Clear Sky Science · tr
Görsel transformerlar kullanılarak heyelan tespiti için çok katmanlı piramit havuzlama öz-dikkati
Yamaçları Uzaydan İzlemek
Heyelanlar çoğu zaman az bir uyarıyla meydana gelip evleri yok edebilir, yolları kapatabilir ve can güvenliğini tehlikeye atabilir. Dünyanın dört bir yanında bilim insanları artık dengesiz yamaçları yukarıdan izlemek için uydu ve drone görüntülerine güveniyor; ancak milyonlarca pikselden güvenilir uyarılar üretmek büyük bir zorluktur. Bu makale, uzaktan algılama görüntülerini daha verimli ve daha doğru okuyan yeni bir yapay zeka yaklaşımını sunuyor; böylece yerin kaydığı ve tehlikenin hala sürdüğü yerleri haritalamaya yardımcı oluyor.
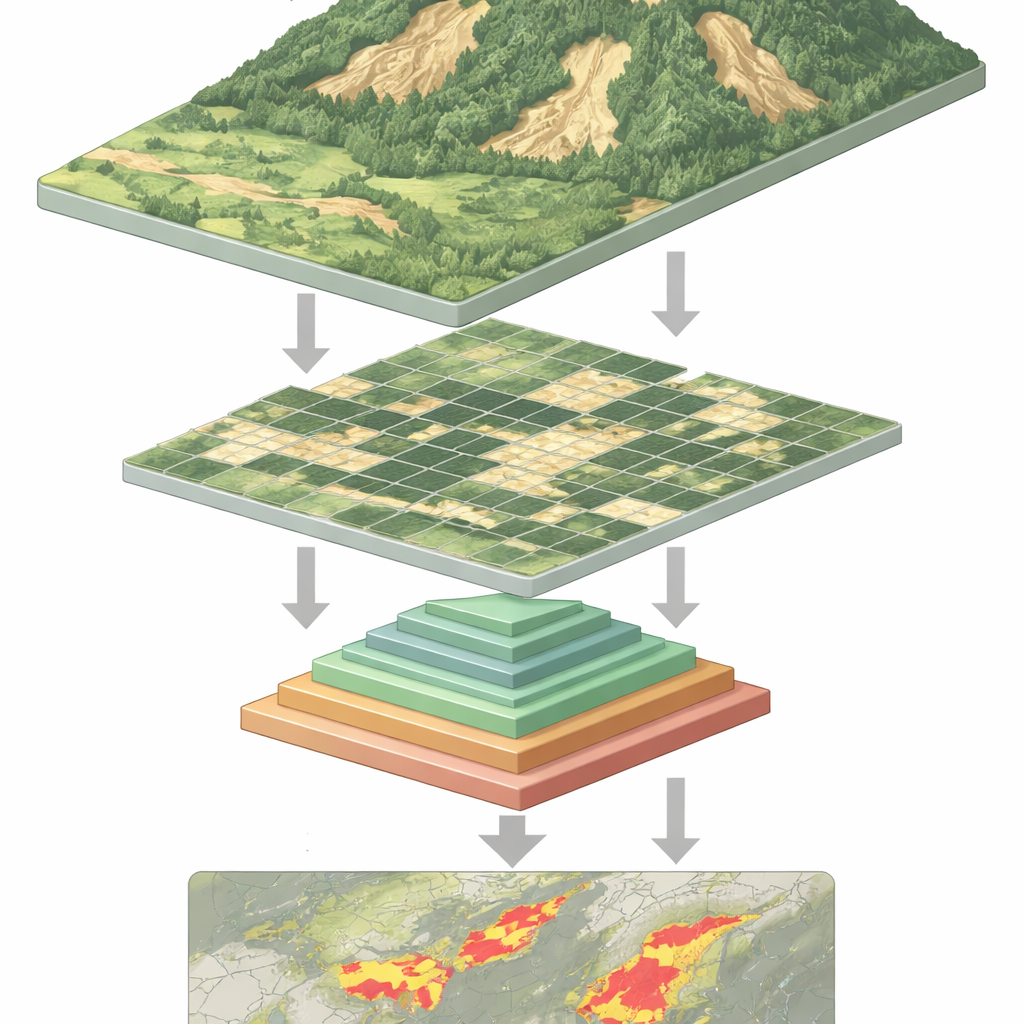
Heyelanları Tespit Etmeyi Zorlaştıran Nedir?
Uzaydan bakıldığında taze bir heyelan yeşil bir yamaçta soluk bir yara gibi görünebilir—ama her zaman değil. Heyelanlar çeşitli boyut ve biçimlerde olur, ağaçlar veya gölgeler tarafından kısmen gizlenebilir ve sıklıkla tarım veya inşaat nedeniyle açığa çıkmış çıplak toprağa benzeyebilir. Geleneksel bilgisayar programları ve hatta birçok derin öğrenme sistemi bu çeşitlilikle başa çıkmakta zorlanır. Görüntü tanımanın önceki iş atları olan konvolüsyonel sinir ağları yerel desenlerde iyidir ama bir yamaçtaki geniş bağlamı kaçırabilir. Yeni “görsel transformer” modelleri bu daha geniş bağlamı alabiliyor, fakat bunun bir bedeli var: görüntüdeki her küçük yaması analiz etmek için çok uzun veri dizileriyle uğraşmak zorunda kalıyorlar; bu da yüksek hesaplama gerektiriyor ve onları yavaşlatıyor.
Makinelere Çok Ölçekli Görmeyi Öğretmek
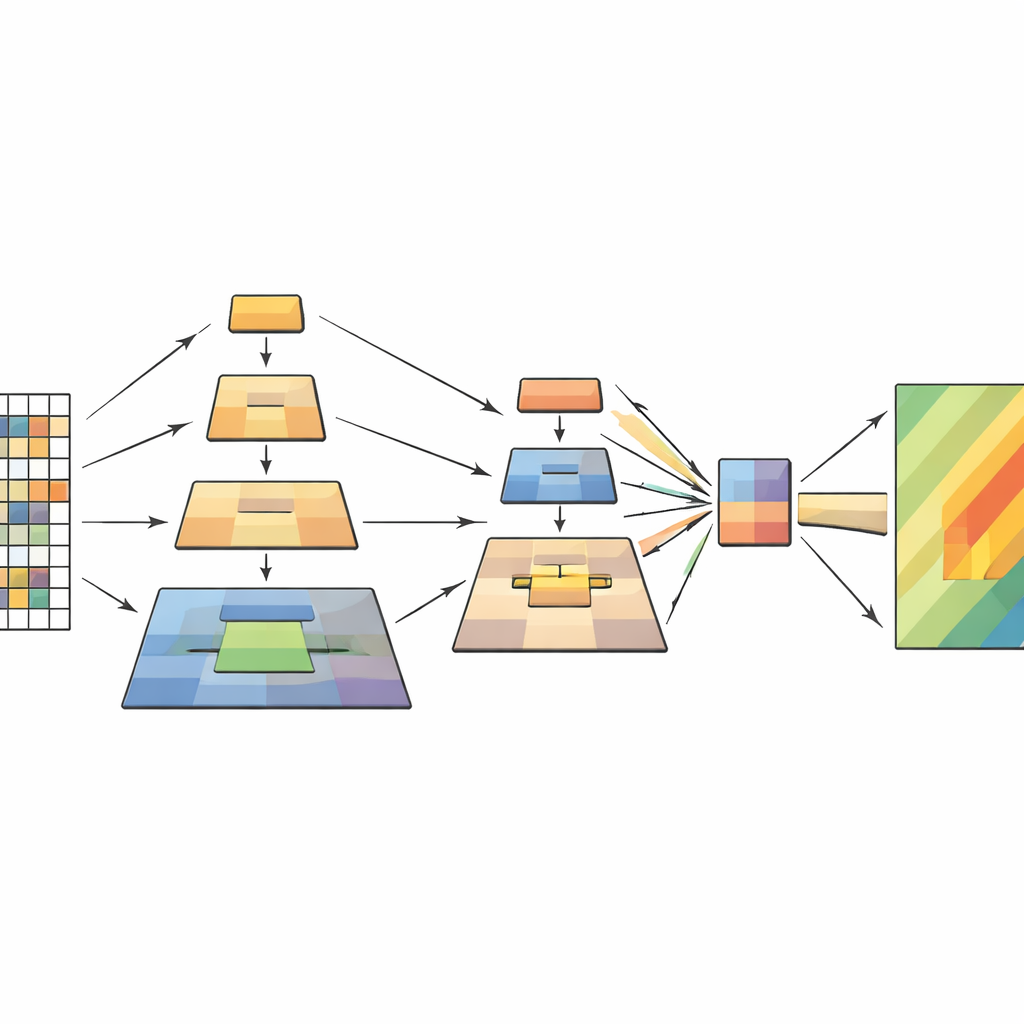
Çalışma bu darboğazı, görsel transformerlara dayanarak ama piramit havuzlama adı verilen önceki görüntü işleme fikrinden yararlanarak ele alıyor. Temel iç görü, bir sahnenin aynı anda birkaç ölçekte anlaşılması gerektiği: çatlaklar veya enkaz alanları gibi küçük detaylar, kayan bir yamaç gibi orta ölçekli özellikler ve genel eğim ile çevresi gibi geniş desenler. Görüntüyü tek bir havuzlama adımıyla küçültmek yerine, yeni model transformer’ın içinde farklı ölçeklerde birden çok havuzlama işlemi gerçekleştiriyor. Bu havuzlanmış versiyonlar bir piramit katmanları gibi üst üste konuyor ve ardından modelin dikkat mekanizmasına besleniyor; bu mekanizma görüntünün hangi bölümlerinin birbirini etkilemesi gerektiğine karar veriyor.
Yeni Model İçeride Nasıl Çalışıyor
Ağ her uzaktan algılama görüntüsünü dört aşamada işler. Önce görüntüyü küçük yamalara böler ve bunları bir token ızgarasına dönüştürür. Veri derinleştikçe, birbirine yakın yamalar gruplanır ve mekansal çözünürlük kademeli olarak azalır; böylece bir özellik haritaları hiyerarşisi oluşur. Her aşama içinde çok katmanlı piramit havuzlama modülü bu özelliklerin birden çok küçültülmüş görünümünü oluşturur ve bunları daha kısa, daha zengin bir diziye birleştirir. Dikkat mekanizması sonra orijinal görüntüyü sorgu olarak kullanır—burada "burada ne önemli?" diye soran kısımlar—ve havuzlanmış görünümleri anahtarlar ve değerler olarak kullanır—cevabı veren özümsenmiş bağlam. Ek hafif konvolüsyon blokları iki boyutlu yapıyı koruyarak modelin heyelanları işaretleyen şekillere, kenarlara ve dokulara duyarlı kalmasına yardımcı olur.
Yöntemi Teste Sokmak
Bu tasarımın ne kadar iyi çalıştığını görmek için yazarlar Çin Bilimler Akademisi tarafından derlenen büyük, açık bir heyelan veri seti üzerinde eğitip test ettiler. Bu koleksiyon, uydular ve dronlardan elde edilmiş yirmi binden fazla görüntü içeriyor ve birçok bölgeyi, arazi tipini ve görüntüleme koşulunu kapsıyor. Yeni model klasik U-Net ve DeepLab ağlarından Swin Transformer gibi modern transformer tabanlı sistemlere ve BisDeNet adında yakın zamanlı hafif bir heyelan algılayıcısına kadar güçlü rakiplerle karşılaştırıldı. Kesinlik, çağırma, F1-skoru, kesişim-bölüm-küme (IoU) ve genel doğruluk gibi standart ölçütlerin tümünde çok katmanlı piramit havuzlama transformerı tutarlı şekilde öne çıktı; önde gelen alternatiflere kıyasla F1-skorunu 7.3 yüzde puanı ve genel doğruluğu 2 yüzde puanı artırdı.
Sayılarla Gerçek Araziler Arasındaki Bağ
Ham puanların ötesinde, araştırmacılar modelin öngörülerini görsel olarak inceledi. Modelin genellikle yamaç kırılmalarına, uzunlanmış yaralara ve heyelan yollarına özgü karışık yüzey dokularına odaklandığı görüldü. Hatalar çoğunlukla görüntünün kendisinin belirsiz olduğu yerlerde—örneğin nehir kıyıları, açıkta kalmış toprak veya zayıf sınırları olan küçük kaymalar—meydana geliyordu; belirgin sistematik hatalardan ziyade. Nepal, Bijie ve Tangjiashan gibi yerlerden alınan birkaç ek veri seti üzerindeki testler yöntemin farklı manzaralara makul ölçüde uyum sağladığını gösteriyor; bu da yöntemin tek bir bölgenin gariplikleri yerine heyelanların genel imzalarını yakaladığına işaret ediyor.
Daha Güvenli Yamaçlar İçin Anlamı
Basitçe söylemek gerekirse, makale güçlü bir yapay zeka türünün yamaçlara daha verimli ve daha akıllıca "bakmasını" nasıl sağlanacağını gösteriyor. Modelin çekirdek dikkat mekanizması içinde bilgiyi birden çok ölçekte havuzlamasına izin vererek hesaplama yükünü azaltırken heyelanları belirlemek için gereken geniş resmi ve ince detayları koruyor. Sonuç, uydu ve drone görüntü akışlarını dengesiz zemin haritalarına dönüştürmek için daha hızlı ve daha doğru bir araç. Bu tür haritalar, afet sonrası hasar değerlendirmelerini, uzun vadeli tehlike izlemeyi ve değişim tespitini destekleyerek planlamacılara ve acil durum yöneticilerine yerin nerede zaten hareket ettiğine—ve gelecekte nerede hareket edebileceğine—daha net bir görüş sağlayabilir.
Atıf: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Anahtar kelimeler: heyelan tespiti, uzaktan algılama, görsel transformerlar, piramit havuzlama, anlamsal segmentasyon