wzrost wzorców jest solidną podstawą dla przyszłych narzędzi obsługujących dane strumieniowe, wykorzystujących sprzęt równoległy lub automatycznie dostosowujących poziom tolerancji do zaszumienia obecnego w rzeczywistych zbiorach danych.
Cytowanie: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Słowa kluczowe: wydobywanie częstych zbiorów przedmiotów, wzorce odporne na błędy, zanieczyszczone dane transakcyjne, algorytmy wzrostu wzorców, drzewo FP