Clear Sky Science · sv
En mönstertillväxtmetod för att utvinna maximala fel-toleranta frekventa artikelmängder
Att hitta tillförlitliga mönster i stökiga data
Shoppingregister, medicinska loggar och sensormätningar är sällan perfekta. Streckkoder missas, sensorer fallerar och klick registreras inte. Ändå vill företag och forskare veta vilka saker som regelbundet förekommer tillsammans — till exempel produktbundlar, symtomkluster eller varningstecken för bedrägeri. Denna artikel presenterar ett nytt sätt att upptäcka starka återkommande kombinationer i sådana brusiga data, samtidigt som antalet rapporterade mönster hålls litet och hanterbart.
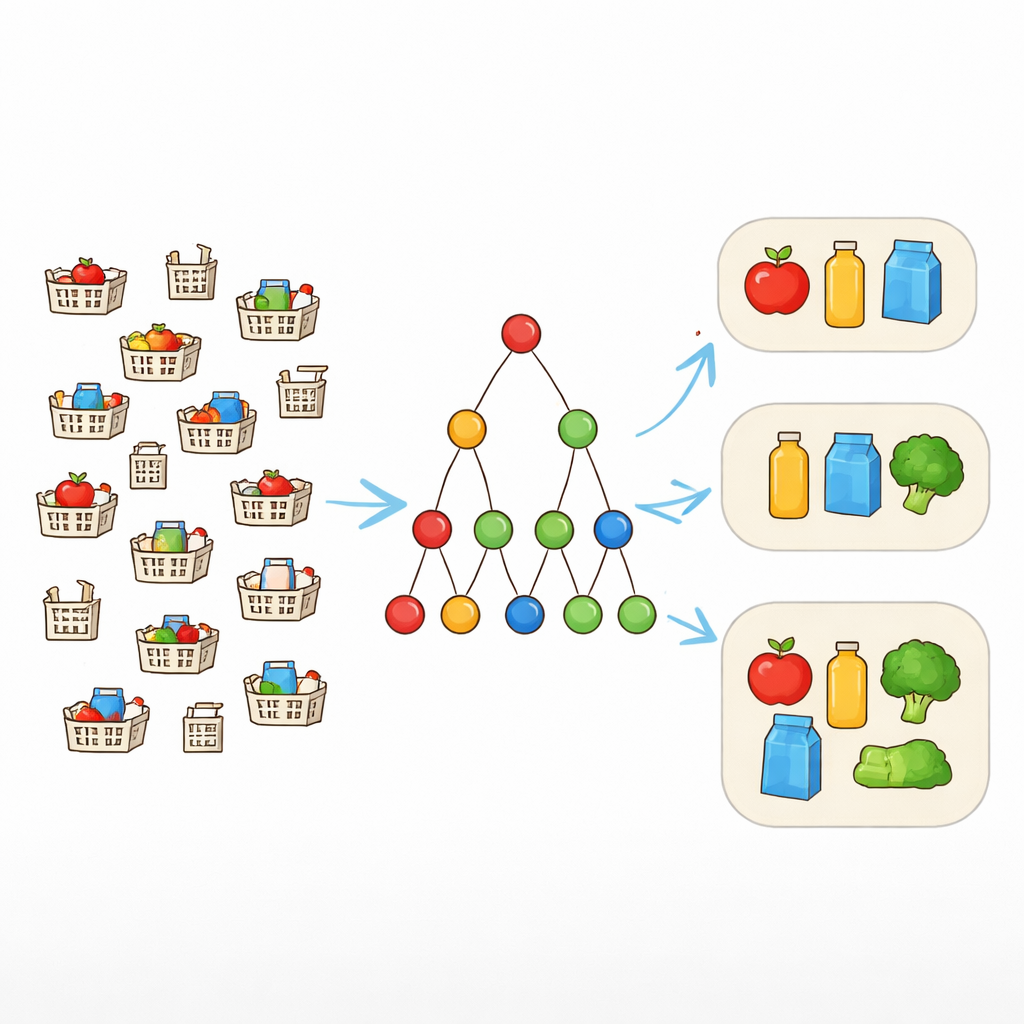
Från exakta träffar till flexibla mönster
Traditionella mönsterutvinningsverktyg söker efter artikelkombinationer som förekommer exakt likadant i många poster. Det fungerar bra endast när data är rena. I verkligheten kan dock kundkorgar som "borde" innehålla samma paket skilja sig med en eller två artiklar. För att hantera detta används en idé som kallas fel tolerans. I stället för att kräva att varje artikel i ett mönster måste vara närvarande varje gång tillåter man upp till ett valt antal saknade artiklar. Om ett mönster är {laptop, mus, tangentbord, hörlurar} och toleransen är ett, räknas en transaktion som stödjande mönstret om den innehåller minst tre av dessa. Detta gör att algoritmen kan känna igen realistiska bundlar som förekommer i något varierande former.
Varför fokus på de största mönstren spelar roll
Att tillåta saknade artiklar gör det lättare för mönster att kvalificera sig som frekventa, men det explosionsartat ökar också sökutrymmet. Många överlappande mönster i olika storlekar blir möjliga, särskilt i stora detaljhandels- eller webbdatamängder. Att lista dem alla skulle överväldiga både datorer och analytiker. I stället koncentrerar författaren sig på maximala mönster — de som inte kan utvidgas genom att lägga till en annan artikel utan att bli ofrekventa. Dessa maximala fel-toleranta mönster ger en koncis sammanfattning: varje mindre frekvent kombination finns innesluten i minst ett av dem och kan rekonstrueras senare vid behov.
Tillväxt av mönster i ett komprimerat träd
Tidigare fel-toleranta metoder byggde i stor utsträckning vidare på en klassisk strategi som genererar och testar kandidatmönster nivå för nivå. Den metoden lider av upprepade genomgångar av hela datasatsen och ett enormt antal kandidater. Den nya algoritmen, kallad FT-MFI-PG, väljer en annan väg inspirerad av mönstertillväxt. Den bygger först en kompakt trädstruktur som slår ihop transaktioner som delar samma startartiklar. Varje väg genom detta träd representerar många liknande poster, vilket kraftigt krymper datamängden samtidigt som det bevarar vilka artiklar som tenderar att förekomma tillsammans. Ovanpå detta fäster algoritmen små tabeller som registrerar hur ofta artiklar samexisterar, även när några saknas, så att fel tolerans kan utvärderas lokalt utan att återbesöka originaldata.
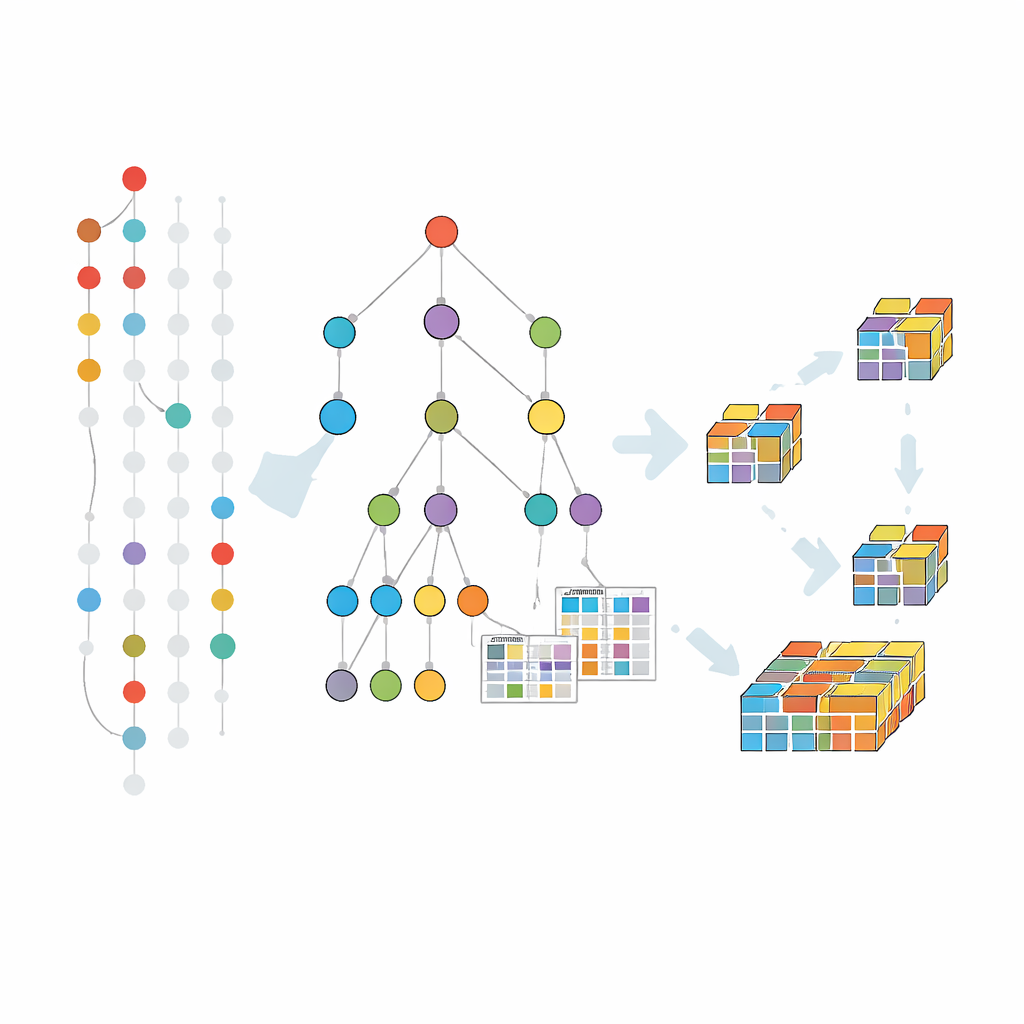
Närmare in på hur metoden fungerar
Utvinningen sker genom att utforska detta träd från mindre till större kombinationer, men endast där data antyder att meningsfulla utvidgningar finns. För varje lovande grupp av artiklar samlar algoritmen delmängden av transaktioner som stödjer dem — med tillåtelse för saknade element enligt vald tolerans — och bygger sedan ett mindre träd fokuserat på den gruppen. Denna dela-och-härska-process upprepas, växer mönster steg för steg och beskär grenar som inte kan leda till frekventa, fel-toleranta kombinationer. Ytterligare beskärningstekniker hjälper till att hoppa över områden av sökningen som redan täcks av kända maximala mönster, vilket sparar både tid och minne.
Vad experimenten visar
Författaren testade den nya metoden på flera standardbenchmark-datasets från detaljhandel, webbbläddring och syntetiska transaktionsdata. Över ett brett spektrum av toleransnivåer och frekvenströsklar fann mönstertillväxtalgoritmen konsekvent alla maximala fel-toleranta mönster snabbare än konkurrerande tekniker, ofta med stora marginaler. Den använde också mindre minne än tidigare mönstertillväxtmetoder som byggde flera träd, även om en mycket kompakt bitbaserad metod förblev den mest minneseffektiva på bekostnad av hastighet. Vinsterna var särskilt tydliga när data var täta, brusiga eller innehöll många potentiellt frekventa artiklar.
Varför detta är viktigt framöver
För praktiker är huvudbudskapet att det nu är mer praktiskt att upptäcka robusta, människobetonade mönster i ofullständiga data utan att drunkna i redundanta resultat. Genom att kombinera fel tolerans med ett träd som komprimerar transaktioner och bara växer mönster där bevisen stöder det, erbjuder den föreslagna metoden ett skalbart sätt att extrahera stabila bundlar från kundkorgar, sensorloggar, webbklick eller medicinska journaler. Även om extrema fall med mycket hög dimensionalitet fortfarande kan belasta minnet visar detta arbete att mönstertillväxt är en stark grund för framtida verktyg som hanterar strömmande data, utnyttjar parallell hårdvara eller anpassar toleransnivån automatiskt till det brus som finns i verkliga dataset.
Citering: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Nyckelord: frekvent artikelmängdsutvinning, fel-toleranta mönster, brusiga transaktionsdata, mönstertillväxtalgoritmer, FP-träd