Clear Sky Science · ru
Подход на основе роста шаблонов для поиска максимальных часто встречающихся наборов с устойчивостью к сбоям
Поиск надёжных шаблонов в неряшливых данных
Записи о покупках, медицинские журналы и показания датчиков редко бывают идеальными. Штрихкоды пропускаются, датчики выходят из строя, клики могут не фиксироваться. Тем не менее бизнес и учёные хотят знать, какие элементы стабильно встречаются вместе — например, наборы товаров, кластеры симптомов или признаки мошенничества. В этой статье предложен новый способ выявления устойчивых повторяющихся комбинаций в таких шумных данных при сохранении компактного и управляемого количества получаемых шаблонов.
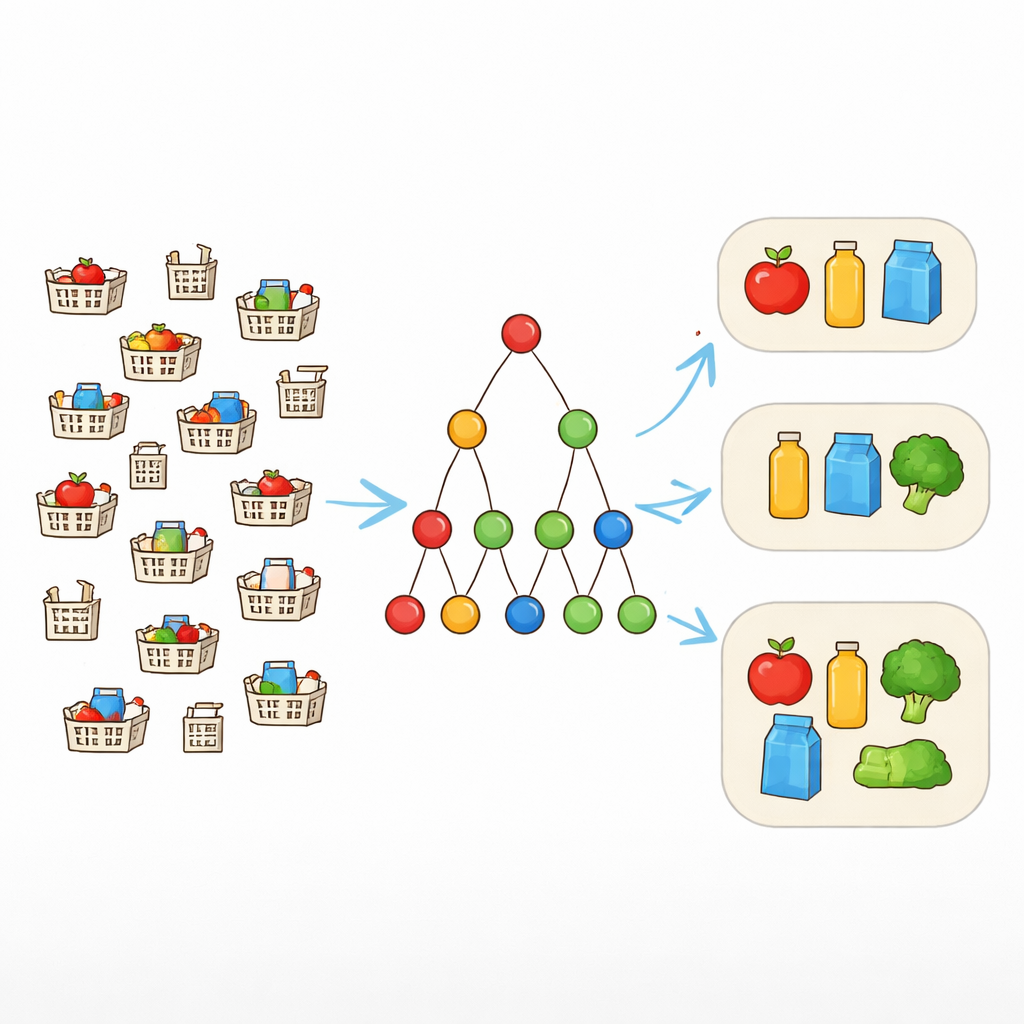
От точных совпадений к гибким шаблонам
Традиционные инструменты поиска шаблонов ищут комбинации элементов, которые встречаются в точности одинаковыми во многих записях. Это хорошо работает только при чистых данных. В реальном мире же корзины покупок, которые «должны» содержать один и тот же набор, могут отличаться на один–два предмета. Для решения этой проблемы исследователи используют понятие устойчивости к сбоям. Вместо требования, чтобы каждый элемент шаблона присутствовал всегда, допускают до заданного числа пропущенных элементов. Если шаблон — {ноутбук, мышь, клавиатура, наушники} и допустимость равна одному, то любая транзакция, содержащая как минимум три из них, всё ещё считается поддерживающей шаблон. Это позволяет алгоритму распознавать реалистичные наборы, которые появляются в слегка варьирующихся формах.
Почему важен фокус на самых больших шаблонах
Допуск пропущенных элементов облегчает шаблонам прохождение порога частоты, но одновременно взрывает пространство поиска. Появляется множество перекрывающихся шаблонов разного размера, особенно в крупных розничных или веб-датасетах. Перечисление всех таких шаблонов перегрузило бы и компьютеры, и аналитиков. Вместо этого автор сосредотачивается на максимальных шаблонах — тех, которые нельзя расширить добавлением ещё одного элемента, не сделав их нерегулярными. Эти максимальные устойчивые к сбоям шаблоны дают ёмкое резюме: каждая более мелкая частая комбинация содержится по крайней мере в одном из них и при необходимости может быть восстановлена позднее.
Рост шаблонов внутри сжатого дерева
Ранние методы с учётом устойчивости к сбоям в основном расширяли классический подход генерации и проверки кандидатов по уровням. Такая стратегия страдает от многократных обходов полного набора данных и огромного числа кандидатов. Новый алгоритм под названием FT-MFI-PG идёт иным путём, вдохновлённым идеей роста шаблонов. Сначала он строит компактную древовидную структуру, которая объединяет транзакции с одинаковыми начальными элементами. Каждый путь в этом дереве представляет множество схожих записей, существенно уменьшая объём данных при сохранении информации о том, какие элементы склонны появляться вместе. Поверх этого алгоритм прикрепляет небольшие таблицы, фиксирующие частоты совместного появления элементов, даже когда некоторые отсутствуют, так что оценка устойчивости к сбоям выполняется локально без повторного обращения к исходным данным.
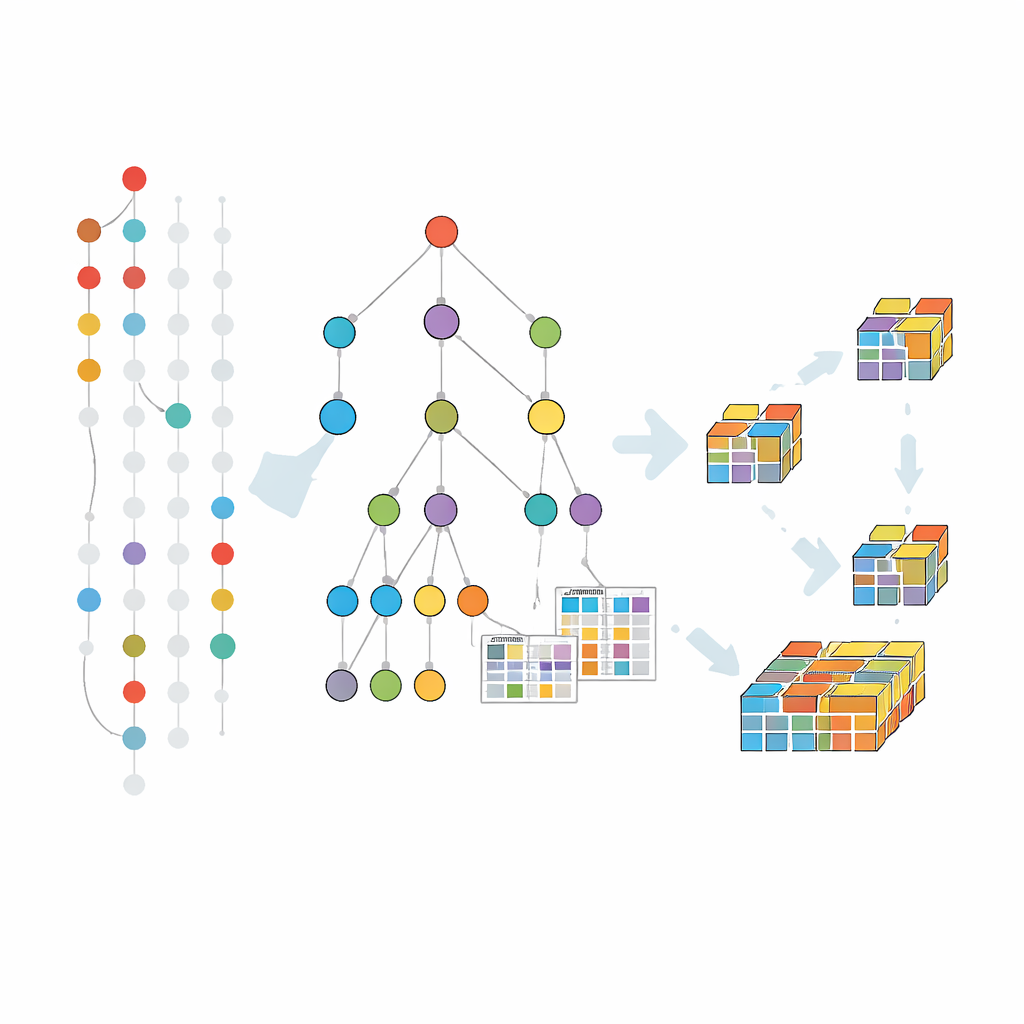
Подход к тому, как работает метод
Поиск шаблонов осуществляется путём исследования этого дерева от меньших комбинаций к большим, но только в тех ветвях, где данные указывают на смысловые расширения. Для каждой перспективной группы элементов алгоритм собирает подмножество транзакций, которые их поддерживают — с учётом допустимых пропусков — и строит затем меньшее дерево, сфокусированное на этой группе. Этот приём «разделяй и властвуй» повторяется: шаблоны растут шаг за шагом, а ветви, которые не могут привести к частым устойчивым комбинациям, отсеиваются. Дополнительные трюки отсечения помогают пропускать участки поиска, уже покрытые известными максимальными шаблонами, что ещё больше экономит время и память.
Что показывают эксперименты
Автор протестировал новый метод на нескольких стандартных эталонных наборах из розничной торговли, веб-сёрфинга и синтетических транзакционных данных. В широком диапазоне уровней допустимости и порогов частоты алгоритм роста шаблонов последовательно находил все максимальные устойчивые к сбоям шаблоны быстрее конкурентов, часто с существенным отрывом. Он также использовал меньше памяти, чем более ранние подходы на основе роста шаблонов, строившие множество деревьев, хотя очень сжатый битовый метод оставался наиболее экономным по памяти ценой скорости. Преимущества особенно заметны в плотных, шумных данных или при наличии большого числа потенциально частых элементов.
Почему это важно для будущего
Для практиков ключевой вывод таков: стало более реально обнаруживать устойчивые, понятные человеку шаблоны в несовершенных данных без утопления в избыточных результатах. Сочетая устойчивость к сбоям с деревом, сжимающим транзакции и строящим шаблоны только там, где данные это обосновывают, предложенный метод предоставляет масштабируемый способ извлекать стабильные наборы из корзин покупок, журналов датчиков, кликов в вебе или медицинских записей. Хотя в крайне высокоразмерных случаях память всё ещё может исчерпываться, эта работа демонстрирует, что рост шаблонов — прочная основа для будущих инструментов, которые будут обрабатывать потоковые данные, задействовать параллельное оборудование или автоматически подстраивать уровень допустимости под шум реальных данных.
Цитирование: Bashir, S. A pattern-growth approach for mining maximal fault-tolerant frequent itemsets. Sci Rep 16, 14556 (2026). https://doi.org/10.1038/s41598-026-44941-3
Ключевые слова: поиск частых наборов, устойчивые к сбоям шаблоны, шумные данные транзакций, алгоритмы роста шаблонов, FP-дерево