Clear Sky Science · it
Pooling piramidale multilivello con self-attention per il rilevamento di frane usando vision transformer
Osservare i pendii dallo spazio
Le frane possono colpire con poco preavviso, distruggendo case, bloccando strade e mettendo in pericolo vite umane. In tutto il mondo gli scienziati si affidano oggi a satelliti e droni per sorvegliare le pendici instabili dall’alto, ma trasformare milioni di pixel in avvisi affidabili è una sfida enorme. Questo articolo presenta un nuovo approccio di intelligenza artificiale che legge le immagini di telerilevamento in modo più efficiente e accurato, aiutando a mappare dove il terreno è già scivolato e dove il pericolo è ancora presente.
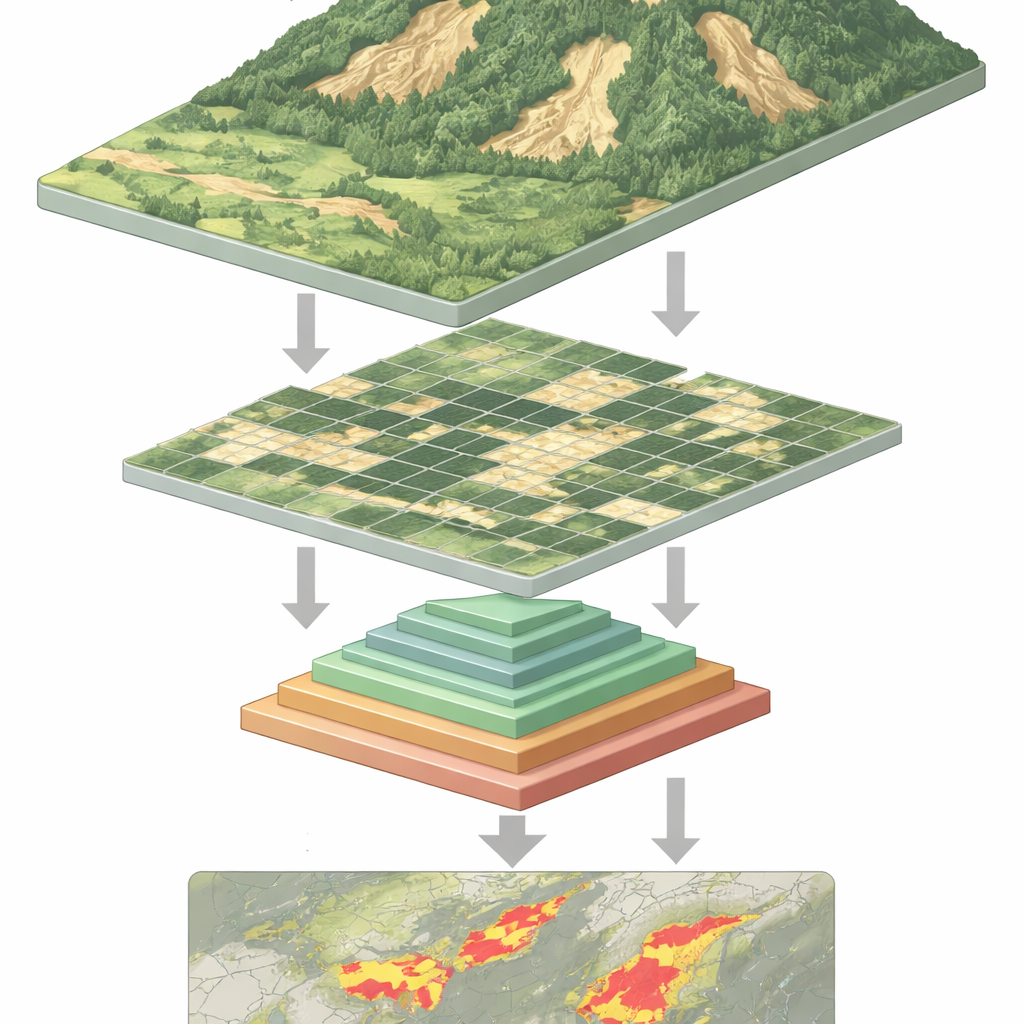
Perché individuare le frane è così difficile
Visto dallo spazio, una frana recente può apparire come una cicatrice chiara su un pendio verde—ma non sempre. Le frane assumono molte dimensioni e forme, possono essere parzialmente nascoste da alberi o ombre e spesso somigliano a terreno nudo dovuto ad attività agricole o edilizie. I programmi tradizionali e persino molti sistemi di deep learning faticano a gestire questa varietà. Le reti neurali convoluzionali, i precedenti cavalli di battaglia del riconoscimento di immagini, sono efficaci sui pattern locali ma possono perdere il contesto più ampio di un pendio. I modelli più recenti basati su vision transformer possono cogliere quel contesto esteso, ma a un prezzo: per analizzare ogni piccola porzione di immagine devono gestire sequenze di dati molto lunghe, il che richiede molta potenza di calcolo e li rallenta.
Insegnare alle macchine a vedere a molte scale
Lo studio affronta questo collo di bottiglia basandosi sui vision transformer e prendendo in prestito un’idea intelligente dal precedente lavoro di elaborazione delle immagini chiamata pooling piramidale. L’intuizione chiave è che una scena dovrebbe essere interpretata su più scale contemporaneamente: dettagli minuscoli come crepe o detriti, elementi medi come un versante scivolato e schemi ampi come la conformazione complessiva del pendio e l’ambiente circostante. Invece di ridurre l’immagine con un unico passaggio di pooling, il nuovo modello esegue diverse operazioni di pooling a scale differenti all’interno del trasformatore stesso. Queste versioni poolate sono impilate come strati di una piramide e poi alimentate nel meccanismo di attenzione del modello, che decide quali parti dell’immagine debbano influenzarsi a vicenda.
Come funziona il nuovo modello internamente
La rete elabora ogni immagine di telerilevamento in quattro fasi. Innanzitutto divide l’immagine in piccoli patch e li trasforma in una griglia di token. Man mano che i dati procedono in profondità, i patch vicini vengono raggruppati e la risoluzione spaziale diminuisce gradualmente, formando una gerarchia di mappe di caratteristiche. All’interno di ogni fase, il modulo di pooling piramidale multilivello crea più viste ridotte di queste feature e le combina in una sequenza più corta e più ricca. Il meccanismo di attenzione usa quindi l’immagine originale come query—le parti che chiedono “cosa è importante qui?”—e le viste poolate come key e value—il contesto distillato che risponde. Blocchi convoluzionali leggeri aggiuntivi preservano la percezione della struttura bidimensionale, aiutando il modello a restare sensibile a forme, bordi e texture che caratterizzano le frane.
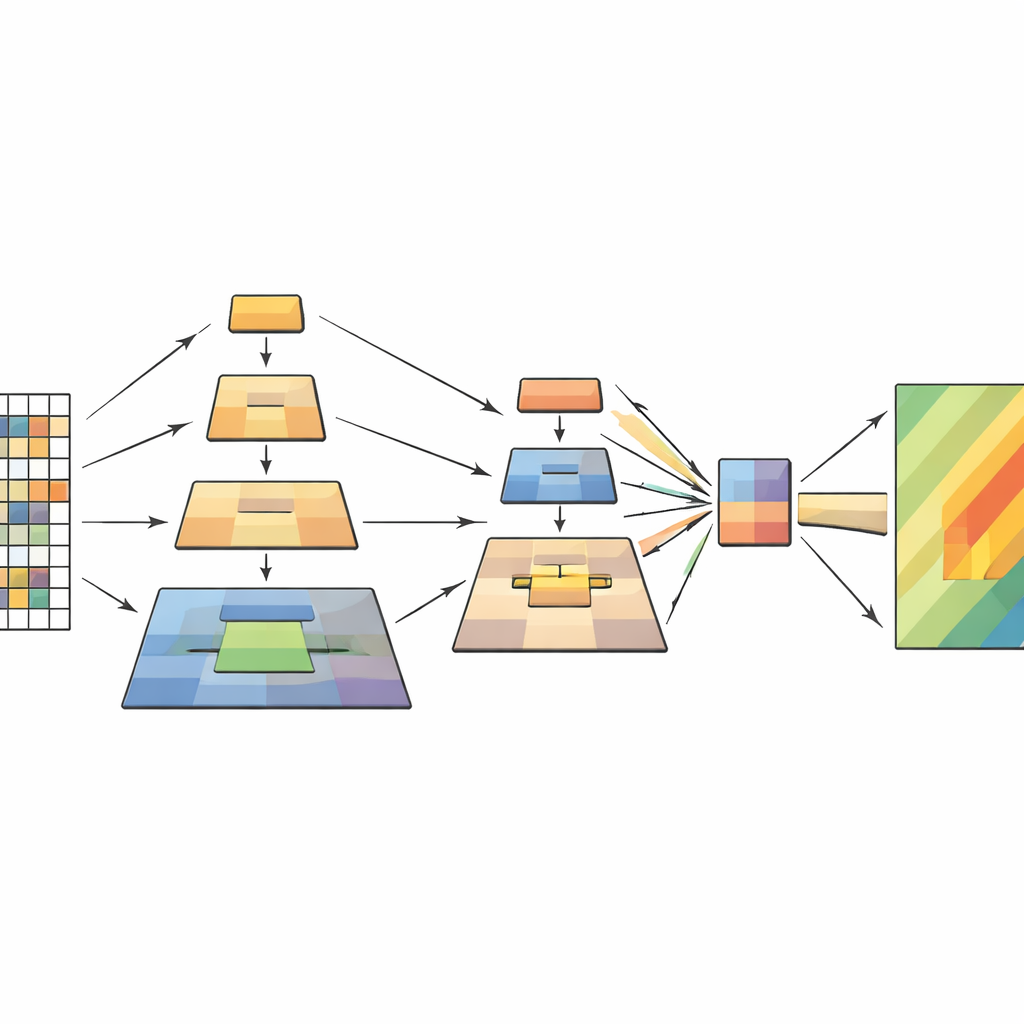
Mettere il metodo alla prova
Per valutare l’efficacia del progetto, gli autori lo hanno addestrato e testato su un ampio dataset pubblico di frane assemblato dall’Accademia Cinese delle Scienze. Questa raccolta include oltre ventimila immagini da satelliti e droni, coprendo molte regioni, terreni e condizioni di acquisizione. Il nuovo modello è stato confrontato con forti concorrenti, da reti classiche come U-Net e DeepLab fino a sistemi moderni basati su transformer come Swin Transformer e un recente rivelatore di frane leggero chiamato BisDeNet. Su una serie di metriche standard—precisione, richiamo, F1-score, intersection-over-union e accuratezza complessiva—il transformer con pooling piramidale multilivello si è costantemente posizionato al vertice, migliorando l’F1-score di 7,3 punti percentuali e l’accuratezza complessiva di 2 punti percentuali rispetto alle alternative di punta.
Dai numeri ai paesaggi reali
Oltre ai punteggi grezzi, i ricercatori hanno ispezionato visivamente le predizioni del modello. Hanno osservato che tende a concentrarsi su rotture del pendio, cicatrici allungate e texture superficiali miste tipiche dei percorsi delle frane. Gli errori si verificano principalmente dove l’immagine è essa stessa ambigua—come sponde fluviali, suoli esposti o piccole scivolate dai contorni deboli—invece che per evidenti errori sistematici. Test su diversi dataset aggiuntivi provenienti da luoghi come Nepal, Bijie e Tangjiashan mostrano che il metodo si adatta ragionevolmente bene a paesaggi differenti, suggerendo che cattura firme generali delle frane più che peculiarità di una singola regione.
Cosa significa questo per pendii più sicuri
In termini semplici, l’articolo mostra come far “guardare” un potente tipo di intelligenza artificiale ai pendii in modo più efficiente e intelligente. Consentendo al modello di poolare informazioni su più scale all’interno del suo nucleo di attenzione, si riduce l’onere computazionale mantenendo sia la visione d’insieme sia i dettagli fini necessari per delineare le frane. Il risultato è uno strumento più veloce e più accurato per trasformare flussi di immagini satellitari e da droni in mappe del terreno instabile. Tali mappe possono supportare valutazioni dei danni post-disastro, monitoraggio a lungo termine dei rischi e rilevamento dei cambiamenti, offrendo a pianificatori e gestori delle emergenze una visione più chiara di dove la terra si è già mossa—e dove potrebbe muoversi in futuro.
Citazione: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Parole chiave: rilevamento frane, telerilevamento, vision transformer, pooling piramidale, segmentazione semantica