Clear Sky Science · it
Un approccio di pattern-growth per l'estrazione di itemset frequenti massimali tolleranti agli errori
Trovare pattern affidabili in dati disordinati
Registri di acquisto, cartelle cliniche e letture dei sensori raramente sono perfetti. I codici a barre vengono mancati, i sensori guastano e i click non vengono registrati. Eppure aziende e ricercatori vogliono comunque sapere quali elementi compaiono ripetutamente insieme — per esempio bundle di prodotti, cluster di sintomi o segnali di frode. Questo articolo presenta un nuovo modo per scoprire combinazioni ricorrenti robuste in dati rumorosi, mantenendo al contempo il numero di pattern riportati piccolo e gestibile.
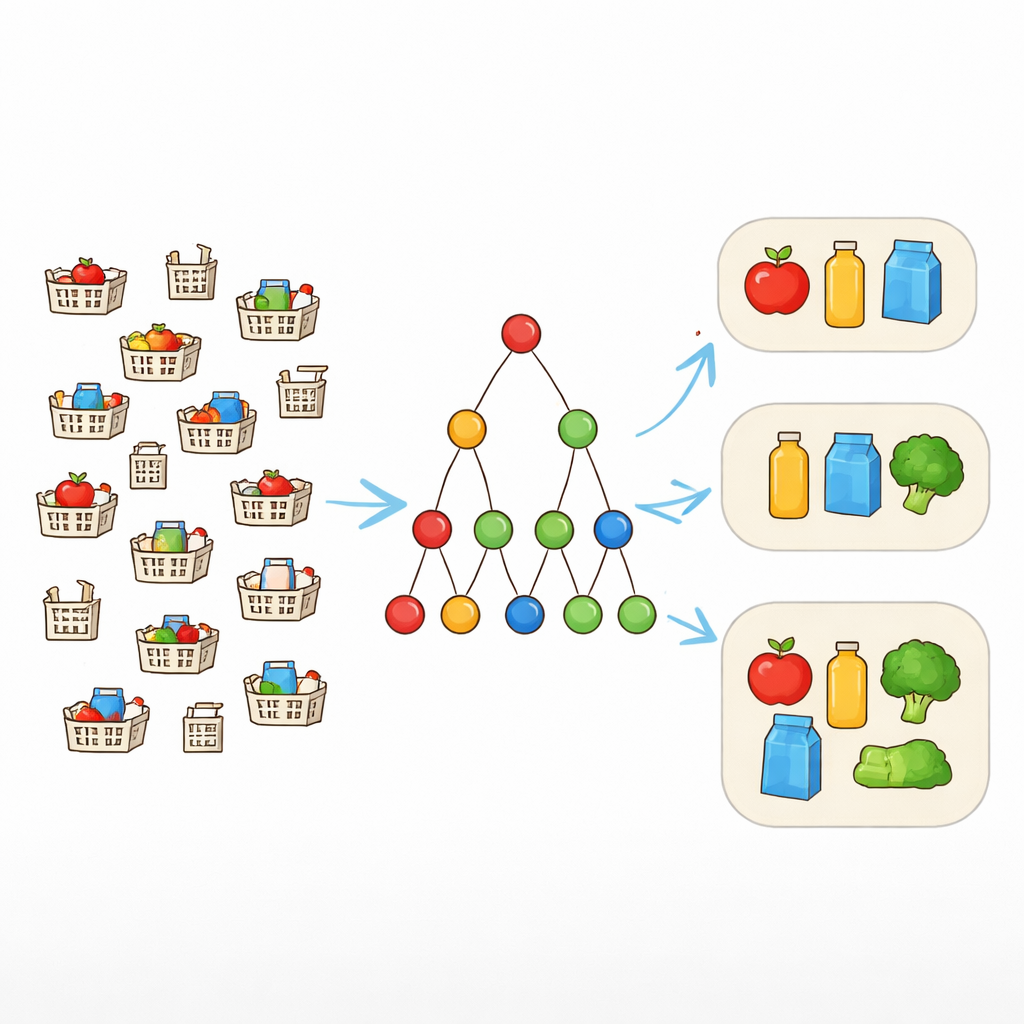
Dalle corrispondenze esatte a pattern più flessibili
Gli strumenti tradizionali di data mining cercano combinazioni di elementi che compaiono esattamente uguali in molti record. Questo funziona bene solo quando i dati sono puliti. Nel mondo reale, però, carrelli della spesa che “dovrebbero” contenere lo stesso bundle possono differire di uno o due articoli. Per affrontare questo problema, i ricercatori usano una nozione chiamata tolleranza agli errori. Invece di esigere che ogni elemento di un pattern sia presente sempre, si permette fino a un numero scelto di elementi mancanti. Se un pattern è {laptop, mouse, tastiera, cuffie} e la tolleranza è uno, allora qualsiasi transazione che contenga almeno tre di questi elementi conta ancora come supporto per il pattern. Questo permette all’algoritmo di riconoscere bundle realistici che appaiono in forme leggermente variate.
Perché concentrarsi sui pattern più grandi è importante
Consentire elementi mancanti facilita la qualificazione dei pattern come frequenti, ma fa anche esplodere lo spazio di ricerca. Molti pattern sovrapposti di diverse dimensioni diventano possibili, specialmente in grandi dataset retail o web. Elencarli tutti sopraffarebbe sia i computer sia gli analisti. Invece, l’autore si concentra sui pattern massimali — quelli che non possono essere estesi aggiungendo un altro elemento senza diventare infrequenti. Questi pattern massimali tolleranti agli errori forniscono un riepilogo conciso: ogni combinazione frequente più piccola è contenuta in almeno uno di essi e può essere ricostruita in seguito se necessario.
Crescere pattern all’interno di un albero compresso
I metodi fault-tolerant precedenti estendevano in gran parte un approccio classico che genera e testa candidati un livello alla volta. Tale strategia soffre di scansioni ripetute dell’intero dataset e di un numero enorme di candidati. Il nuovo algoritmo, chiamato FT-MFI-PG, segue una strada diversa ispirata al pattern growth. Costruisce prima una struttura ad albero compatta che fonde le transazioni che condividono gli stessi elementi iniziali. Ogni percorso attraverso questo albero rappresenta molte registrazioni simili, riducendo notevolmente i dati mantenendo però quali elementi tendono a comparire insieme. Su questa struttura, l’algoritmo aggiunge piccole tabelle che registrano quanto spesso gli elementi co-occorrono, anche quando alcuni mancano, in modo che la tolleranza possa essere valutata localmente senza riesaminare i dati originali.
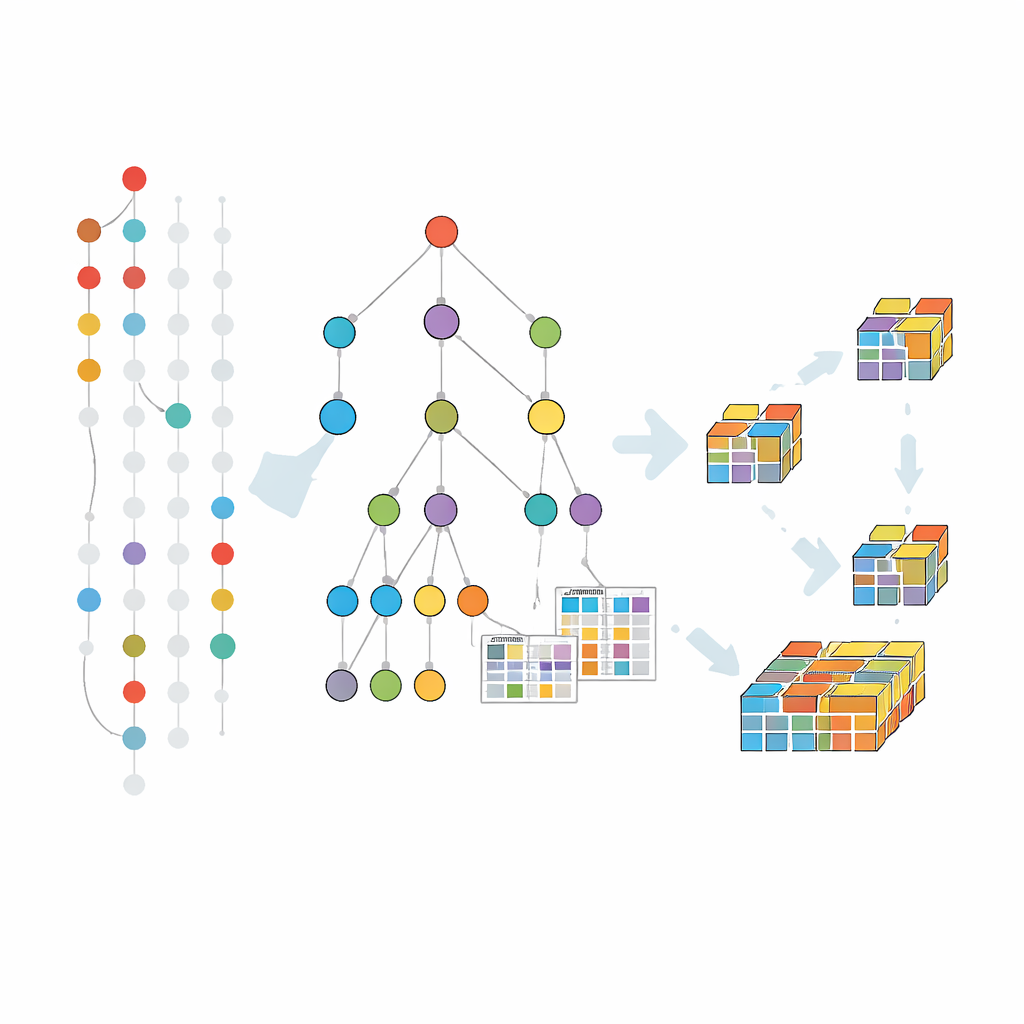
Un approfondimento su come funziona il metodo
L’estrazione procede esplorando questo albero da combinazioni più piccole a quelle più grandi, ma solo dove i dati suggeriscono che esistano estensioni significative. Per ogni gruppo promettente di elementi, l’algoritmo raccoglie il sottoinsieme di transazioni che li supportano — permettendo elementi mancanti secondo la tolleranza scelta — e poi costruisce un albero più piccolo focalizzato su quel gruppo. Questo processo divide-et-impera si ripete, facendo crescere i pattern passo dopo passo e potando i rami che non possono portare a combinazioni frequenti e tolleranti agli errori. Ulteriori tecniche di potatura consentono di saltare aree della ricerca già coperte da pattern massimali noti, risparmiando ulteriormente tempo e memoria.
Cosa mostrano gli esperimenti
L’autore ha testato il nuovo metodo su diversi dataset benchmark standard provenienti da retail, navigazione web e dati di transazioni sintetiche. Su una vasta gamma di livelli di tolleranza e soglie di frequenza, l’algoritmo pattern-growth ha trovato in modo consistente tutti i pattern massimali tolleranti agli errori più rapidamente delle tecniche concorrenti, spesso con margini significativi. Ha anche usato meno memoria rispetto ad approcci pattern-growth precedenti che costruivano alberi multipli, benché un metodo molto compresso basato su bit sia rimasto il più parsimonioso in memoria a scapito della velocità. I vantaggi sono risultati particolarmente evidenti quando i dati erano densi, rumorosi o contenevano molti elementi potenzialmente frequenti.
Perché questo è importante per il futuro
Per i praticanti, il messaggio chiave è che ora è più praticabile scoprire pattern robusti e significativi per l’essere umano in dati imperfetti senza annegare in risultati ridondanti. Combinando la tolleranza agli errori con un albero che comprime le transazioni e fa crescere i pattern solo dove le evidenze lo supportano, il metodo proposto offre un modo scalabile per estrarre bundle stabili da carrelli retail, log di sensori, click web o cartelle cliniche. Sebbene casi estremi con dimensionalità molto elevata possano ancora mettere sotto pressione la memoria, questo lavoro dimostra che il pattern growth è una solida base per strumenti futuri che gestiscano dati in streaming, sfruttino hardware parallelo o adattino automaticamente il livello di tolleranza al rumore presente nei dataset reali.
Citazione: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Parole chiave: estrazione di itemset frequenti, pattern tolleranti agli errori, dati di transazioni rumorosi, algoritmi pattern-growth, FP-tree