Clear Sky Science · he
בריכה פירמידלית רב-שכבתית ותשומת-לב עצמית לזיהוי מפולות קרקע באמצעות טרנספורמרים חזותיים
צופים במדרונות מהחלל
מפולות קרקע יכולות לקרות בבת-אחת, להרוס בתים, לחסום דרכים ולסכן חיי אדם. ברחבי העולם מדענים מסתמכים כיום על לוויינים וכלי טיס בלתי מאוישים כדי לעקוב אחרי מדרונות לא יציבים ממעל, אך הפיכת מיליוני פיקסלים לאמצעי התרעה מהימנים היא אתגר עצום. מאמר זה מציג גישה חדשה של אינטליגנציה מלאכותית שקוראת תמונות חישה מרחוק ביעילות ודיוק גבוהים יותר, ועוזרת למפות היכן הקרקע כבר הסליזה והיכן עדיין מסתתר הסכנה.
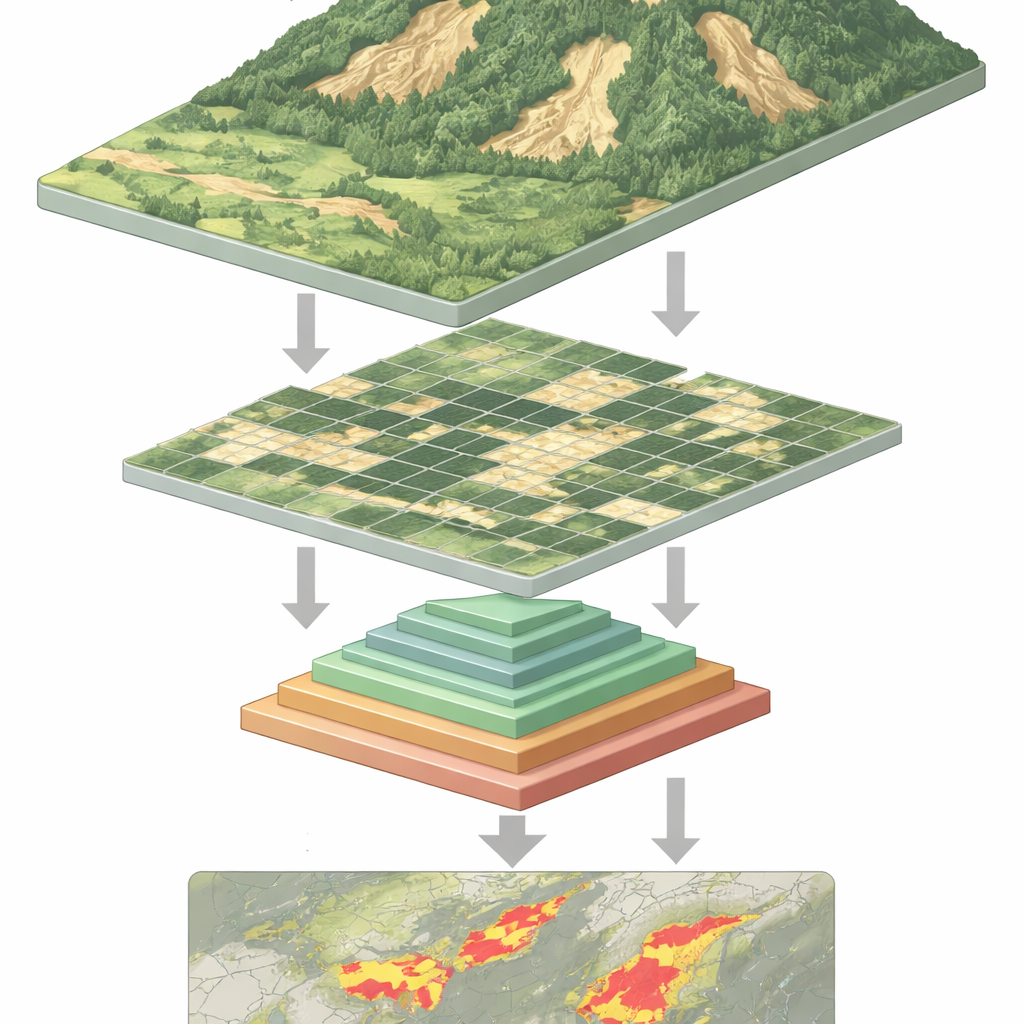
מדוע קשה לזהות מפולות קרקע
ממהחלל, מפולת טרייה עלולה להיראות כצלקת חיוורת על מדרון ירוק — אך לא תמיד. למפולות צורות וגדלים רבים, הן עלולות להיות חלקית מוסתרות על ידי עצים או צללים, ולעתים דומות לאדמה חשופה ממליכות חקלאיות או בנייה. תוכנות מסורתיות ואף מערכות למידה עמוקה רבות מתקשות להתמודד עם מגוון זה. רשתות קונבולוציה נוירוניות, שהיו עד כה כלי העבודה של זיהוי תמונה, טובות בזיהוי דפוסים מקומיים אך עלולות לפספס את ההקשר הרחב של המדרון. מודלים חדשים מסוג "טרנספורמר חזותי" יכולים לקלוט הקשר רחב יותר, אך זה עולה בכבדות: על מנת לנתח כל טלאי קטן בתמונה הם חייבים לטפל ברצפי נתונים ארוכים מאוד, מה שדורש כוח חישוב גבוה ומאט אותם.
להורות למכונות לראות בכמה סולמות
המחקר מתמודד עם צוואר הבקבוק הזה על ידי בנייה על טרנספורמרים חזותיים ובחירה ברעיון מבריק מעבודות עיבוד תמונה קודמות שנקרא בריכת פירמידה. התובנה המרכזית היא שיש להבין סצנה בכמה סולמות בו־זמנית: פרטים זעירים כמו סדקים או שדות פסולת, מאפיינים בגודל בינוני כמו המדרון שזחל, ודפוסים רחבים כמו השיפוע והסביבה הכללית. במקום לכווץ את התמונה בצעד בריכה יחיד, הדגם החדש מבצע מספר פעולות בריכה ברמות שונות בתוך הטרנספורמר עצמו. הגרסאות המנוקזות הללו נערמות כשכבות של פירמידה ואז מוזנות למנגנון התשומת-לב של המודל, שמחליט אילו חלקים בתמונה צריכים להשפיע זה על זה.
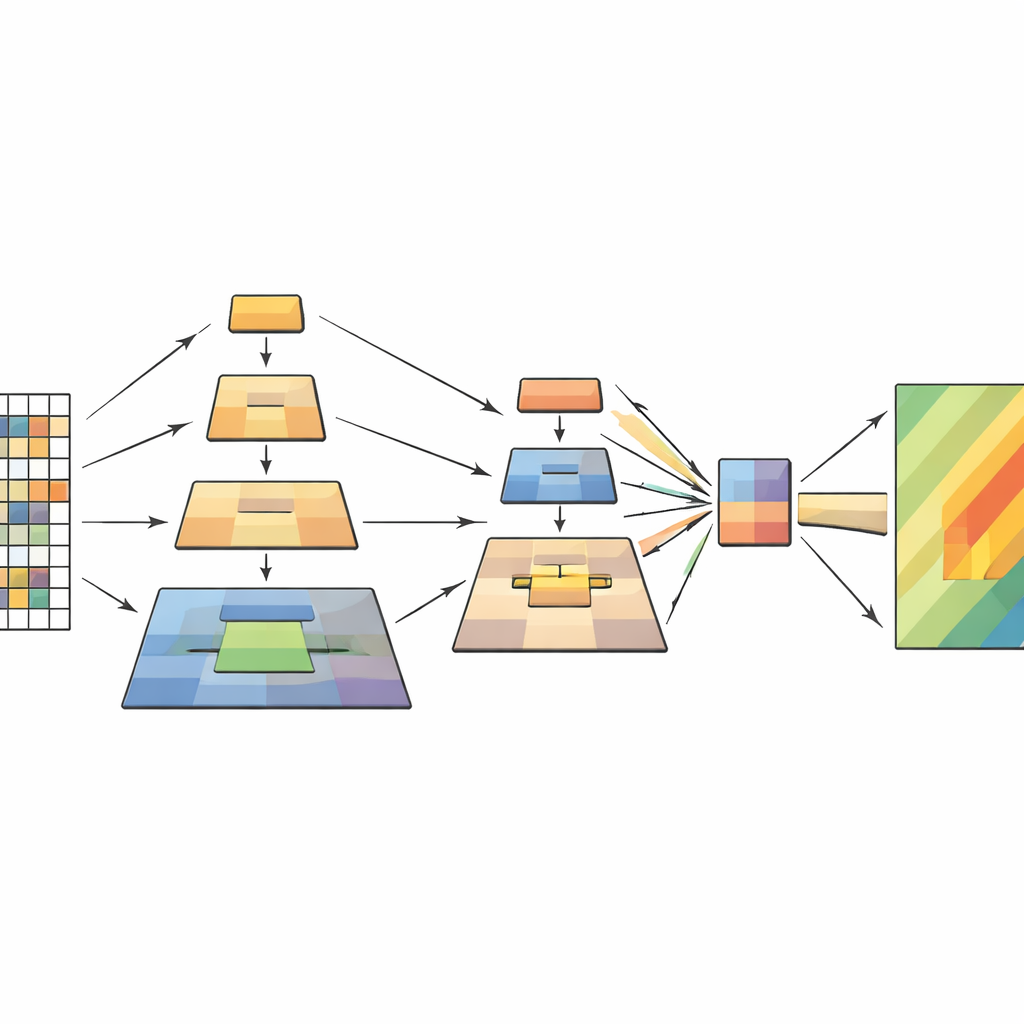
איך הדגם החדש פועל מבפנים
הרשת מעבדת כל תמונת חישה מרחוק בארבעה שלבים. בראשית, היא חותכת את התמונה לטלאים קטנים והופכת אותם לרשת של טוקנים. ככל שהמידע זורם לעומק, טלאים סמוכים מקובצים ורזולוציית המרחב נמוכה בהדרגה, ויוצרת היררכיה של מפות תכונה. בתוך כל שלב, מודול בריכת הפירמידה הרב-שכבתי יוצר מספר תצפיות מצומקות של התכונות הללו ומשלב אותן לרצף קצר ועשיר יותר. מנגנון התשומת-לב משתמש אז בתמונה המקורית כשאלה — החלקים ששואלים "מה חשוב כאן?" — ובגרסאות המנוקזות כמפתחות וערכים — ההקשר הממוקצן שמספק תשובות. בלוקי קונבולוציה קלים נוספים שומרים על תחושת המבנה הדו-ממדית, ועוזרים למודל להישאר רגיש לצורות, קצוות ומרקמים שמאפיינים מפולות קרקע.
בחינת השיטה במבחן
כדי לבדוק עד כמה העיצוב הזה עובד, המחברים אימנו ובדקו אותו על סט נתונים ציבורי גדול של מפולות קרקע שאספה האקדמיה הסינית למדעים. אוסף זה כולל יותר מעשרים אלף תמונות מלוויינים ומרחפנים, המכסה אזורים, תצורות קרקע ותנאי דימות רבים. הדגם החדש הושווה מול מתחרים חזקים, מרשתות קלאסיות כמו U-Net ו-DeepLab ועד מערכות מודרניות מבוססות טרנספורמר כמו Swin Transformer וגלאי מפולות קל משקל חדש בשם BisDeNet. על פני סט של מדדים סטנדרטיים — דיוק (precision), זיכרון (recall), מדד F1, חפיפה-על-חיתוך (IoU) ודיוק כולל — טרנספורמר בריכת הפירמידה הרב-שכבתי הצטיין בעקביות, ושיפר את מדד F1 ב-7.3 נקודות אחוז ואת הדיוק הכולל ב-2 נקודות אחוז בהשוואה לאלטרנטיבות המובילות.
ממספרים לנופים אמיתיים
מעבר לציונים גולמיים, החוקרים בחנו ויזואלית את התחזיות של המודל. הם מצאו שהוא נוטה להתרכז בשברים במדרון, בצלקות מוארכות ובמרקמים מעורבים של משטח האופייניים לנתיבי מפולות. הטעויות מתרחשות בעיקר במקומות שבהם התמונה עצמה עמומה — כמו גדות נהר, אדמה חשופה או מפולות קטנות עם קווי מתאר חלשים — ולא משגיאות מערכתיות ברורות. ניסויים על מספר מערכי נתונים נוספים ממקומות כמו נפאל, ביג'יה וטאנגג'שאן מראים שהשיטה מותאמת באופן סביר לנופים שונים, ורומזת שהיא לוכדת חתימות כלליות של מפולות יותר מאשר מאפיינים ייחודיים לאזור אחד.
מה משמעות הדבר עבור מדרונות בטוחים יותר
במלים פשוטות, המאמר מראה כיצד לגרום לסוג חזק של בינה מלאכותית "לראות" מדרונות ביעילות ובחוכמה רבה יותר. על ידי כך שהמודל מאפשר בריכת מידע בכמה סולמות בתוך מנגנון התשומת-לב הראשי שלו, הוא מצמצם את הנטל החישובי תוך שמירה על התמונה הרחבה והפרטים הדקים הדרושים כדי לתאר מפולות קרקע. התוצאה היא כלי מהיר ומדויק יותר להמרת זרמי תמונות מלוויין ומרחפן למפות של קרקע לא יציבה. מפות כאלה יכולות לתמוך בהערכת נזקים לאחר אסון, במעקב ארוך-טווח אחר סיכונים וגילוי שינויים, ולתת למתכננים ולמנהלי חירום תמונה ברורה יותר של היכן האדמה כבר זזה — והיכן היא עלולה לזוז בהמשך.
ציטוט: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
מילות מפתח: זיהוי מפולות קרקע, חישה מרחוק, טרנספורמרים חזותיים, בריכת פירמידה, קטוע סמנטי