Clear Sky Science · pt
Uma abordagem de crescimento de padrões para mineração de conjuntos de itens frequentes tolerantes a falhas
Encontrando padrões confiáveis em dados imperfeitos
Registros de compras, prontuários médicos e leituras de sensores raramente são perfeitos. Códigos de barras deixam de ser lidos, sensores falham e cliques não são registrados. Ainda assim, empresas e cientistas querem saber quais elementos ocorrem juntos com regularidade — como conjuntos de produtos, aglomerados de sintomas ou sinais de fraude. Este artigo apresenta uma nova forma de descobrir combinações recorrentes fortes em dados dessa natureza, mantendo o número de padrões reportados pequeno e manejável.
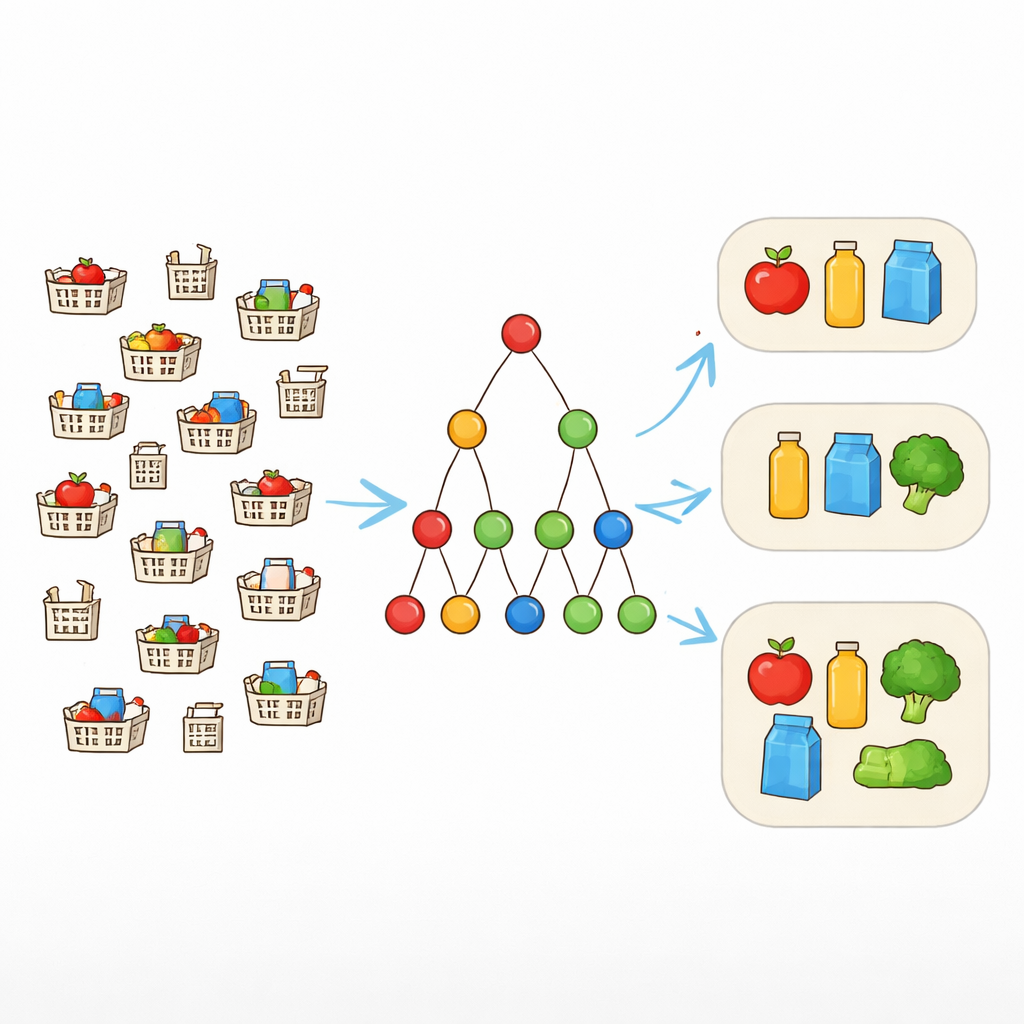
De correspondências exatas a padrões flexíveis
Ferramentas tradicionais de mineração de padrões procuram combinações de itens que apareçam exatamente iguais em muitos registros. Isso funciona bem apenas quando os dados estão limpos. No mundo real, entretanto, carrinhos de compra que “deveriam” conter o mesmo conjunto podem diferir por um ou dois itens. Para lidar com isso, pesquisadores usam uma noção chamada tolerância a falhas. Em vez de exigir que todo item de um padrão esteja presente sempre, permite-se um número escolhido de itens ausentes. Se um padrão é {notebook, mouse, teclado, fones} e a tolerância é um, então qualquer transação contendo ao menos três desses itens ainda conta como suporte ao padrão. Isso permite que o algoritmo reconheça conjuntos realistas que aparecem em formas ligeiramente variáveis.
Por que focar nos maiores padrões importa
Permitir itens ausentes facilita que padrões se qualifiquem como frequentes, mas também expande enormemente o espaço de busca. Muitos padrões sobrepostos de tamanhos diferentes se tornam possíveis, especialmente em grandes bases de varejo ou da web. Listá-los todos sobrecarregaria tanto computadores quanto analistas. Em vez disso, o autor se concentra em padrões maximais — aqueles que não podem ser estendidos adicionando outro item sem se tornarem infrequentes. Esses padrões tolerantes a falhas maximais fornecem um resumo conciso: toda combinação frequente menor está contida em pelo menos um deles e pode ser reconstruída depois se necessário.
Crescendo padrões dentro de uma árvore comprimida
Métodos anteriores tolerantes a falhas estendiam em grande parte uma abordagem clássica que gera e testa candidatos nível a nível. Essa estratégia sofre com várias leituras do conjunto de dados completo e um enorme número de candidatos. O novo algoritmo, chamado FT-MFI-PG, segue um caminho diferente inspirado no crescimento de padrões. Primeiro ele constrói uma estrutura de árvore compacta que mescla transações que compartilham os mesmos itens iniciais. Cada caminho por essa árvore representa muitos registros semelhantes, reduzindo muito os dados enquanto preserva quais itens tendem a aparecer juntos. Sobre isso, o algoritmo anexa pequenas tabelas que registram com que frequência itens coocorrem, mesmo quando alguns estão ausentes, de modo que a tolerância a falhas possa ser avaliada localmente sem revisitar os dados originais.
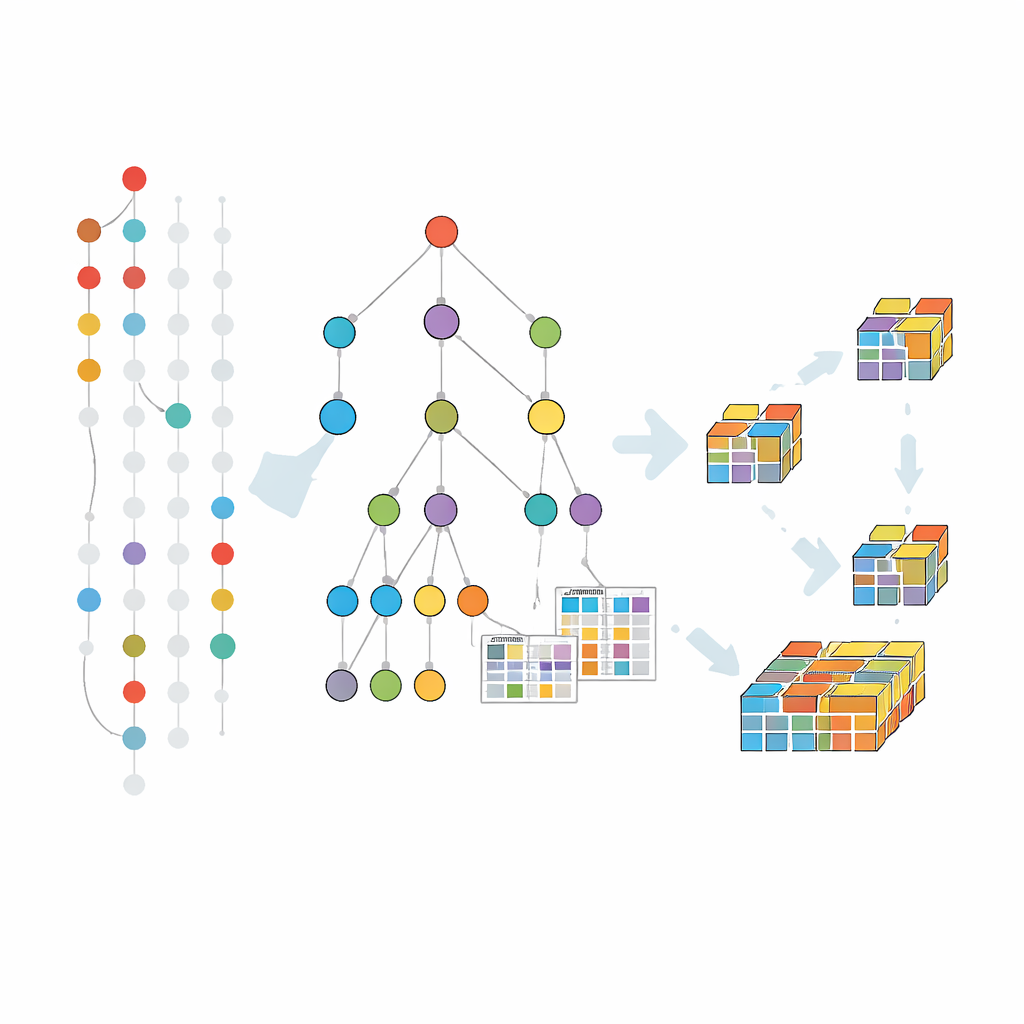
Aproximando-se de como o método funciona
A mineração procede explorando essa árvore de combinações menores para maiores, mas somente onde os dados sugerem que extensões significativas existem. Para cada grupo promissor de itens, o algoritmo coleta o subconjunto de transações que os suportam — permitindo elementos ausentes conforme a tolerância escolhida — e então constrói uma árvore menor focada nesse grupo. Esse processo de dividir e conquistar se repete, crescendo padrões passo a passo e podando ramos que não podem levar a combinações frequentes e tolerantes a falhas. Truques adicionais de poda ajudam a pular áreas da busca que já estão cobertas por padrões maximais conhecidos, economizando ainda mais tempo e memória.
O que os experimentos mostram
O autor testou o novo método em vários conjuntos de dados de referência padrão de varejo, navegação web e dados transacionais sintéticos. Em uma ampla faixa de níveis de tolerância e limiares de frequência, o algoritmo de crescimento de padrões encontrou consistentemente todos os padrões tolerantes a falhas maximais mais rápido que técnicas concorrentes, muitas vezes por margens significativas. Também usou menos memória que abordagens anteriores de crescimento de padrões que construíam múltiplas árvores, embora um método muito comprimido baseado em bitsets tenha permanecido o mais enxuto em memória à custa da velocidade. Os benefícios foram especialmente marcantes quando os dados eram densos, ruidosos ou continham muitos itens potencialmente frequentes.
Por que isso importa daqui para frente
Para praticantes, a mensagem-chave é que agora é mais prático descobrir padrões robustos e com significado humano em dados imperfeitos sem se afogar em resultados redundantes. Ao combinar tolerância a falhas com uma árvore que comprime transações e cresce padrões apenas onde as evidências as sustentam, o método proposto oferece uma maneira escalável de extrair conjuntos estáveis de cestas de varejo, registros de sensores, cliques web ou prontuários médicos. Embora casos extremos com dimensionalidade muito alta ainda possam tensionar a memória, este trabalho mostra que o crescimento de padrões é uma base sólida para ferramentas futuras que lidem com dados em fluxo, explorem hardware paralelo ou adaptem automaticamente o nível de tolerância ao ruído presente em conjuntos de dados do mundo real.
Citação: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Palavras-chave: mineração de conjuntos de itens frequentes, padrões tolerantes a falhas, dados transacionais ruidosos, algoritmos de crescimento de padrões, FP-tree