Clear Sky Science · es
Un enfoque de crecimiento de patrones para extraer conjuntos de ítems frecuentes tolerantes a fallos
Encontrar patrones fiables en datos desordenados
Los registros de compras, las anotaciones médicas y las lecturas de sensores rara vez son perfectos. Se pasan códigos de barras, fallan sensores y no se registran clics. Aun así, empresas y científicos quieren saber qué elementos aparecen juntos con regularidad —por ejemplo, paquetes de productos, conjuntos de síntomas o señales de fraude. Este artículo presenta una forma nueva de descubrir combinaciones recurrentes sólidas en datos ruidosos, manteniendo a la vez el número de patrones reportados pequeño y manejable.
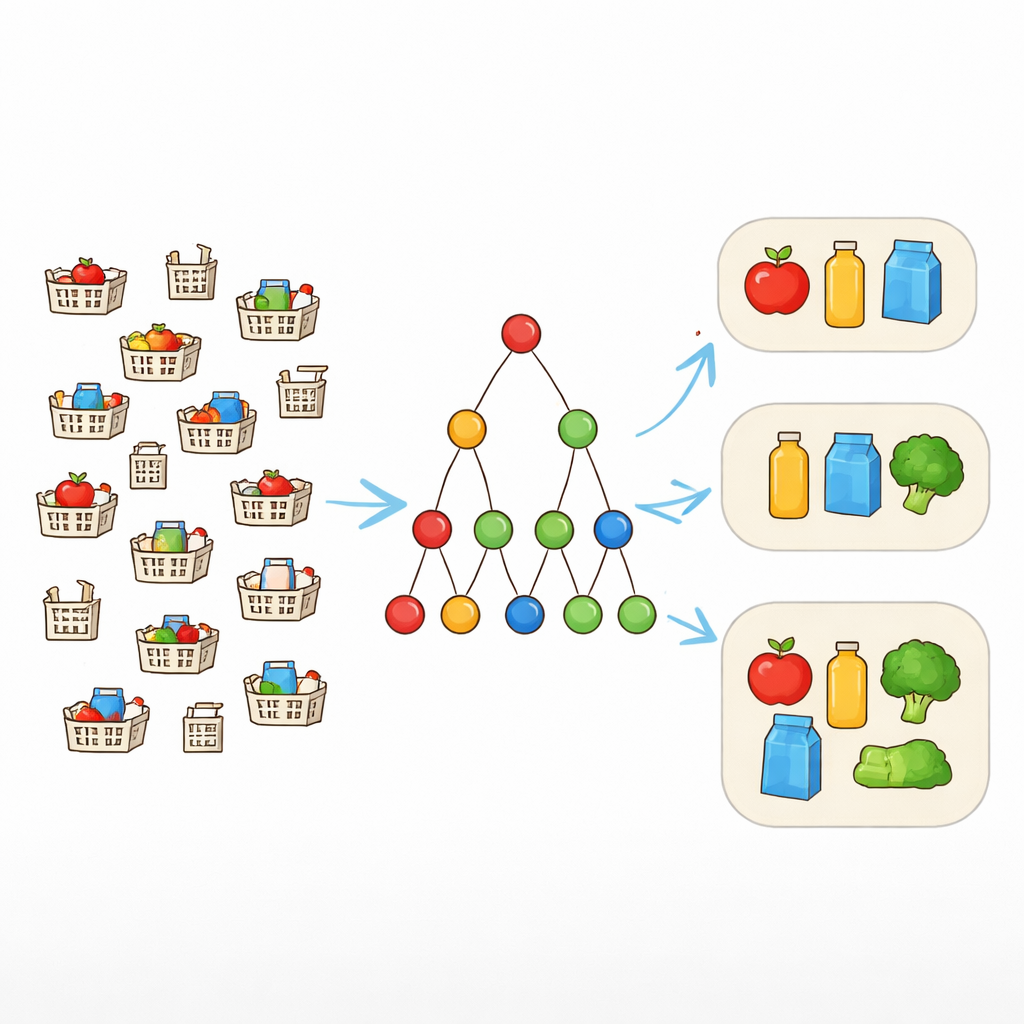
De coincidencias exactas a patrones flexibles
Las herramientas tradicionales de minería de patrones buscan combinaciones de ítems que aparezcan exactamente iguales en muchos registros. Eso funciona bien solo cuando los datos están limpios. En el mundo real, sin embargo, los carritos de compra que “deberían” contener el mismo paquete pueden diferir en uno o dos ítems. Para abordar esto, los investigadores usan una noción llamada tolerancia a fallos. En lugar de exigir que cada ítem de un patrón esté presente siempre, permiten un número elegido de ítems ausentes. Si un patrón es {portátil, ratón, teclado, auriculares} y la tolerancia es uno, entonces cualquier transacción que contenga al menos tres de estos sigue contando como apoyo al patrón. Esto permite al algoritmo reconocer paquetes realistas que aparecen en formas ligeramente distintas.
Por qué importa centrarse en los patrones más grandes
Permitir ítems ausentes facilita que los patrones califiquen como frecuentes, pero también hace explotar el espacio de búsqueda. Muchas combinaciones solapadas de diferentes tamaños se vuelven posibles, sobre todo en conjuntos de datos grandes de comercio o web. Listarlas todas abrumaría tanto a las máquinas como a los analistas. En cambio, el autor se concentra en patrones maximales —aquellos que no pueden extenderse añadiendo otro ítem sin volverse infrecuentes. Estos patrones maximales tolerantes a fallos ofrecen un resumen conciso: cada combinación frecuente más pequeña está contenida en al menos uno de ellos y puede reconstruirse más tarde si es necesario.
Hacer crecer patrones dentro de un árbol comprimido
Los métodos anteriores tolerantes a fallos extendían en gran medida un enfoque clásico que genera y prueba candidatos nivel por nivel. Esta estrategia sufre de escaneos repetidos del conjunto de datos completo y de un número enorme de candidatos. El nuevo algoritmo, llamado FT-MFI-PG, toma una ruta distinta inspirada en el crecimiento de patrones. Primero construye una estructura de árbol compacta que fusiona transacciones que comparten los mismos ítems iniciales. Cada camino a través de este árbol representa muchos registros similares, reduciendo mucho los datos mientras se preserva qué ítems tienden a aparecer juntos. Sobre esto, el algoritmo adjunta pequeñas tablas que registran con qué frecuencia coocurren los ítems, incluso cuando faltan algunos, de modo que la tolerancia a fallos se puede evaluar localmente sin volver a consultar los datos originales.
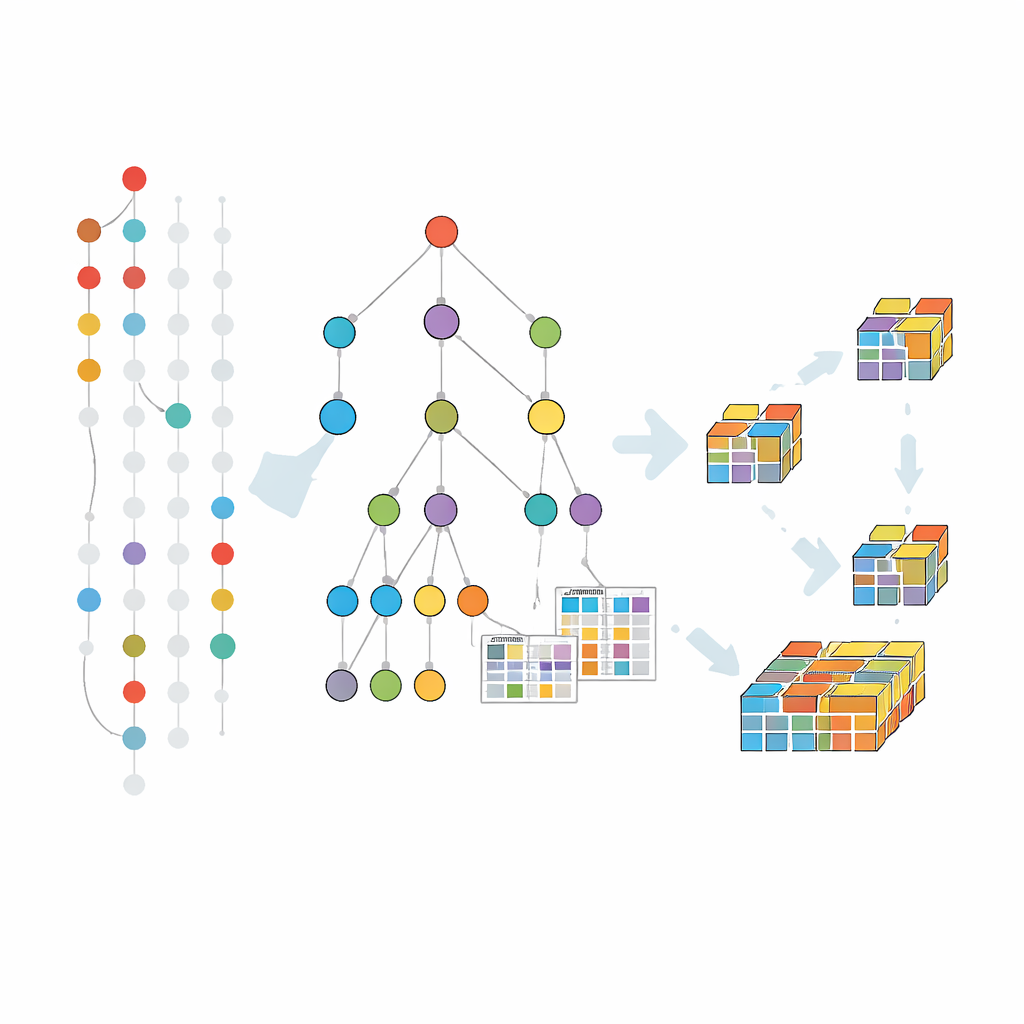
Acercándose a cómo funciona el método
La minería procede explorando este árbol de combinaciones más pequeñas a mayores, pero solo donde los datos sugieren que existen extensiones significativas. Para cada grupo prometedor de ítems, el algoritmo recopila el subconjunto de transacciones que los apoyan —permitiendo elementos faltantes según la tolerancia elegida— y luego construye un árbol más pequeño centrado en ese grupo. Este proceso de dividir y vencer se repite, haciendo crecer los patrones paso a paso y podando ramas que no pueden conducir a combinaciones frecuentes y tolerantes a fallos. Trucos de poda adicionales ayudan a saltarse áreas de la búsqueda que ya están cubiertas por patrones maximales conocidos, ahorrando tiempo y memoria.
Qué muestran los experimentos
El autor probó el nuevo método en varios conjuntos de referencia estándar de comercio minorista, navegación web y datos transaccionales sintéticos. A lo largo de una amplia gama de niveles de tolerancia y umbrales de frecuencia, el algoritmo de crecimiento de patrones encontró de manera consistente todos los patrones maximales tolerantes a fallos más rápido que técnicas competidoras, a menudo con márgenes amplios. También utilizó menos memoria que enfoques de crecimiento de patrones anteriores que construían múltiples árboles, aunque un método muy comprimido basado en bits siguió siendo el más esbelto en memoria a costa de la velocidad. Los beneficios fueron especialmente notables cuando los datos eran densos, ruidosos o contenían muchos ítems potencialmente frecuentes.
Por qué esto importa de cara al futuro
Para los practicantes, el mensaje clave es que ahora es más práctico descubrir patrones robustos y con significado humano en datos imperfectos sin ahogarse en resultados redundantes. Al combinar la tolerancia a fallos con un árbol que comprime transacciones y hace crecer patrones solo donde la evidencia los respalda, el método propuesto ofrece una forma escalable de extraer paquetes estables de carritos de compra, registros de sensores, clics web o historiales médicos. Aunque casos extremos con dimensionalidad muy alta aún pueden agotar la memoria, este trabajo muestra que el crecimiento de patrones es una base sólida para herramientas futuras que manejen datos en streaming, aprovechen hardware paralelo o adapten automáticamente el nivel de tolerancia al ruido presente en conjuntos de datos del mundo real.
Cita: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Palabras clave: minería de conjuntos de ítems frecuentes, patrones tolerantes a fallos, datos transaccionales ruidosos, algoritmos de crecimiento de patrones, árbol FP