Clear Sky Science · he
שיטת גדילה לפי תבניות לחיפוש קבוצות פריטים תדירות חסינות-שגיאות
איתור תבניות מהימנות בנתונים מעורפלים
רשומות קניות, יומני רישום רפואיים ונתוני חיישנים נדירים להיות מושלמים. ברקודים לא נקראים, חיישנים נכשלים ולחיצות לא נרשמות. עם זאת עסקים ומדענים עדיין רוצים לדעת אילו פריטים מופיעים יחד בצורה מהימנה — כגון חבילות מוצרים, אשכולות תסמינים או סימני אזהרה להונאה. מאמר זה מציג שיטה חדשה לחשוף צירופים חוזרים חזקים מתוך נתונים רועשים כאלה, תוך שמירה על מספר התבניות המדווחות קטן וניהלי.
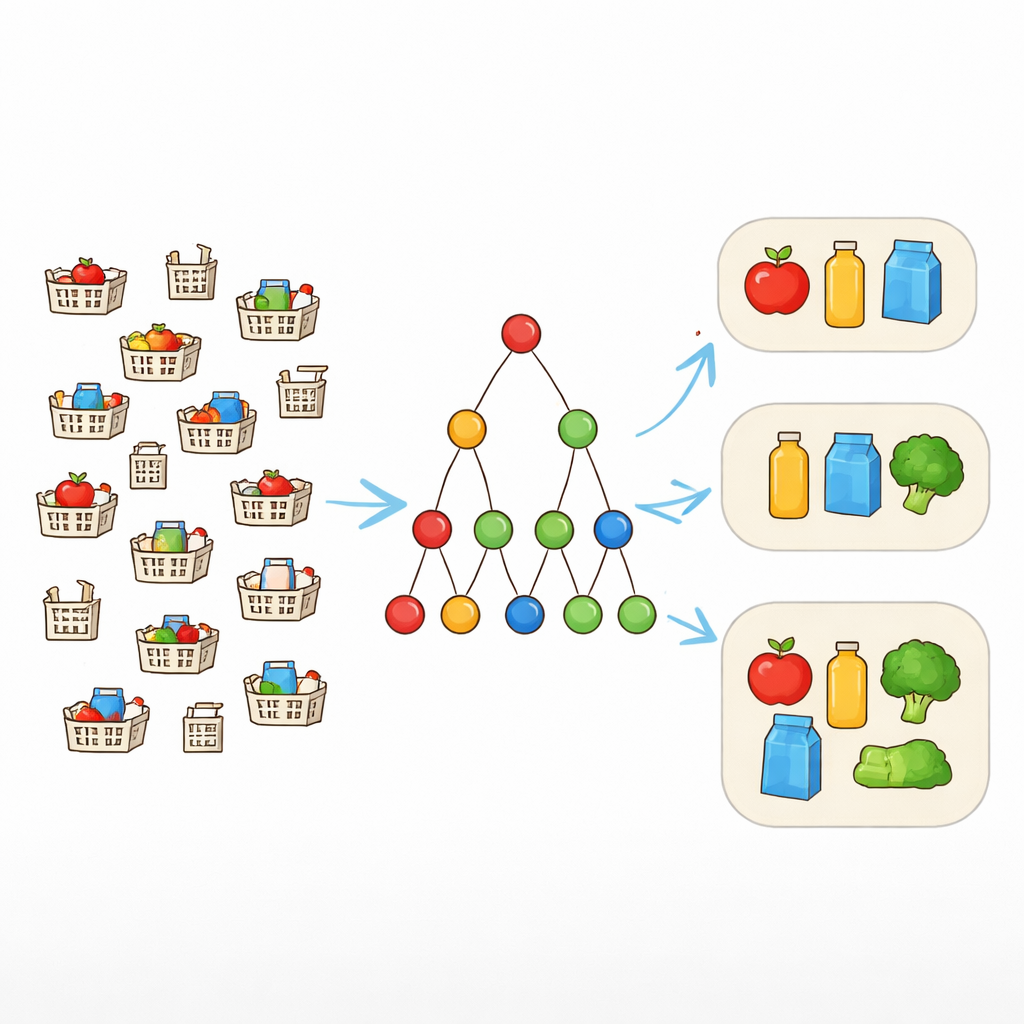
מתאמות מדויקות לתבניות גמישות
כלי כריית תבניות מסורתיים מחפשים צירופי פריטים שמופיעים בדיוק באותה צורה ברשומות רבות. זה עובד טוב רק כאשר הנתונים נקיים. בעולם האמיתי, לעומת זאת, עגלות קניות ש"צריכות" להכיל את אותה חבילה עשויות להיכלל בהבדלים של פריט או שניים. כדי להתמודד עם זה, חוקרים משתמשים במושג הנקרא חסינות-שגיאות. במקום לדרוש שכל פריט בתבנית יהיה נוכח בכל פעם, מאפשרים עד מספר נבחר של פריטים חסרים. אם התבנית היא {מחשב נייד, עכבר, מקלדת, אוזניות} והסובלנות היא אחד, אז כל עסקה שמכילה לפחות שלושה מתוך אלה עדיין נחשבת כתומכת בתבנית. זה מאפשר לאלגוריתם לזהות חבילות ריאליסטיות שמופיעות בצורות מעט שונות.
מדוע התמקדות בתבניות הגדולות חשובה
האפשרות לפריטים חסרים מקלה על כך שתבניות יעמדו בסף התדירות, אך גם גורמת להתפוצצות בחלל החיפוש. יכולות להיווצר הרבה תבניות חופפות בגדלים שונים, במיוחד במערכי קמעונאות או רשת גדולים. רישומן כולן יעמיס הן על המחשבים והן על האנליסטים. במקום זאת, המחבר מתמקד בתבניות מקסימליות — אלה שלא ניתן להרחיב על‑ידי הוספת פריט נוסף בלי להפוך לאי-תדירות. תבניות חסינות-שגיאות מקסימליות אלה מספקות סיכום תמציתי: כל צירוף תדיר קטן יותר כלול לפחות באחת מהן וניתן לשחזרו מאוחר יותר לפי הצורך.
גידול תבניות בתוך עץ דחוס
שיטות חסינות-שגיאות קודמות הרחיבו בעיקר גישה קלאסית שמייצרת ובודקת מועמדים שלב אחר שלב. אסטרטגיה זו סובלת מסריקות חוזרות של כל מאגר הנתונים וממספר עצום של מועמדים. האלגוריתם החדש, הקרוי FT-MFI-PG, נוקט בגישה שונה בהשראת גדילת-תבניות. הוא בונה תחילה מבנה עץ קומפקטי שממזג עסקאות שחולקות את הפריטים ההתחלתיים. כל מסלול בעץ הזה מייצג רשומות רבות דומות, וכך מצמצם מאוד את הנתונים תוך שמירה על האופן שבו פריטים נוטים להופיע יחד. על גבי זה מצרף האלגוריתם טבלאות קטנות שמרשימות באיזו תדירות פריטים מופיעים יחד, אפילו כשחלק חסרים, כך שניתן להעריך את חסינות-ההשגיאות מקומית מבלי לחזור לנתונים המקוריים.
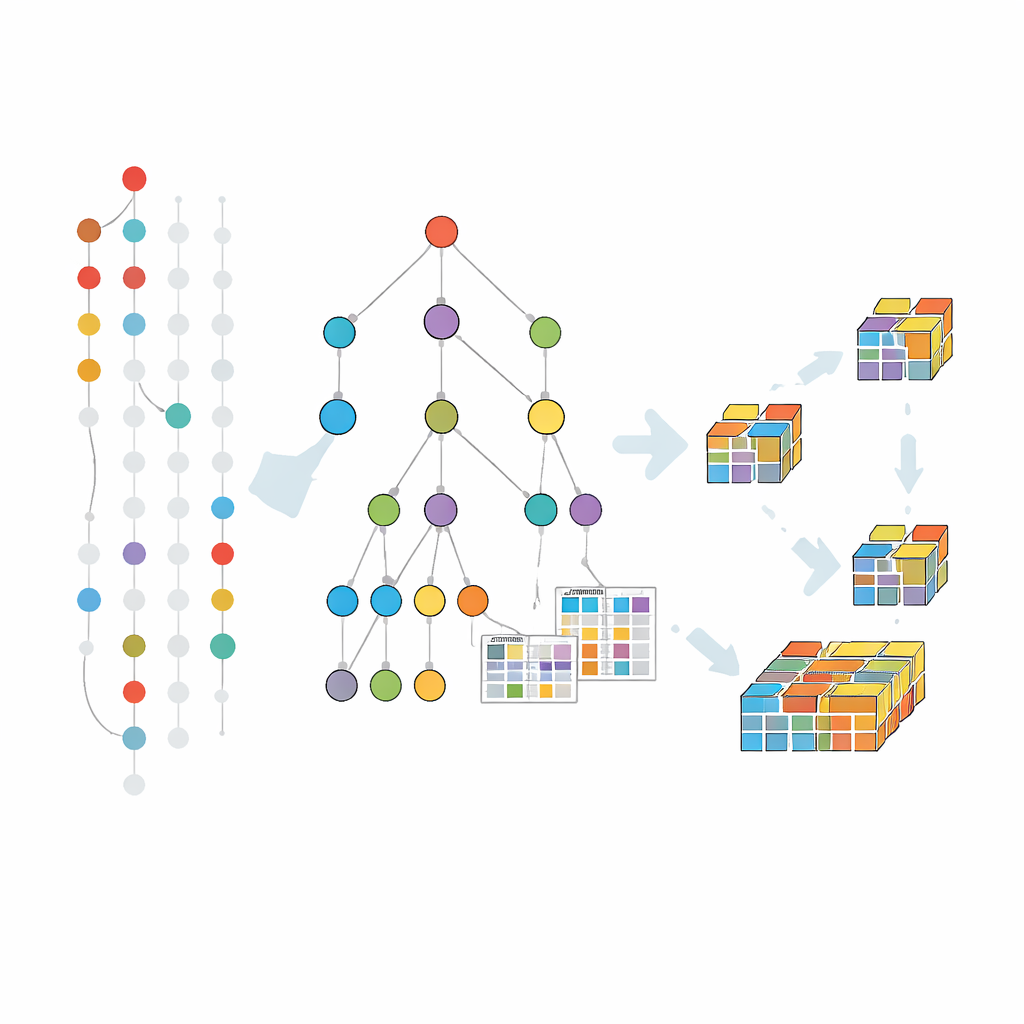
התבוננות מעמיקה על אופן פעולת השיטה
הכרייה מתבצעת על ידי חקירת העץ הזה מתצורות קטנות לגדולות, אך רק במקום שהנתונים מצביעים על קיום הרחבות משמעותיות. עבור כל קבוצה מבטיחה של פריטים, האלגוריתם אוסף את תת-הקבוצה של העסקאות שתומכות בהן — תוך אפשרות לפריטים חסרים לפי רמת הסובלנות הנבחרת — ואז בונה עץ קטן יותר שממוקד בקבוצה זו. תהליך פירוק וכיבוש זה חוזר על עצמו, מגדיל תבניות שלב אחר שלב וגוזם ענפים שלא יוכלו להוביל לצירופים תדירים וחסיני-שגיאות. טריקים נוספים של גזירה עוזרים לדלג על אזורי החיפוש שכבר מכוסים על ידי תבניות מקסימליות ידועות, וחוסכים זמן וזיכרון.
מה מראים הניסויים
המחבר בדק את השיטה החדשה על מספר מערכי מבחן תקניים מעולם הקמעונאות, גלישת רשת ונתוני עסקאות סינתטיים. בטווח רחב של רמות סובלנות וספי תדירות, אלגוריתם גדילת‑התבניות מצא באופן עקבי את כל התבניות המקסימליות חסינות‑השגיאות מהר יותר מטכניקות מתחרות, לעיתים בפערים גדולים. הוא גם השתמש בפחות זיכרון מאשר גישות גדילת‑תבניות קודמות שבנו עצים מרובים, אם כי שיטה מאוד דחוסה מבוססת סיביות נשארה היעילה בזיכרון במחיר מהירות. היתרונות בלטו במיוחד כאשר הנתונים היו צפופים, רועשים או כללו פריטים רבים שעשויים להיות תדירים.
מדוע זה חשוב לעתיד
למעשים, המסר המרכזי הוא שעכשיו מעשי יותר לגלות תבניות חזקות ובעלות משמעות אנושית בנתונים פגומים מבלי לטבוע בתוצאות מיותרות. על ידי שילוב חסינות‑שגיאות עם עץ שמדחס עסקאות וגדל תבניות רק כשיש הוכחות תומכות, השיטה המוצעת מציעה דרך מדרגת לחלץ חבילות יציבות מסלי קניות, יומני חיישנים, לחיצות רשת או רשומות רפואיות. בעוד שמקרים קיצוניים עם מימדיות גבוהה מאוד עדיין עלולים למתוח את הזיכרון, עבודה זו מראה שגדילת‑תבניות היא בסיס חזק לכלים עתידיים שיטפלו בזרמי נתונים, ינצלו חומרה מקבילית או יתאימו אוטומטית את רמת הסובלנות לרעש הנמצא במאגרים אמיתיים.
ציטוט: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
מילות מפתח: כריית קבוצות פריטים תדירות, תבניות חסינות-שגיאות, נתוני עסקאות רועשים, אלגוריתמי גדילת-תבניות, עץ FP