Clear Sky Science · ru
Многоуровневое пирамидальное пулинг-внимание для обнаружения оползней с использованием vision-transformer
Наблюдение за склонами из космоса
Оползни могут случиться почти без предупреждения, разрушая дома, перекрывая дороги и угрожая жизни людей. Сейчас учёные по всему миру используют спутники и дроны, чтобы наблюдать за нестабильными склонами сверху, но перевод миллионов пикселей в надёжные предупреждения — серьёзная задача. В этой статье представлен новый подход на базе искусственного интеллекта, который эффективнее и точнее анализирует изображения дистанционного зондирования, помогая картировать места уже произошедших сдвигов и зоны, где опасность всё ещё сохраняется.
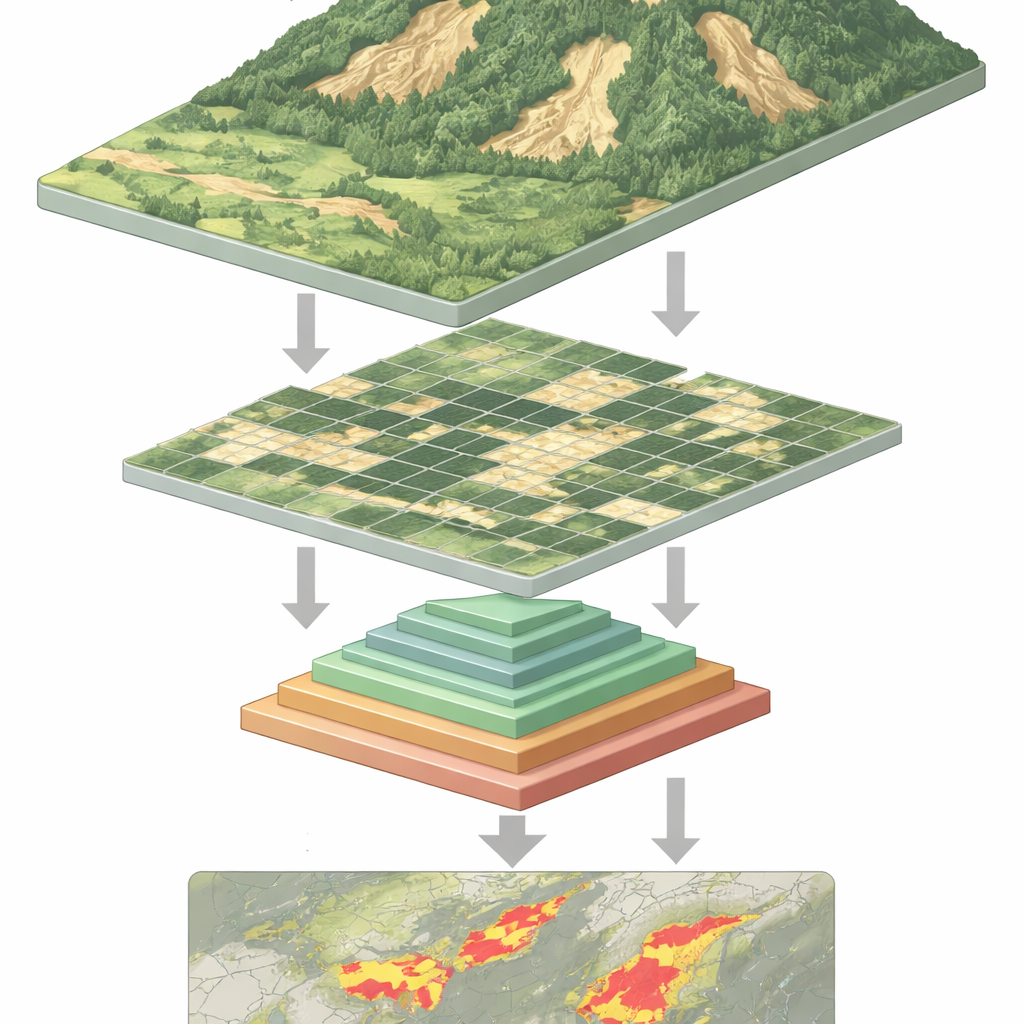
Почему распознать оползни так сложно
С высоты свежий оползень может выглядеть как бледный шрам на зелёном склоне — но не всегда. Оползни бывают разных размеров и форм, могут частично скрываться под деревьями или тенями и часто похожи на обнажённую почву, оставленную сельским хозяйством или стройкой. Традиционные алгоритмы и даже многие системы глубокого обучения с трудом справляются с таким разнообразием. Свёрточные нейронные сети, прежние рабочие лошадки распознавания изображений, хорошо улавливают локальные паттерны, но могут упускать общий контекст склона. Новые модели «vision transformer» охватывают более широкий контекст, но платят за это: чтобы проанализировать каждую мелкую часть изображения, им приходится работать с очень длинными последовательностями данных, что требует больших вычислительных ресурсов и замедляет работу.
Обучение машин видеть на разных масштабах
В работе предложено преодолеть это узкое место, опираясь на vision-transformer и заимствуя удачную идею из предыдущих исследований по обработке изображений — пирамидальный пулинг. Ключевое наблюдение в том, что сцену следует понимать сразу на нескольких масштабах: крошечные детали вроде трещин или полей обломков, средние объекты вроде сползающего участка склона и крупные закономерности вроде общей формы рельефа и окружения. Вместо одного шага усреднения изображения новая модель выполняет несколько операций пулинга на разных масштабах внутри самого трансформера. Эти уменьшенные представления укладываются слоями, как пирамиды, и подаются в механизм внимания модели, который решает, какие части изображения должны взаимодействовать между собой.
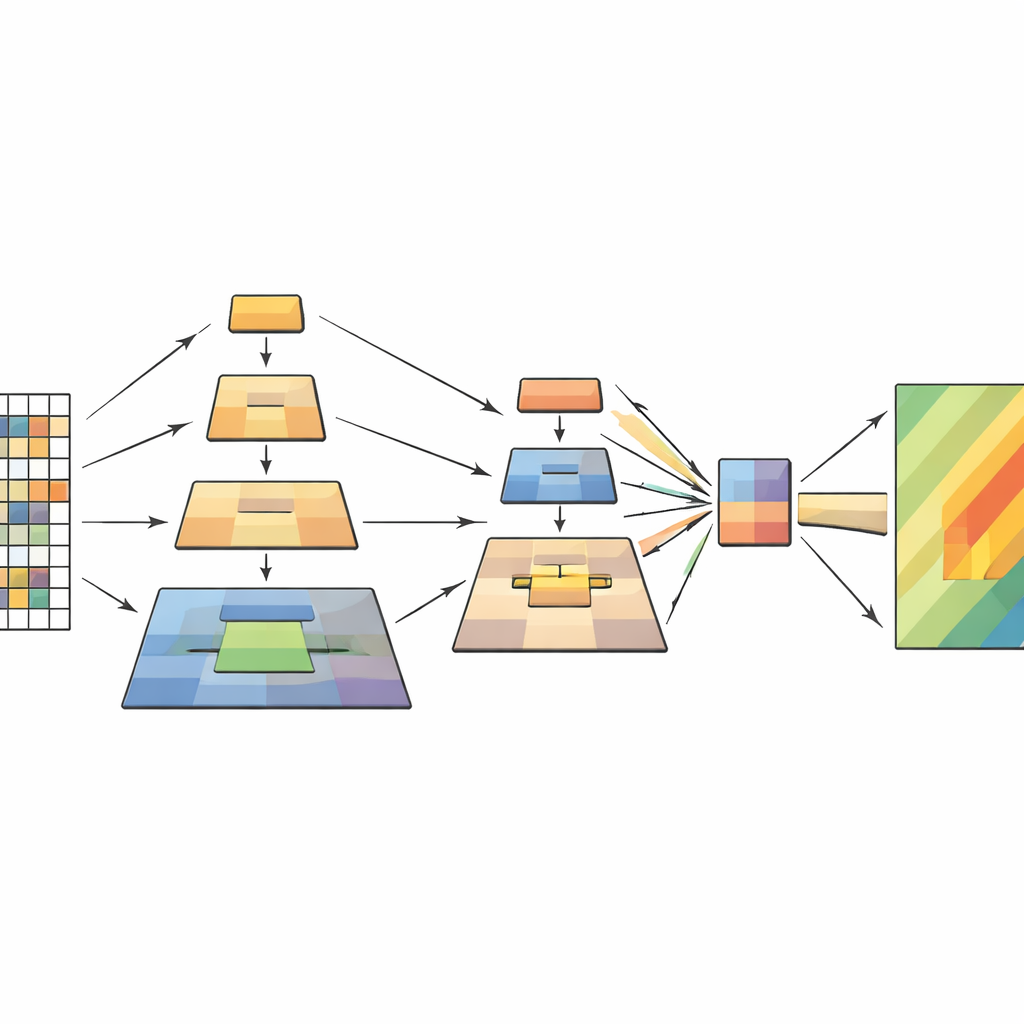
Как устроена новая модель внутри
Сеть обрабатывает каждое изображение дистанционного зондирования в четыре этапа. Сначала изображение разрезается на мелкие патчи и превращается в сетку токенов. По мере продвижения данных вглубь соседние патчи группируются, и их пространственное разрешение постепенно уменьшается, формируя иерархию карт признаков. Внутри каждого этапа модуль многоуровневого пирамидального пулинга создаёт несколько уменьшенных представлений этих признаков и объединяет их в более короткую, но насыщенную последовательность. Механизм внимания затем использует исходное изображение в роли запроса — тех частей, которые спрашивают «что здесь важно?» — а пулингованные представления выступают в роли ключей и значений — сжатого контекста, который отвечает. Дополнительные лёгкие сверточные блоки сохраняют ощущение двумерной структуры, помогая модели лучше учитывать формы, края и текстуры, характерные для оползней.
Проверка метода на практике
Чтобы оценить эффективность подхода, авторы обучили и протестировали его на большой публичной базе данных оползней, собранной Китайской академией наук. В коллекции более двадцати тысяч изображений со спутников и дронов, охватывающих разные регионы, рельефы и условия съёмки. Новую модель сравнивали с сильными конкурентами: от классических U-Net и DeepLab до современных систем на базе трансформеров, таких как Swin Transformer, и недавнего лёгкого детектора оползней BisDeNet. По комплексу стандартных метрик — точности, полноты, F1-меры, перекрытия (IoU) и общей точности — многоуровневый пирамидальный трансформер стабильно показывал лучшие результаты, повышая F1 на 7,3 процентных пункта и общую точность на 2 процентных пункта по сравнению с ведущими альтернативами.
От чисел к реальным ландшафтам
Помимо числовых показателей, исследователи визуально проанализировали предсказания модели. Они обнаружили, что она склонна фокусироваться на разрывах склона, вытянутых шрамах и смешанных текстурах поверхности, типичных для путей оползней. Ошибки в основном возникают там, где сами изображения неоднозначны — например, на берегах рек, обнажённой почве или маленьких оползнях с едва заметными контурами — а не из-за явных систематических сбоев. Тесты на нескольких дополнительных наборах данных из Непала, Бижэ и Танцзясана показывают, что метод достаточно хорошо адаптируется к разным ландшафтам, что говорит о том, что он улавливает общие признаки оползней, а не особенности одной области.
Что это значит для безопасности склонов
Проще говоря, статья показывает, как сделать так, чтобы мощный тип ИИ «смотрел» на склоны эффективнее и разумнее. Позволяя модели агрегировать информацию на нескольких масштабах внутри её основного механизма внимания, удаётся снизить вычислительную нагрузку, сохранив при этом и общую картину, и мелкие детали, необходимые для очерчивания оползней. В результате получается более быстрый и точный инструмент для превращения потоков спутниковых и дроновских изображений в карты нестабильных участков. Такие карты могут поддержать послесобытийную оценку ущерба, долгосрочный мониторинг опасных зон и обнаружение изменений, давая планировщикам и службам экстренного реагирования более ясное представление о том, где земля уже сдвинулась — и где это может произойти в будущем.
Цитирование: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Ключевые слова: обнаружение оползней, дистанционное зондирование, vision-transformer, пирамидальный пулинг, семантическая сегментация