Clear Sky Science · pt
Autoatenção com pooling em pirâmide multilayer para detecção de deslizamentos usando vision transformers
Observando Encostas a partir do Espaço
Deslizamentos podem ocorrer com pouca antecedência, destruindo casas, bloqueando estradas e colocando vidas em risco. Em todo o mundo, cientistas contam hoje com satélites e drones para monitorar encostas instáveis a partir do alto, mas transformar milhões de pixels em alertas confiáveis é um grande desafio. Este artigo apresenta uma nova abordagem de inteligência artificial que interpreta imagens de sensoriamento remoto de forma mais eficiente e precisa, auxiliando a mapear onde o solo já deslizou e onde o perigo ainda persiste.
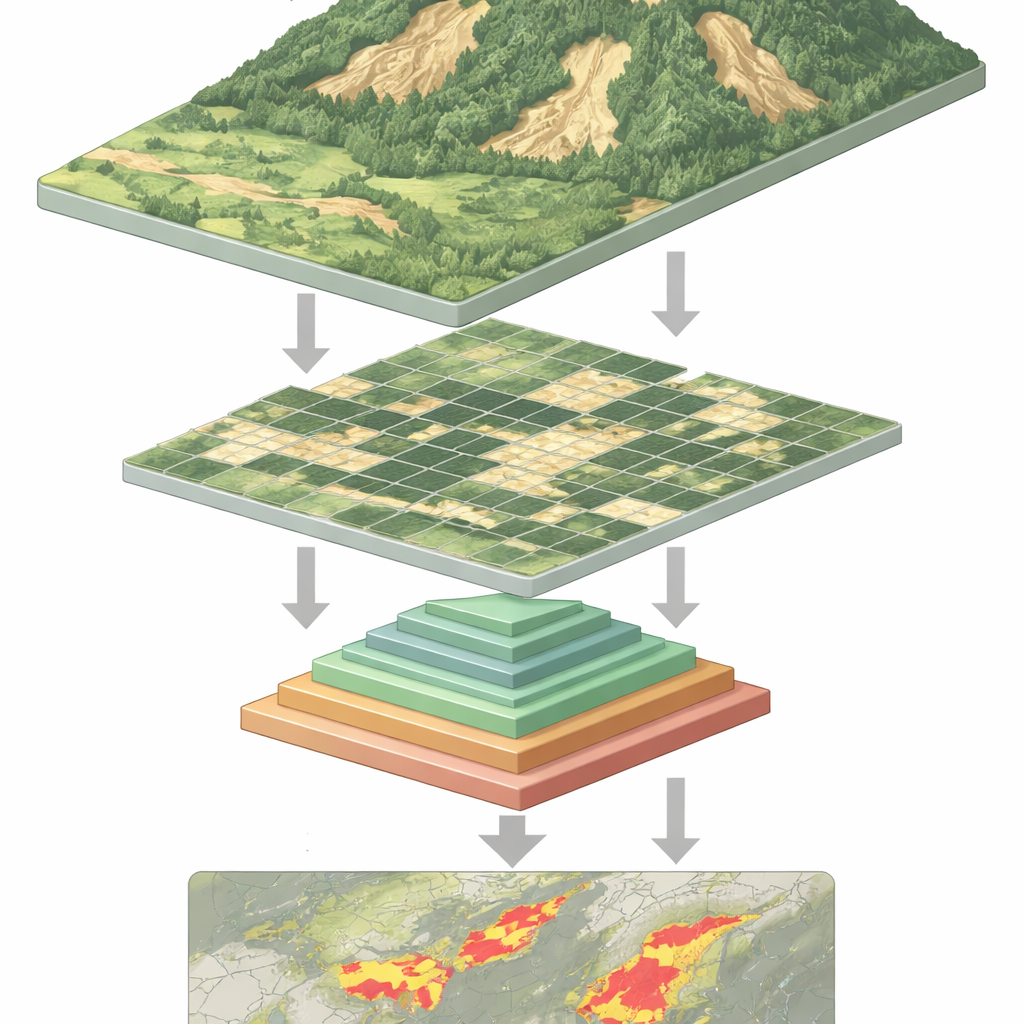
Por que Identificar Deslizamentos é Tão Difícil
Vista do espaço, um deslizamento recente pode parecer uma cicatriz pálida numa encosta verde—mas nem sempre. Deslizamentos variam muito em tamanho e forma, podem ficar parcialmente ocultos por árvores ou sombras e frequentemente assemelham-se a solo exposto de agricultura ou construção. Programas tradicionais, e até muitos sistemas de deep learning, têm dificuldade em lidar com essa variedade. Redes neurais convolucionais, os antigos pilares do reconhecimento de imagens, são boas em padrões locais mas podem deixar passar o contexto mais amplo de uma encosta. Modelos mais recentes, os “vision transformers”, conseguem captar esse contexto amplo, porém pagam um preço: para analisar cada pequeno pedaço da imagem, precisam manipular sequências de dados muito longas, o que exige grande potência computacional e os torna mais lentos.
Ensinando Máquinas a Ver em Várias Escalas
O estudo aborda esse gargalo ao combinar vision transformers com uma ideia engenhosa de trabalhos anteriores em processamento de imagens, chamada pooling em pirâmide. A percepção-chave é que uma cena deve ser entendida em várias escalas ao mesmo tempo: detalhes minúsculos como fissuras ou campos de detritos, características médias como uma encosta que deslizou, e padrões amplos como a inclinação geral e o entorno. Em vez de reduzir a imagem com um único passo de pooling, o novo modelo realiza várias operações de pooling em escalas diferentes dentro do próprio transformador. Essas versões pooled são empilhadas como camadas de uma pirâmide e então alimentadas ao mecanismo de atenção do modelo, que decide quais partes da imagem devem influenciar umas às outras.
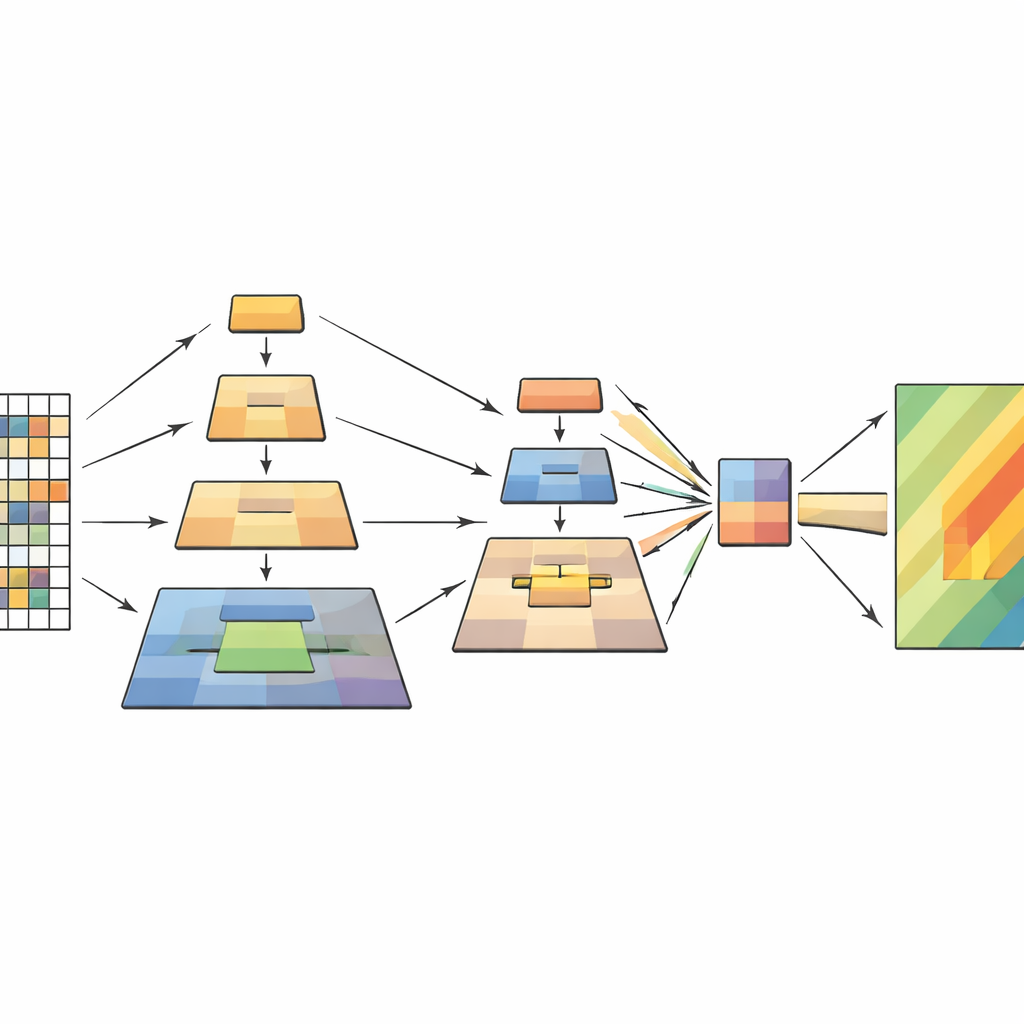
Como o Novo Modelo Funciona Internamente
A rede processa cada imagem de sensoriamento remoto em quatro etapas. Primeiro, corta a imagem em pequenos patches e os transforma numa grade de tokens. À medida que os dados avançam, patches próximos são agrupados e sua resolução espacial diminui gradualmente, formando uma hierarquia de mapas de características. Dentro de cada estágio, o módulo de pooling em pirâmide multilayer cria múltiplas visões reduzidas dessas características e as combina em uma sequência mais curta e enriquecida. O mecanismo de atenção então usa a imagem original como consulta—as partes que perguntam “o que importa aqui?”—e as visões pooled como chaves e valores—o contexto destilado que responde. Blocos convolucionais adicionais e leves preservam a noção de estrutura bidimensional, ajudando o modelo a manter sensibilidade a formas, bordas e texturas que caracterizam deslizamentos.
Colocando o Método à Prova
Para avaliar o desempenho desse projeto, os autores o treinaram e testaram em um grande conjunto público de dados de deslizamentos compilado pela Academia Chinesa de Ciências. Essa coleção inclui mais de vinte mil imagens de satélite e drone, cobrindo diversas regiões, terrenos e condições de imagem. O novo modelo foi comparado com fortes concorrentes, desde redes clássicas como U-Net e DeepLab até sistemas modernos baseados em transformers, como o Swin Transformer, e um detector leve recente de deslizamentos chamado BisDeNet. Em uma série de métricas padrão—precisão, recall, F1-score, intersection-over-union e acurácia geral—o transformador com pooling em pirâmide multilayer se saiu consistentemente melhor, aumentando o F1-score em 7,3 pontos percentuais e a acurácia geral em 2 pontos percentuais em relação às alternativas líderes.
Dos Números às Paisagens Reais
Além das pontuações, os pesquisadores inspecionaram visualmente as previsões do modelo. Verificaram que ele tende a se concentrar em quebras de encosta, cicatrizes alongadas e texturas de superfície mistas típicas de trajetórias de deslizamento. Os erros ocorrem principalmente onde a própria imagem é ambígua—como margens de rios, solo exposto ou pequenos deslizamentos com contornos tênues—em vez de provirem de falhas sistemáticas evidentes. Testes em vários conjuntos de dados adicionais de locais como Nepal, Bijie e Tangjiashan mostram que o método se adapta razoavelmente bem a diferentes paisagens, sugerindo que captura assinaturas gerais de deslizamentos em vez de peculiaridades de uma única região.
O Que Isso Significa para Encostas Mais Seguras
Em termos simples, o artigo mostra como fazer um tipo poderoso de IA “olhar” para encostas de forma mais eficiente e inteligente. Ao permitir que o modelo agrupe informação em várias escalas dentro de seu mecanismo central de atenção, reduz-se a carga computacional mantendo-se tanto o panorama quanto os detalhes finos necessários para delinear deslizamentos. O resultado é uma ferramenta mais rápida e precisa para transformar fluxos de imagens de satélite e drone em mapas de solo instável. Tais mapas podem apoiar avaliações de danos pós-desastre, monitoramento de risco a longo prazo e detecção de mudanças, oferecendo a planejadores e gestores de emergência uma visão mais clara de onde a terra já se moveu—e onde pode mover-se a seguir.
Citação: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Palavras-chave: detecção de deslizamentos, sensoriamento remoto, vision transformers, pooling em pirâmide, segmentação semântica