Clear Sky Science · de
Mehrschichtige Pyramidensampling-Selbstaufmerksamkeit für Erdrutscherkennung mit Vision Transformers
Hänge aus dem All beobachten
Erdrutsche können mit wenig Vorwarnung auftreten, Häuser zerstören, Straßen blockieren und Menschen in Gefahr bringen. Weltweit stützen sich Forscher inzwischen auf Satelliten und Drohnen, um instabile Hänge aus der Luft zu überwachen. Aus Millionen von Pixeln verlässliche Warnungen zu gewinnen, ist jedoch eine enorme Herausforderung. Dieser Artikel stellt einen neuen Ansatz der künstlichen Intelligenz vor, der Fernerkundungsbilder effizienter und genauer ausliest und dabei hilft, Bereiche zu kartieren, in denen sich der Boden bereits bewegt hat, und wo noch Gefahr droht.
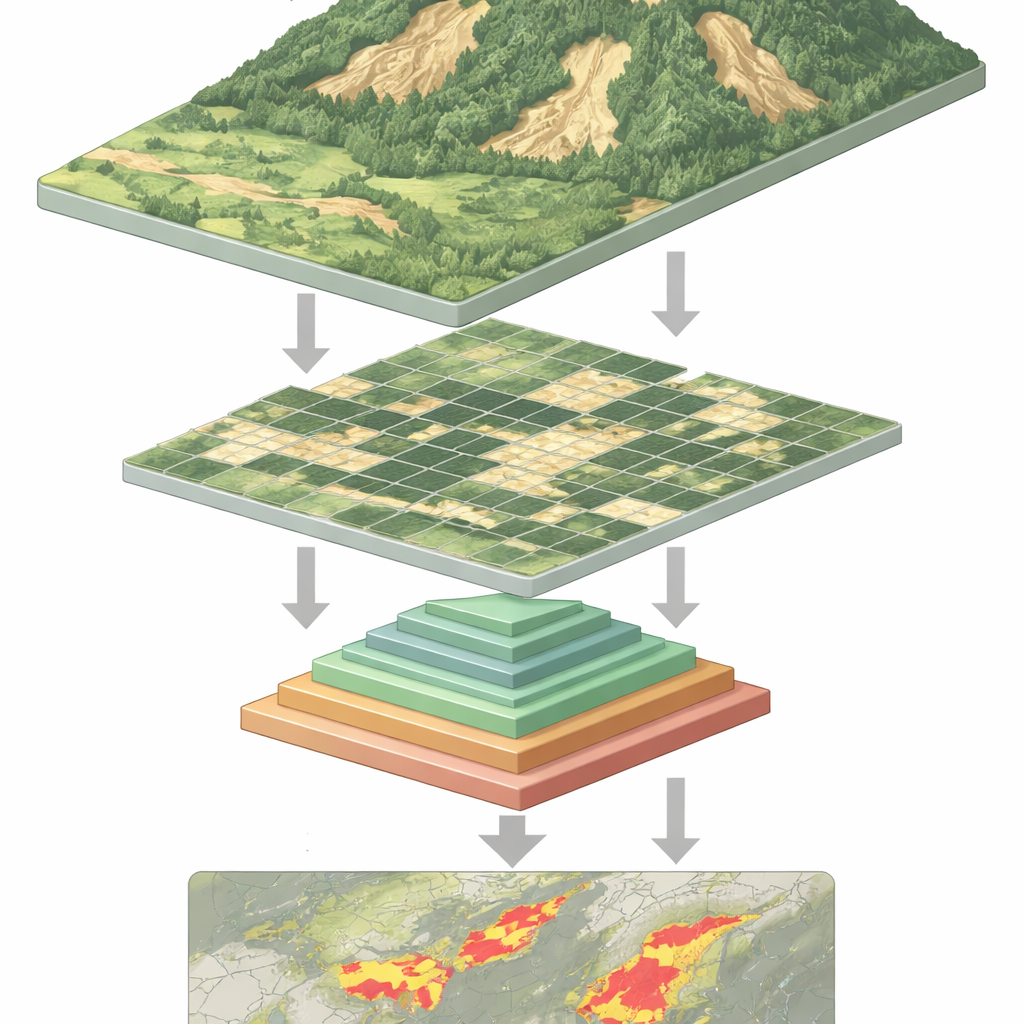
Warum Erdrutsche so schwer zu erkennen sind
Aus dem All kann ein frischer Erdrutsch wie eine blasse Narbe auf einem grünen Hang aussehen — aber nicht immer. Erdrutsche treten in vielen Größen und Formen auf, können teilweise von Bäumen oder Schatten verdeckt sein und ähneln oft auch unbedeckter Erde durch Landwirtschaft oder Bauarbeiten. Traditionelle Computerprogramme und viele Deep‑Learning‑Systeme haben Schwierigkeiten mit dieser Vielfalt. Konvolutionelle neuronale Netze, die früheren Arbeitspferde der Bilderkennung, erfassen lokale Muster gut, können aber das weitere Umfeld eines Hangs übersehen. Neuere Vision‑Transformer‑Modelle können diesen größeren Kontext aufnehmen, zahlen dafür jedoch einen Preis: Um jeden kleinen Bildausschnitt zu analysieren, müssen sie sehr lange Datenfolgen verarbeiten, was hohe Rechenkosten verursacht und sie verlangsamt.
Maschinen beibringen, in vielen Maßstäben zu sehen
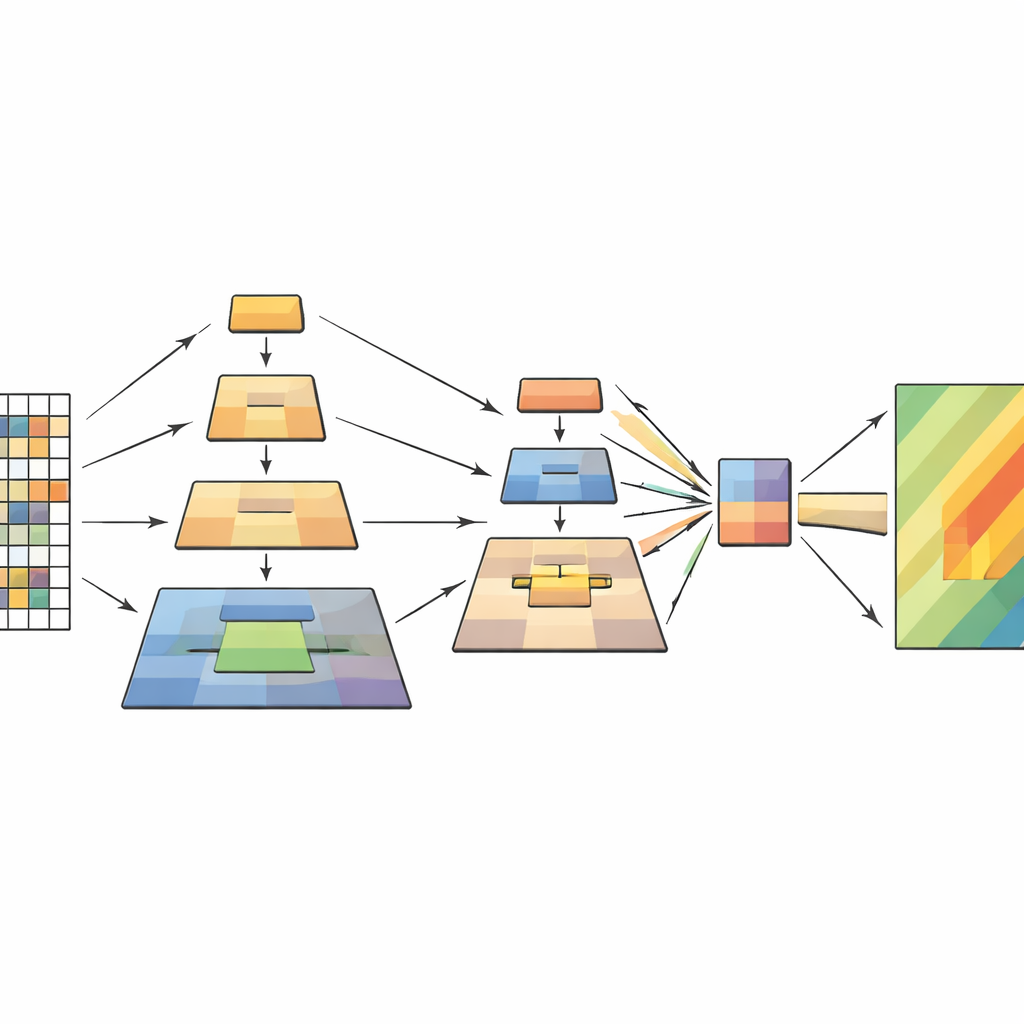
Die Studie adressiert dieses Nadelöhr, indem sie auf Vision Transformers aufbaut und eine clevere Idee aus früheren Bildverarbeitungsarbeiten übernimmt: das Pyramidensampling. Die zentrale Erkenntnis ist, dass eine Szene gleichzeitig auf mehreren Skalen verstanden werden sollte: winzige Details wie Risse oder Trümmerfelder, mittlere Strukturen wie ein abrutschender Hang und große Muster wie das Gelände und die Umgebung insgesamt. Statt das Bild mit einem einzigen Pooling‑Schritt zu verkleinern, führt das neue Modell innerhalb des Transformers mehrere Pooling‑Operationen auf unterschiedlichen Skalen durch. Diese gepoolten Versionen werden schichtweise wie eine Pyramide gestapelt und dann in den Aufmerksamkeitsmechanismus des Modells eingespeist, der entscheidet, welche Bildteile sich gegenseitig beeinflussen sollten.
Wie das neue Modell innen funktioniert
Das Netz verarbeitet jedes Fernerkundungsbild in vier Stufen. Zuerst wird das Bild in kleine Patches zerteilt und in ein Raster von Tokens umgewandelt. Mit zunehmender Tiefe werden benachbarte Patches zusammengefasst und ihre räumliche Auflösung nimmt allmählich ab, wodurch eine Hierarchie von Merkmalskarten entsteht. Innerhalb jeder Stufe erzeugt das mehrschichtige Pyramidensampling‑Modul mehrere verkleinerte Ansichten dieser Merkmale und kombiniert sie zu einer kürzeren, inhaltlich dichteren Sequenz. Der Aufmerksamkeitsmechanismus verwendet dann das Originalbild als Query — also die Teile, die fragen „Was ist hier wichtig?“ — und die gepoolten Ansichten als Key und Value — den konzentrierten Kontext, der antwortet. Zusätzliche leichte Konvolutionsblöcke bewahren dabei die zweidimensionale Struktur und helfen dem Modell, für Formen, Kanten und Texturen sensibel zu bleiben, die für Erdrutsche charakteristisch sind.
Den Ansatz auf die Probe stellen
Um die Leistungsfähigkeit dieses Designs zu prüfen, trainierten und testeten die Autorinnen und Autoren es an einem großen, öffentlichen Erdrutsch‑Datensatz der Chinesischen Akademie der Wissenschaften. Die Sammlung umfasst mehr als zwanzigtausend Bilder von Satelliten und Drohnen und deckt viele Regionen, Geländeformen und Bildgebungsbedingungen ab. Das neue Modell wurde mit starken Konkurrenten verglichen, von klassischen U‑Net‑ und DeepLab‑Netzen bis zu modernen Transformer‑Systemen wie Swin Transformer und einem jüngeren leichten Erdrutschdetektor namens BisDeNet. Über eine Reihe gängiger Kennzahlen — Präzision, Recall, F1‑Score, Intersection‑over‑Union und Gesamtnachaccuracy — schnitt der mehrschichtige Pyramidensampling‑Transformer durchweg am besten ab und steigerte den F1‑Score um 7,3 Prozentpunkte und die Gesamtnachaccuracy um 2 Prozentpunkte gegenüber führenden Alternativen.
Von Zahlen zu realen Landschaften
Über rohe Kennzahlen hinaus untersuchten die Forschenden die Vorhersagen des Modells visuell. Sie stellten fest, dass es dazu neigt, sich auf Brüche im Hang, langgestreckte Narben und gemischte Oberflächentexturen zu konzentrieren, die typisch für Erdrutschbahnen sind. Fehlklassifikationen treten hauptsächlich dort auf, wo die Bilddaten selbst mehrdeutig sind — etwa an Flussufern, freiliegender Erde oder winzigen Rutschen mit schwachen Konturen — und weniger durch offensichtliche systematische Fehler des Modells. Tests an mehreren zusätzlichen Datensätzen aus Regionen wie Nepal, Bijie und Tangjiashan zeigen, dass die Methode sich verhältnismäßig gut an unterschiedliche Landschaften anpasst, was darauf hindeutet, dass sie allgemeine Merkmale von Erdrutschen erfasst und nicht nur Besonderheiten einer einzelnen Region.
Was das für sicherere Hänge bedeutet
Vereinfacht gesagt zeigt das Papier, wie man eine leistungsfähige KI‑Klasse dazu bringt, Hänge effizienter und klüger «anzuschauen». Indem das Modell Informationen auf mehreren Skalen innerhalb seines Kern‑Aufmerksamkeitsmechanismus sammelt, reduziert es die Rechenlast und bewahrt gleichzeitig das große Ganze sowie die feinen Details, die nötig sind, um Erdrutsche präzise abzugrenzen. Das Ergebnis ist ein schnelleres, genaueres Werkzeug, um Ströme von Satelliten‑ und Drohnenbildern in Karten instabiler Böden zu verwandeln. Solche Karten können Schadensbewertungen nach Katastrophen, langfristiges Gefährdungsmonitoring und Veränderungserkennung unterstützen und Planern sowie Einsatzkräften ein klareres Bild davon geben, wo sich die Erde bereits bewegt hat — und wo sie sich als nächstes bewegen könnte.
Zitation: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Schlüsselwörter: Erdrutscherkennung, Fernerkundung, Vision Transformers, Pyramidensampling, semantische Segmentierung