Clear Sky Science · en
Multilayer pyramid pooling self-attention for landslide detection using vision transformers
Watching Hillsides from Space
Landslides can strike with little warning, destroying homes, blocking roads, and endangering lives. Around the world, scientists now rely on satellites and drones to watch unstable slopes from above, but turning millions of pixels into reliable warnings is a huge challenge. This article presents a new artificial intelligence approach that reads remote sensing images more efficiently and more accurately, helping map where the ground has already slipped and where danger still lurks.
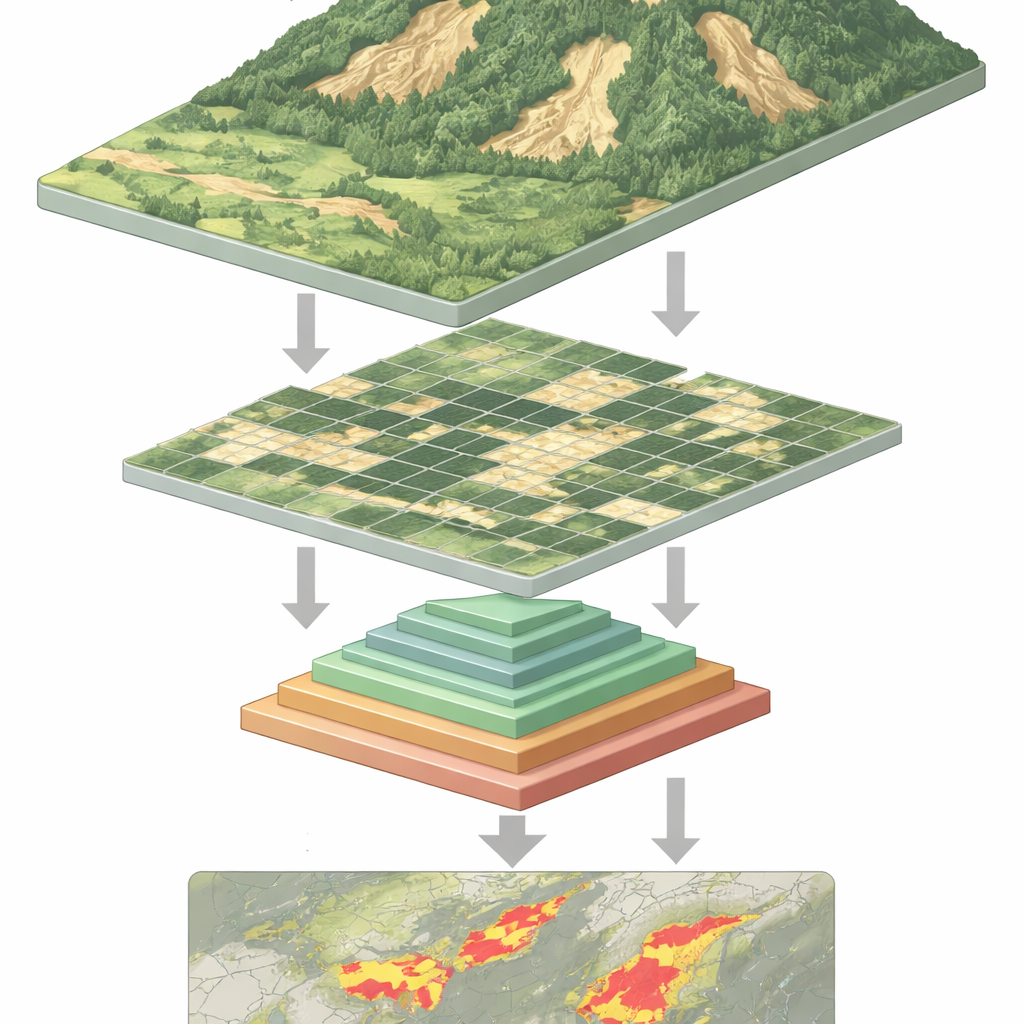
Why Spotting Landslides Is So Hard
From space, a fresh landslide may look like a pale scar on a green hillside—but not always. Landslides come in many sizes and shapes, can be partly hidden by trees or shadows, and often resemble bare soil from farming or construction. Traditional computer programs, and even many deep learning systems, struggle to cope with this variety. Convolutional neural networks, the earlier workhorses of image recognition, are good at local patterns but can miss the broader setting of a slope. Newer "vision transformer" models can take in that wider context, yet they pay a price: to analyze every small patch in an image, they must juggle very long data sequences, which demands heavy computing power and slows them down.
Teaching Machines to See at Many Scales
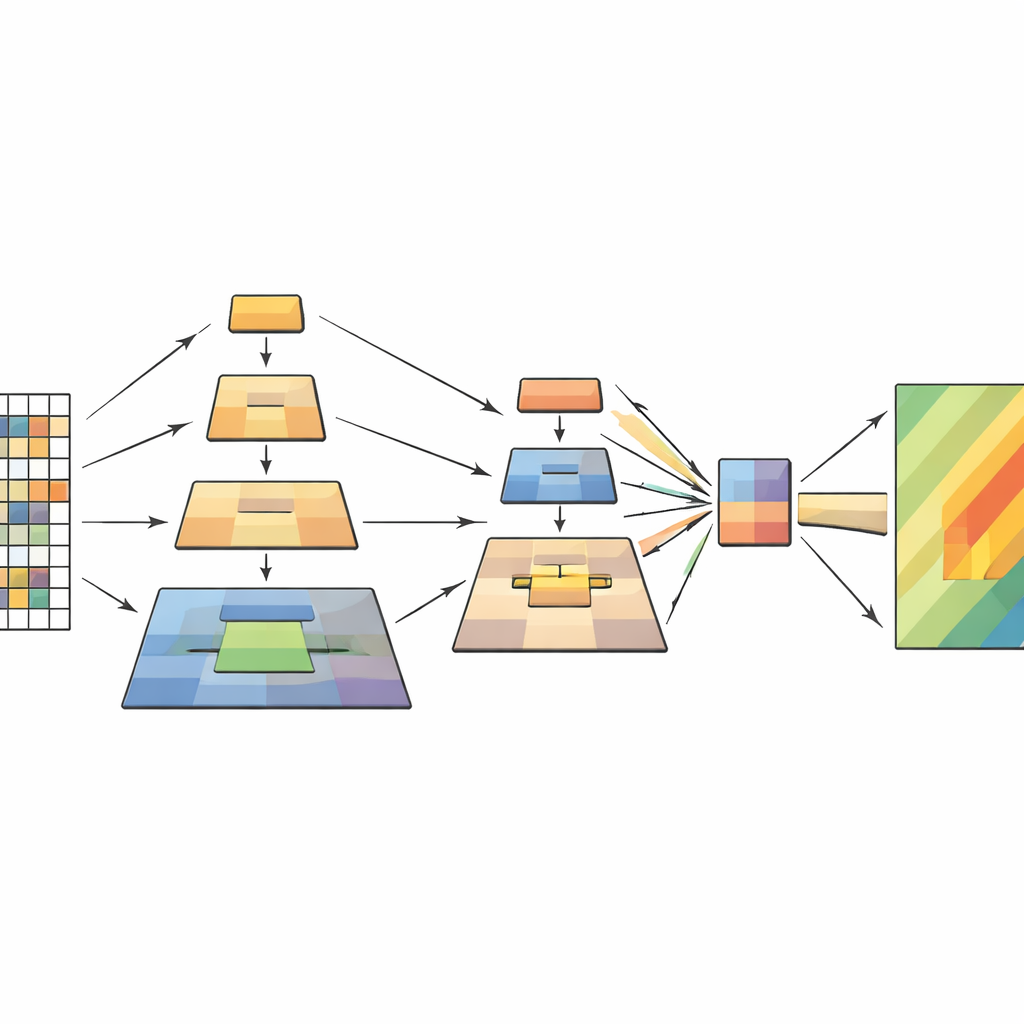
The study tackles this bottleneck by building on vision transformers while borrowing a clever idea from earlier image-processing work called pyramid pooling. The key insight is that a scene should be understood at several scales at once: tiny details like cracks or debris fields, medium features like a sliding hillside, and broad patterns like the overall slope and surroundings. Instead of shrinking the image with a single pooling step, the new model performs several pooling operations at different scales inside the transformer itself. These pooled versions are stacked like layers of a pyramid and then fed into the model’s attention mechanism, which decides which parts of the image should influence each other.
How the New Model Works Inside
The network processes each remote sensing image in four stages. First, it cuts the image into small patches and turns them into a grid of tokens. As the data flows deeper, nearby patches are grouped, and their spatial resolution gradually decreases, forming a hierarchy of feature maps. Within each stage, the multilayer pyramid pooling module creates multiple downscaled views of these features and combines them into a shorter, richer sequence. The attention mechanism then uses the original image as its query—the parts that ask "what matters here?"—and the pooled views as keys and values—the distilled context that answers. Additional lightweight convolution blocks preserve the sense of two-dimensional structure, helping the model stay sensitive to shapes, edges, and textures that mark landslides.
Putting the Method to the Test
To see how well this design works, the authors trained and tested it on a large, public landslide dataset assembled by the Chinese Academy of Sciences. This collection includes more than twenty thousand images from satellites and drones, covering many regions, terrains, and imaging conditions. The new model was compared against strong competitors, from classic U-Net and DeepLab networks to modern transformer-based systems such as Swin Transformer and a recent lightweight landslide detector called BisDeNet. Across a suite of standard yardsticks—precision, recall, F1-score, intersection-over-union, and overall accuracy—the multilayer pyramid pooling transformer consistently came out ahead, boosting F1-score by 7.3 percentage points and overall accuracy by 2 percentage points over leading alternatives.
From Numbers to Real Landscapes
Beyond raw scores, the researchers inspected the model’s predictions visually. They found that it tends to concentrate on slope breaks, elongated scars, and mixed surface textures typical of landslide paths. Missteps mainly occur where the imagery itself is ambiguous—such as riverbanks, exposed soil, or tiny slides with faint outlines—rather than from obvious systematic errors. Tests on several additional datasets from places like Nepal, Bijie, and Tangjiashan show that the method adapts reasonably well to different landscapes, hinting that it captures general signatures of landslides rather than quirks of a single region.
What This Means for Safer Slopes
In simple terms, the paper shows how to make a powerful type of AI "look" at hillsides more efficiently and more intelligently. By letting the model pool information at several scales inside its core attention mechanism, it reduces the computing burden while keeping the big picture and the fine details needed to outline landslides. The result is a faster, more accurate tool for turning streams of satellite and drone images into maps of unstable ground. Such maps can support post-disaster damage assessments, long-term hazard monitoring, and change detection, giving planners and emergency managers a clearer view of where the earth has already moved—and where it might move next.
Citation: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Keywords: landslide detection, remote sensing, vision transformers, pyramid pooling, semantic segmentation