Clear Sky Science · es
Auto-atención con pirámide de muestreo multinivel para la detección de deslizamientos mediante vision transformers
Vigilando laderas desde el espacio
Los deslizamientos pueden ocurrir con poca advertencia, destruyendo viviendas, bloqueando carreteras y poniendo vidas en peligro. En todo el mundo, los científicos ahora cuentan con satélites y drones para vigilar las pendientes inestables desde arriba, pero convertir millones de píxeles en avisos fiables es un gran desafío. Este artículo presenta un nuevo enfoque de inteligencia artificial que interpreta las imágenes de teledetección con mayor eficiencia y precisión, ayudando a cartografiar dónde el terreno ya se ha deslizado y dónde aún acecha el peligro.
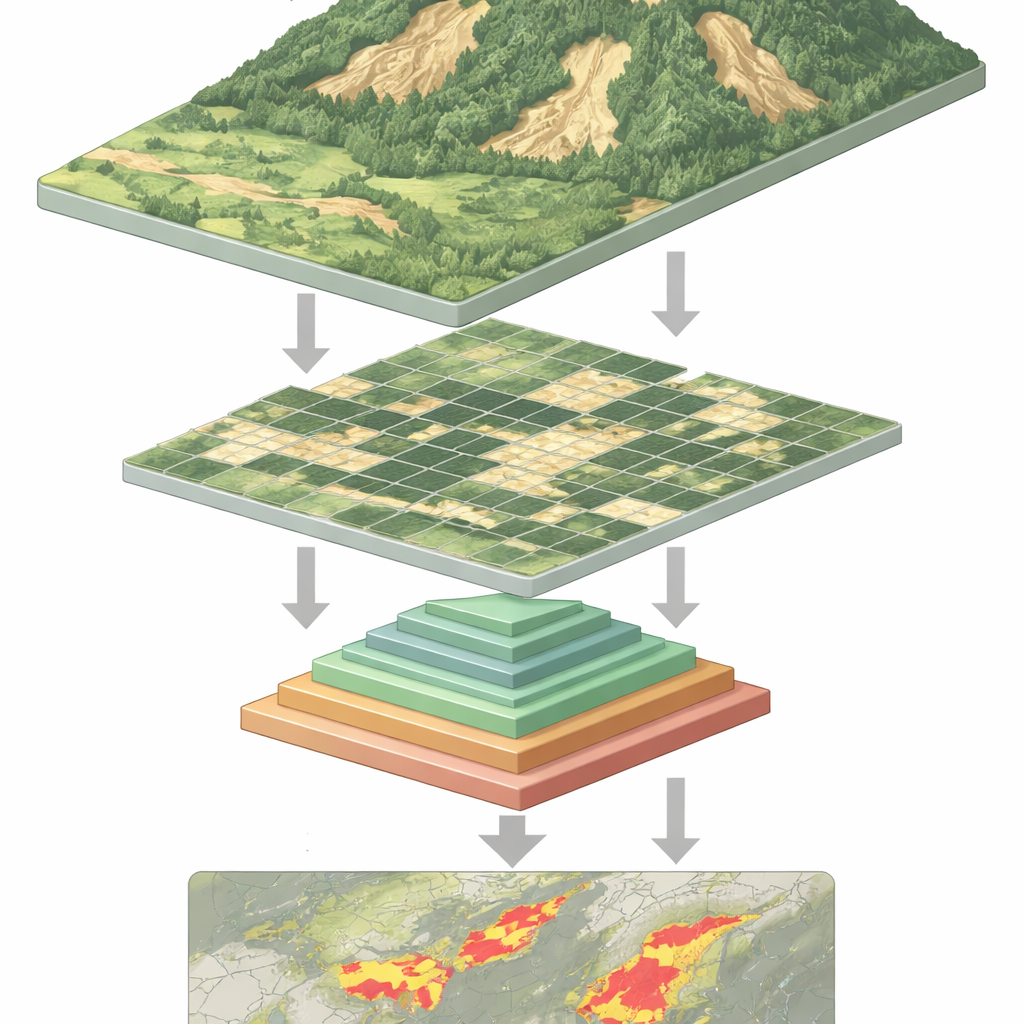
Por qué es tan difícil detectar deslizamientos
Desde el espacio, un deslizamiento reciente puede parecer una cicatriz pálida en una ladera verde, pero no siempre. Los deslizamientos varían mucho en tamaño y forma, pueden quedar parcialmente ocultos por árboles o sombras y con frecuencia se parecen a suelo descubierto por agricultura o construcción. Los programas informáticos tradicionales, e incluso muchos sistemas de aprendizaje profundo, luchan por manejar esta variedad. Las redes neuronales convolucionales, los antiguos caballos de batalla del reconocimiento de imágenes, son buenas para patrones locales pero pueden pasar por alto el contexto más amplio de una ladera. Los modelos más recientes de “vision transformer” pueden captar ese contexto amplio, pero pagan un precio: para analizar cada parche pequeño de una imagen deben manejar secuencias de datos muy largas, lo que exige mucha potencia de cálculo y los ralentiza.
Enseñar a las máquinas a ver a múltiples escalas
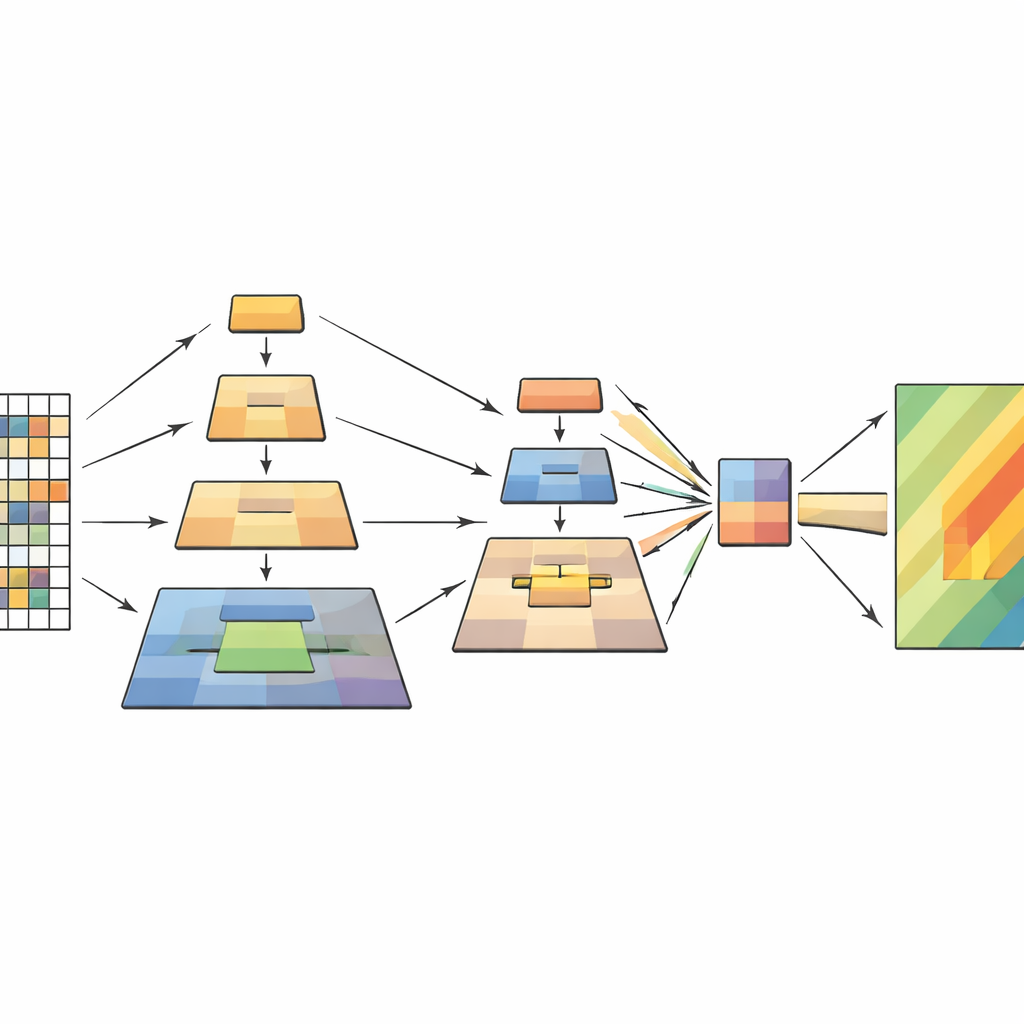
El estudio aborda este cuello de botella apoyándose en vision transformers y tomando prestada una idea eficaz de trabajos previos en procesamiento de imágenes llamada pirámide de muestreo. La idea clave es que una escena debe comprenderse a varias escalas a la vez: detalles minúsculos como grietas o campos de escombros, características medias como una ladera deslizante y patrones amplios como la pendiente y su entorno. En lugar de reducir la imagen con un único paso de muestreo, el nuevo modelo realiza varias operaciones de muestreo a diferentes escalas dentro del propio transformer. Estas versiones muestreadas se apilan como capas de una pirámide y luego se alimentan al mecanismo de atención del modelo, que decide qué partes de la imagen deben influirse mutuamente.
Cómo funciona el nuevo modelo por dentro
La red procesa cada imagen de teledetección en cuatro etapas. Primero, divide la imagen en pequeños parches y los transforma en una rejilla de tokens. A medida que los datos avanzan, los parches próximos se agrupan y su resolución espacial disminuye gradualmente, formando una jerarquía de mapas de características. Dentro de cada etapa, el módulo de pirámide de muestreo multinivel crea múltiples vistas a menor escala de estas características y las combina en una secuencia más corta y más rica. El mecanismo de atención utiliza entonces la imagen original como consulta—las partes que preguntan “¿qué importa aquí?”—y las vistas muestreadas como claves y valores—el contexto destilado que responde. Bloques convolucionales adicionales y ligeros preservan la sensación de estructura bidimensional, ayudando al modelo a mantenerse sensible a formas, bordes y texturas que señalan deslizamientos.
Poner el método a prueba
Para evaluar la eficacia del diseño, los autores lo entrenaron y probaron con un gran conjunto público de deslizamientos reunido por la Academia China de Ciencias. Esta colección incluye más de veinte mil imágenes procedentes de satélites y drones, que abarcan muchas regiones, terrenos y condiciones de captura. El nuevo modelo se comparó con competidores sólidos, desde redes clásicas U-Net y DeepLab hasta sistemas modernos basados en transformers como Swin Transformer y un detector de deslizamientos ligero reciente llamado BisDeNet. En una batería de métricas estándar—precisión, sensibilidad, F1, intersección sobre unión y exactitud global—el transformer con pirámide de muestreo multinivel resultó consistentemente superior, aumentando la F1 en 7,3 puntos porcentuales y la exactitud global en 2 puntos porcentuales frente a las mejores alternativas.
De los números a paisajes reales
Más allá de las puntuaciones crudas, los investigadores inspeccionaron visualmente las predicciones del modelo. Hallaron que tiende a concentrarse en rupturas de pendiente, cicatrices alargadas y texturas superficiales mixtas típicas de las trayectorias de deslizamiento. Los fallos ocurren principalmente donde la propia imagen es ambigua—como riberas, suelos expuestos o deslizamientos pequeños con contornos tenues—más que por errores sistemáticos evidentes. Pruebas en varios conjuntos adicionales procedentes de lugares como Nepal, Bijie y Tangjiashan muestran que el método se adapta razonablemente bien a distintos paisajes, lo que sugiere que captura firmas generales de deslizamientos y no solo particularidades de una única región.
Qué significa esto para laderas más seguras
En términos sencillos, el artículo demuestra cómo hacer que un tipo potente de IA “mire” las laderas de forma más eficiente e inteligente. Al permitir que el modelo muestree información a varias escalas dentro de su mecanismo central de atención, reduce la carga computacional al tiempo que conserva la visión de conjunto y los detalles finos necesarios para delimitar deslizamientos. El resultado es una herramienta más rápida y precisa para convertir flujos de imágenes satelitales y de drones en mapas de terreno inestable. Tales mapas pueden respaldar evaluaciones de daños postdesastre, vigilancia de riesgos a largo plazo y detección de cambios, ofreciendo a planificadores y gestores de emergencias una visión más clara de dónde ya se ha movido la tierra—y de dónde podría moverse a continuación.
Cita: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Palabras clave: detección de deslizamientos, teledetección, vision transformers, pirámide de muestreo, segmentación semántica