Clear Sky Science · sv
Flerlagrig pyramidpoolning och självuppmärksamhet för skreddetektion med vision-transformers
Att bevaka sluttningar från rymden
Jordskred kan inträffa med liten varsel, förstöra hem, blockera vägar och äventyra liv. Runt om i världen förlitar sig forskare nu på satelliter och drönare för att övervaka instabila sluttningar från ovan, men att omvandla miljontals pixlar till tillförlitliga varningar är en stor utmaning. Den här artikeln presenterar en ny artificiell intelligensmetod som tolkar fjärranalysbilder mer effektivt och mer exakt, vilket hjälper till att kartlägga var marken redan har rört sig och var faran fortfarande lurar.
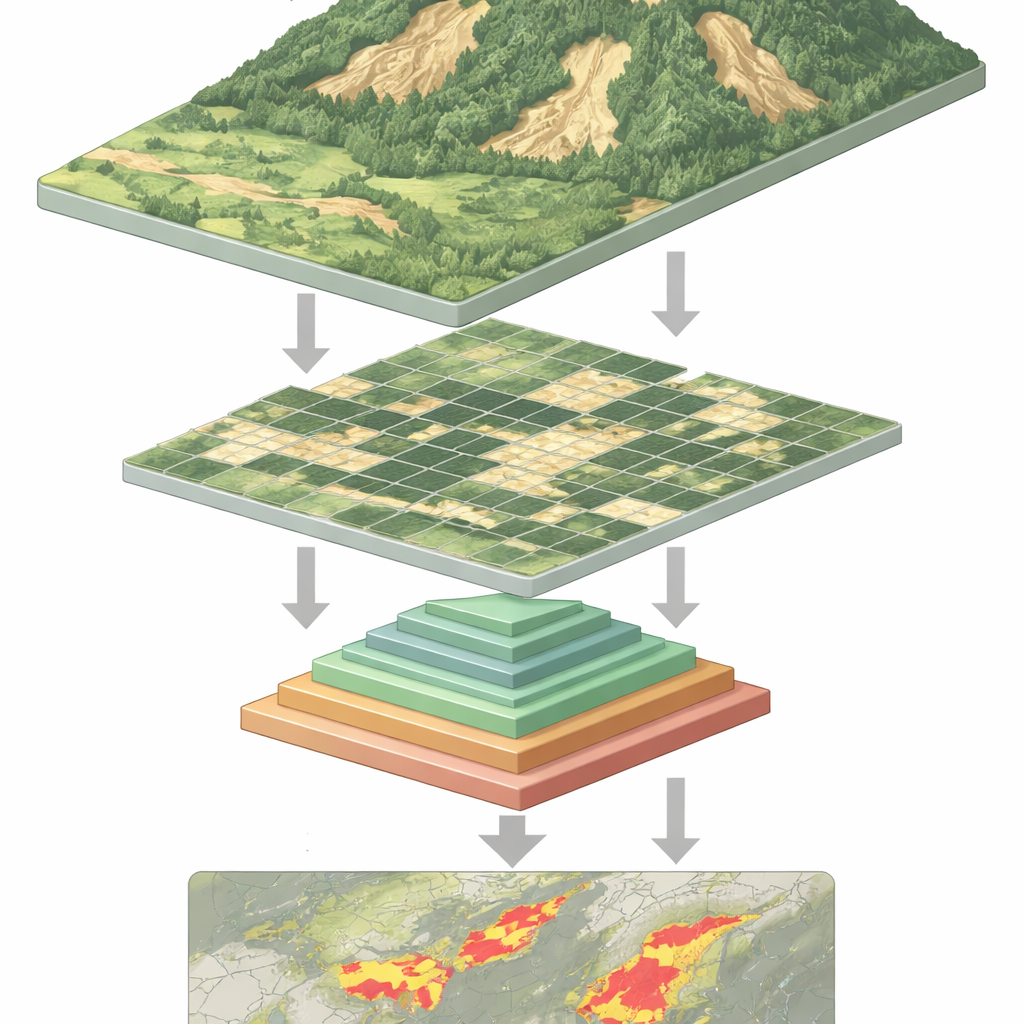
Varför det är svårt att upptäcka skred
Från rymden kan ett färskt skred se ut som ett ljusare ärr på en grön sluttning—men inte alltid. Skred förekommer i många storlekar och former, kan delvis döljas av träd eller skuggor och liknar ofta bar jord från jordbruk eller byggnation. Traditionella datorprogram, och även många djupinlärningssystem, har svårt att hantera denna variation. Konvolutionsnätverk, de tidigare arbetshästarna inom bildigenkänning, är bra på lokala mönster men kan missa sluttningens bredare sammanhang. Nyare "vision transformer"-modeller kan ta in detta vidare sammanhang, men det finns en kostnad: för att analysera varje liten bildruta måste de hantera mycket långa datasekvenser, vilket kräver stor beräkningskapacitet och gör dem långsammare.
Att lära maskiner att se i flera skalor
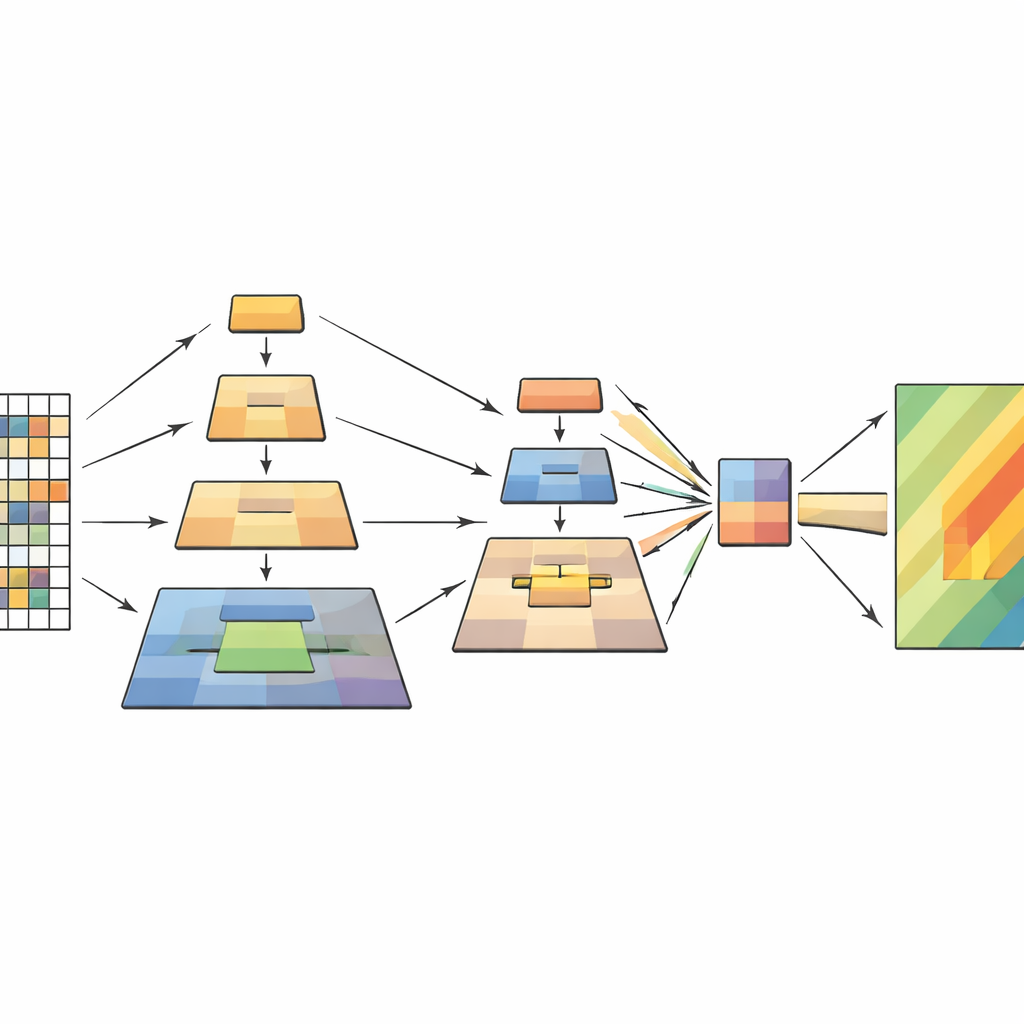
Studien angriper denna flaskhals genom att bygga vidare på vision-transformers samtidigt som den lånar en smart idé från tidigare bildbehandlingsarbete kallad pyramidpoolning. Den centrala insikten är att en scen bör förstås på flera skalor samtidigt: små detaljer som sprickor eller skräpfält, mellanstora strukturer som en rörlig sluttning, och breda mönster som den övergripande lutningen och omgivningen. Istället för att krympa bilden i ett enda poolningssteg utför den nya modellen flera poolningsoperationer i olika skalor inne i transformern. Dessa poolade versioner staplas som lager i en pyramid och matas sedan in i modellens uppmärksamhetsmekanism, som avgör vilka delar av bilden som bör påverka varandra.
Hur den nya modellen fungerar inuti
Nätverket bearbetar varje fjärranalysbild i fyra steg. Först delas bilden i små patchar och omvandlas till ett rutnät av tokens. När data flödar djupare grupperas intilliggande patchar och deras rumsliga upplösning minskar gradvis, vilket bildar en hierarki av feature-mappar. Inom varje steg skapar multilager-pyramidpoolningsmodulen flera nedskalade vyer av dessa features och kombinerar dem till en kortare, rikare sekvens. Uppmärksamhetsmekanismen använder sedan den ursprungliga bilden som sin query—de delar som frågar "vad är viktigt här?"—och de poolade vyerna som keys och values—det destillerade sammanhanget som svarar. Ytterligare lätta konvolutionsblock bevarar känslan av tvådimensionell struktur och hjälper modellen att vara känslig för former, kanter och texturer som kännetecknar skred.
Att testa metoden
För att se hur väl denna konstruktion fungerar tränade och testade författarna den på en stor, offentlig skreddatabas sammanställd av Chinese Academy of Sciences. Denna samling innehåller mer än tjugotusen bilder från satelliter och drönare och täcker många regioner, terränger och bildförhållanden. Den nya modellen jämfördes med starka konkurrenter, från klassiska U-Net och DeepLab-nätverk till moderna transformerbaserade system som Swin Transformer och en nyligen utvecklad lättviktsdetektor för skred kallad BisDeNet. Över en uppsättning standardmått—precision, recall, F1-poäng, intersection-over-union och total noggrannhet—kom den flerlagriga pyramidpoolnings-transformern konsekvent ut i topp, med en förbättring av F1-poängen med 7,3 procentenheter och total noggrannhet med 2 procentenheter jämfört med ledande alternativ.
Från siffror till verkliga landskap
Utöver råa poäng granskade forskarna modellens prediktioner visuellt. De fann att den tenderar att koncentrera sig på brutna sluttningar, avlånga ärr och blandade ytstrukturer typiska för skredbanor. Felsteg uppstår främst där bilden i sig är tvetydig—som flodbanker, exponerad jord eller små skred med svaga konturer—hellre än från uppenbara systematiska misstag. Tester på flera ytterligare dataset från platser som Nepal, Bijie och Tangjiashan visar att metoden anpassar sig relativt väl till olika landskap, vilket antyder att den fångar generella signaturer för skred snarare än särdrag hos ett enskilt område.
Vad detta betyder för säkrare sluttningar
Enkelt uttryckt visar artikeln hur man får en kraftfull typ av AI att "se" sluttningar mer effektivt och klokt. Genom att låta modellen poola information i flera skalor inne i sin kärna av uppmärksamhetsmekanism minskar den beräkningsbördan samtidigt som helhetsbilden och de fina detaljerna som behövs för att avgränsa skred bevaras. Resultatet är ett snabbare, mer precist verktyg för att omvandla strömmar av satellit- och drönarbilder till kartor över instabil mark. Sådana kartor kan stödja skadebedömningar efter katastrofer, långsiktig riskövervakning och förändringsdetektion, och ge planerare och räddningschefer en tydligare bild av var marken redan har rört sig—och var den kan röra sig nästa gång.
Citering: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Nyckelord: skreddetektion, fjärranalys, vision-transformers, pyramidpoolning, semantisk segmentering